15 项目 4 - 开发图像过滤器
在本章中,我们将创建一个新项目。该项目的目标是编写一个程序,对图像应用滤镜。更具体地说,是一个“灰度滤镜”,它可以将任何彩色图像转换为灰度图像。
我们将在本项目中使用图 15.1中显示的图像。换句话说,我们想使用用 Zig 编写的“图像过滤程序”将彩色图像转换为灰度图像。

图 15.1:智利裔美国演员佩德罗·帕斯卡 (Pedro Pascal) 的照片。来源:Google 图片。
我们不需要编写大量代码来构建这样的“图像滤镜程序”。但是,我们首先需要了解数字图像的工作原理。因此,本章首先会解释数字图像背后的理论以及现代计算机中颜色的表示方式。我们还会简要介绍 PNG(便携式网络图形)文件格式,这是示例图像中使用的格式。
在本章结束时,我们应该会得到一个完整的程序示例,该程序以图 15.1中显示的 PNG 图像作为输入,并将一张该输入图像的灰度版本的新图像写入当前工作目录。图 15.1 的灰度版本如图15.2 所示。 您可以在ZigExamples/image_filter 本书官方仓库的文件夹中找到这个小项目的完整源代码。

图 15.2:照片的灰度版本。
15.1我们如何看待事物?
在本节中,我想简要地向大家描述一下我们(人类)究竟是如何用眼睛看东西的。我的意思是,我们的眼睛是如何工作的?如果你对眼睛的工作原理有基本的了解,你就能更容易地理解数字图像是如何生成的。因为数字图像背后的技术,很大程度上是从人眼工作原理中汲取灵感而发展起来的。
你可以把人眼理解为一个光传感器,或者说一个光接收器。眼睛接收一定量的光作为输入,并解读这些“光量”中的颜色。如果没有任何光量进入眼睛,眼睛就无法从中提取颜色,结果就是我们什么也看不见,或者更准确地说,我们看到的是一片漆黑。
因此,一切都取决于光。我们实际看到的是光线反射后的颜色(蓝色、红色、橙色、绿色、紫色、黄色等等)。**光是所有颜色的源泉!**这正是艾萨克·牛顿在17世纪60年代著名的棱镜实验2中发现的。
我们的眼睛里有一种特殊的细胞,叫做“视锥细胞”。我们的眼睛有三种不同的类型,或者说,三种不同版本的“视锥细胞”。每种视锥细胞对特定光谱的光线非常敏感。更具体地说,是对定义红、绿、蓝三种颜色的光谱。总而言之,我们的眼睛有对这三种颜色(红、绿、蓝)高度敏感的特定类型的细胞。
这些细胞负责感知进入我们眼睛的光线中的颜色。因此,我们的眼睛感知到的颜色是这三种颜色(红、绿、蓝)的混合。通过获取一定量的这三种颜色,并将它们混合在一起,我们就能得到任何我们想要的可见颜色。因此,我们看到的每一种颜色都被感知为蓝、绿、红的特定混合,例如 30% 的红色,加上 20% 的绿色,再加上 50% 的蓝色。
当这些视锥细胞感知到(或探测到)照射到我们眼睛的光线中的颜色时,它们会产生电信号,并传送到大脑。大脑会解读这些电信号,并利用它们形成我们脑海中看到的图像。
根据我们在此讨论的内容,下面的要点描述了构成我们人类眼睛工作原理的这个非常简化版本的事件顺序:
- 光线照射到我们的眼睛。
- 视锥细胞可以感知光中的颜色。
- 视锥细胞产生电信号来描述所感知到的光的颜色。
- 电信号被发送到大脑。
- 大脑解释这些信号,并根据这些电信号识别的颜色形成图像。
15.2数字图像如何工作?
数字图像是我们用眼睛看到的图像的“数字表示”。换句话说,数字图像是我们通过光线看到和感知到的颜色的“数字表示”。在数字世界中,我们有两种类型的图像:矢量图像和光栅图像。本文不介绍矢量图像。因此,请记住,本文讨论的内容仅与光栅图像相关,与矢量图像无关。
光栅图像是一种以二维像素矩阵表示的数字图像。换句话说,每个光栅图像本质上都是一个由像素组成的矩形,每个像素都有特定的颜色。因此,光栅图像只是一个由像素组成的矩形,每个像素都以一种颜色显示在计算机屏幕(或任何其他设备,例如笔记本电脑、平板电脑、智能手机等)上。
图 15.3演示了这个想法。如果你拍摄任何光栅图像,并将其放大到最大,你会看到图像的实际像素。JPEG、TIFF 和 PNG 是常用的存储光栅图像的文件格式。
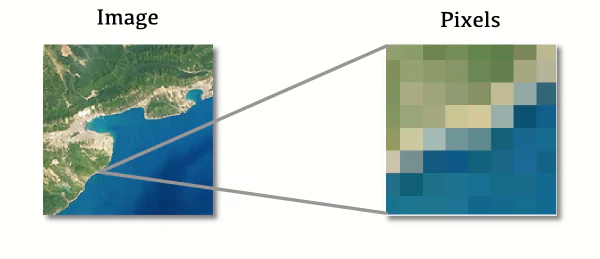
图 15.3:放大光栅图像以查看像素。来源:Google 图片。
图像像素越高,我们能包含的信息和细节就越多。图像看起来就越准确、清晰、美观。正因如此,相机通常会生成分辨率高达数百万像素的大型光栅图像,以便在最终图像中包含尽可能多的细节。例如,一张宽 1920 像素、高 1080 像素的数字图像,其包含的内容如下:1920×1080=2073600像素总数。您也可以说图像的“总面积”为 2073600 像素,尽管在计算机图形学中“面积”的概念实际上并不使用。
我们在现代世界中看到的大多数数字图像都使用 RGB 颜色模型。RGB 代表(红色、绿色和蓝色)。因此,这些光栅图像中每个像素的颜色通常表示为红色、绿色和蓝色的混合,就像我们的眼睛一样。也就是说,每个像素的颜色由一组三个不同的整数值标识。每个整数值标识每种颜色(红色、绿色和蓝色)的“数量”。例如,该集合(199, 78, 70)标识一种更接近红色的颜色。我们有 199 个红色、78 个绿色和 70 个蓝色。相反,该集合(129, 77, 250)描述的颜色更接近紫色。等等。
15.2.1图像从上到下显示
这并非一成不变的规则,但绝大多数数字图像都是从上到下、从左到右显示的。大多数电脑屏幕也遵循这种模式。因此,图像中的第一个像素位于图像的左上角。您可以在图 15.4中找到此逻辑的直观表示。
还要注意,在图 15.4中,由于光栅图像本质上是一个二维像素矩阵,因此图像被组织成像素的行和列。列由水平 x 轴定义,而行由垂直 y 轴定义。
图 15.4中显示的每个像素(即灰色矩形)内部都包含一个数字。这些数字是像素的索引。您可以注意到,第一个像素位于左上角,并且这些像素的索引“向两侧生长”,或者换句话说,它们沿着水平 x 轴方向生长。大多数光栅图像都是以像素行的形式组织的。因此,当显示这些数字图像时,屏幕会显示第一行像素,然后是第二行,然后是第三行,依此类推。

图 15.4:光栅图像的像素如何显示。
15.2.2用代码表示像素矩阵
好的,我们已经知道光栅图像表示为像素的二维矩阵。但是在 Zig 中我们没有二维矩阵的概念。实际上,大多数低级语言(Zig、C、Rust 等)都没有这样的概念。那么,我们如何在 Zig 或任何其他低级语言中表示这样的像素矩阵呢?在这种情况下,大多数程序员选择的策略是仅使用普通的一维数组来存储这个二维矩阵的值。换句话说,你只需创建一个普通的一维数组,并将两个维度的所有值存储到这个一维数组中。
举个例子,假设我们有一张尺寸为 4x3 的非常小的图像。由于光栅图像表示为二维像素矩阵,每个像素由 3 个“无符号 8 位”整数值表示,因此该图像总共有 12 个像素,分别表示为3×12=三十六整数值。因此,我们需要创建一个包含 36 个u8值的数组来存储这个小图像。
之所以u8使用无符号 8 位整数 ( ) 值(而不是任何其他整数类型)来表示每种颜色的量,是因为它们占用尽可能少的空间,或者说,占用尽可能少的位数。这有助于减小图像的二进制大小,即二维矩阵的大小。此外,即使它们只能表示相对较小范围(从 0 到 255)的“颜色量”,它们也能传达出相当高的色彩精度和细节。
回到我们最初的 4x3 图像示例,matrix下面显示的对象可以是存储表示此 4x3 图像的数据的 1D 数组的示例。
const matrix = [_]u8{
201, 10, 25, 185, 65, 70,
65, 120, 110, 65, 120, 117,
98, 95, 12, 213, 26, 88,
143, 112, 65, 97, 99, 205,
234, 105, 56, 43, 44, 216,
45, 59, 243, 211, 209, 54,
};
该数组的前三个整数值表示图像中第一个像素的颜色量。接下来的三个整数表示第二个像素的颜色量。依此类推。因此,存储光栅图像的数组大小通常是 3 的倍数。在本例中,数组的大小为 36。
我的意思是,数组的大小通常是3 的倍数,因为在特定情况下,它也可以是 4 的倍数。当光栅图像中也包含透明度时,就会发生这种情况。换句话说,有些类型的光栅图像使用不同的颜色模型,即 RGBA(红、绿、蓝和 Alpha)颜色模型。“Alpha”对应于像素的透明度。因此,RGBA 图像中的每个像素都由红、绿、蓝和 Alpha 值表示。
大多数光栅图像使用标准 RGB 模型,因此,在大多数情况下,您会看到数组大小是 3 的倍数。但有些图像(尤其是存储在 PNG 文件中的图像)可能使用 RGBA 模型,因此,由大小为 4 的倍数的数组表示。
在本例中,我们项目的示例图像(图 15.1)是存储在 PNG 文件中的光栅图像,并且该特定图像使用 RGBA 颜色模型。因此,图像中的每个像素都由 4 个不同的整数值表示,因此,为了将此图像存储在我们的 Zig 代码中,我们需要创建一个大小为 4 的倍数的数组。
15.3我们将要使用的 PNG 库
让我们从编写必要的 Zig 代码来读取 PNG 文件中的数据开始我们的项目。换句话说,我们要读取图 15.1中显示的 PNG 文件,并解析其数据以提取表示图像的二维像素矩阵。
正如我们在15.2.2 节中讨论过的,我们在此用作示例的图像是一个使用 RGBA 颜色模型的 PNG 文件,因此,图像的每个像素由 4 个整数值表示。您可以通过访问ZigExamples/image_filter 本书官方仓库3中的文件夹下载此图像。您还可以在此文件夹中找到我们正在开发的这个小项目的完整源代码。
有一些 C 库可以用来读取和解析 PNG 文件。其中最著名、最常用的是libpng,它是读取和写入 PNG 文件的“官方库”。虽然这个库在大多数操作系统上都可用,但它以复杂且难以使用而闻名。
这就是为什么我将在这个项目中使用一个更现代的替代方案,即libspng库。我选择使用这个 C 库,因为它比 更易于使用libpng,并且所有操作都具有非常出色的性能。您可以访问库4的官方网站了解更多信息。您还可以在那里找到一些文档,它们可能有助于您理解和遵循此处提供的代码示例。
首先,请记住将其构建并安装libspng到您的系统中。因为如果您不执行此步骤,编译器将无法在您的计算机中找到此库的文件和资源,并将它们与我们在此共同编写的 Zig 源代码链接起来。库文档5zig的构建部分提供了有关如何构建和安装该库的详细说明。
15.4读取PNG文件
为了从 PNG 文件中提取像素数据,我们需要读取并解码该文件。PNG 文件只是以“PNG 格式”写入的二进制文件。幸运的是,该libspng库提供了一个名为 的函数spng_decode_image(),可以为我们完成所有这些繁重的工作。
现在,由于libspng这是一个 C 库,库中的大部分文件和 I/O 操作都是通过FILEC 指针进行的。因此,使用fopen()C 函数打开 PNG 文件可能比使用openFile()我在第 13 章中介绍的方法更好。这就是为什么我stdio.h在这个项目中导入了 C 头文件,并使用fopen()C 函数打开文件。
如果你看一下下面的代码片段,你就会发现我们是:
- 使用 打开 PNG 文件
fopen()。 - 创建
libspng上下文spng_ctx_new()。 - 用于
spng_set_png_file()指定FILE读取我们将要使用的 PNG 文件的对象。
中的每个操作libspng都是通过“上下文对象”进行的。在下面的代码片段中,这个对象是ctx。此外,要对 PNG 文件执行操作,我们需要指定要引用的具体 PNG 文件。这就是 的工作spng_set_png_file()。我们使用此函数来指定读取我们要使用的 PNG 文件的文件描述符对象。
const c = @cImport({
@cDefine("_NO_CRT_STDIO_INLINE", "1");
@cInclude("stdio.h");
@cInclude("spng.h");
});
const path = "pedro_pascal.png";
const file_descriptor = c.fopen(path, "rb");
if (file_descriptor == null) {
@panic("Could not open file!");
}
const ctx = c.spng_ctx_new(0) orelse unreachable;
_ = c.spng_set_png_file(
ctx, @ptrCast(file_descriptor)
);
在继续之前,需要强调的是:由于我们已经使用 打开了文件fopen(),因此我们必须记住在程序结束时使用 关闭文件fclose()。换句话说,在对 PNG 文件执行完所有操作后,我们需要通过应用文件描述符对象pedro_pascal.png来关闭该文件。如果需要,我们也可以使用 关键字来完成这项任务。下面的代码片段演示了这一步骤:fclose()``defer
if (c.fclose(file_descriptor) != 0) {
return error.CouldNotCloseFileDescriptor;
}
15.4.1读取图像头部分
现在,上下文对象ctx已经知道了我们的 PNG 文件pedro_pascal.png,因为它可以访问该文件的文件描述符对象。我们要做的第一件事是读取 PNG 文件的“图像头部分”。这个“图像头部分”包含 PNG 文件的一些基本信息,例如,图像像素数据的位深度、文件使用的颜色模型、图像的尺寸(以像素数表示的高度和宽度)等等。
为了简化操作,我将把这个“读取图像头”操作封装成一个名为 的小巧函数get_image_header()。该函数只需调用 即可spng_get_ihdr()。该函数libspng负责读取图像头数据,并将其存储到名为 的 C 结构体中spng_ihdr。因此, 类型的对象spng_ihdr是一个 C 结构体,它包含 PNG 文件图像头部分的数据。
由于此 Zig 函数接收 C 对象(libspng上下文对象)作为输入,因此我将函数参数标记ctx为“指向上下文对象的指针”( ),遵循我们在第 14.5 节*c.spng_ctx中讨论的建议。
fn get_image_header(ctx: *c.spng_ctx) !c.spng_ihdr {
var image_header: c.spng_ihdr = undefined;
if (c.spng_get_ihdr(ctx, &image_header) != 0) {
return error.CouldNotGetImageHeader;
}
return image_header;
}
var image_header = try get_image_header(ctx);
还要注意,在这个函数中,我检查了spng_get_ihdr()函数调用是否返回了一个非零的整数值。libspng库中的大多数函数都会返回一个代码状态,而代码状态“零”表示“成功”。因此,任何非零的代码状态都表示运行时发生了错误spng_get_ihdr()。这就是为什么我会在函数返回的代码状态非零时返回一个错误值。
15.4.2为像素数据分配空间
在从 PNG 文件中读取像素数据之前,我们需要分配足够的空间来保存这些数据。但为了分配这样的空间,我们首先需要知道需要分配多少空间。显然,需要图像的尺寸来计算这个空间的大小。但还有其他因素也会影响这个数字,例如图像中使用的颜色模型、位深度等等。
无论如何,所有这些都意味着计算我们所需的空间大小并非易事。因此,libspng库提供了一个名为 的工具函数spng_decoded_image_size()来帮助我们计算这个大小。再次强调,我将把这个 C 函数的逻辑封装成一个简洁精巧的 Zig 函数,名为calc_output_size()。您可以在下面看到,该函数返回一个整数值作为结果,告知我们需要分配的空间大小。
fn calc_output_size(ctx: *c.spng_ctx) !u64 {
var output_size: u64 = 0;
const status = c.spng_decoded_image_size(
ctx, c.SPNG_FMT_RGBA8, &output_size
);
if (status != 0) {
return error.CouldNotCalcOutputSize;
}
return output_size;
}
你可能会好奇这个值SPNG_FMT_RGBA8的含义。这个值实际上是spng.hC 头文件中定义的一个枚举值。这个枚举值用于标识一种“PNG 格式”。更准确地说,它标识一个使用 RGBA 颜色模型和 8 位深度的 PNG 文件。因此,通过将此枚举值作为函数的输入spng_decoded_image_size(),我们告诉该函数,以遵循“8 位深度的 RGBA 颜色模型”格式的 PNG 文件为例,计算解码后像素数据的大小。
有了这个函数,我们可以将它与分配器对象结合使用,分配一个u8足够大的字节数组(值),用于存储图像解码后的像素数据。注意,我使用这个函数@memset()将整个数组初始化为零。
const output_size = try calc_output_size(ctx);
var buffer = try allocator.alloc(u8, output_size);
@memset(buffer[0..], 0);
15.4.3解码图像数据
现在我们有了存储图像解码像素数据所需的空间,我们可以开始使用spng_decode_image()C 函数实际解码并从图像中提取像素数据。
下面展示的 Zig函数read_data_to_buffer()总结了读取解码像素数据并将其存储到输入缓冲区的必要步骤。请注意,此函数封装了函数本身的逻辑spng_decode_image()。此外,我们再次使用SPNG_FMT_RGBA8枚举值来告知相应的函数,正在解码的 PNG 图像使用 RGBA 颜色模型和 8 位深度。
fn read_data_to_buffer(ctx: *c.spng_ctx, buffer: []u8) !void {
const status = c.spng_decode_image(
ctx,
buffer.ptr,
buffer.len,
c.SPNG_FMT_RGBA8,
0
);
if (status != 0) {
return error.CouldNotDecodeImage;
}
}
有了这个函数,我们可以将它应用于我们的上下文对象,也可以应用于我们在上一节中分配的缓冲区对象,以保存图像的解码像素数据:
try read_data_to_buffer(ctx, buffer[0..]);
15.4.4查看像素数据
现在我们已经将像素数据存储在“缓冲区对象”中,我们可以快速查看一下这些字节。在下面的示例中,我们查看的是解码像素数据中的前 12 个字节。
如果仔细观察这些值,你可能会注意到序列中每 4 个字节都是 255。巧合的是,这正是一个值所能表示的最大整数值u8。因此,如果 0 到 255(也就是一个值所能表示的整数值范围)u8可以表示为 0% 到 100% 的比例,那么这 255 个值在这个比例下本质上就是 100%。
如果你还记得15.2.2 节的内容,我在那一节中提到过,我们的pedro_pascal.pngPNG 文件使用 RGBA 颜色模型,它会为图像中的每个像素添加一个 Alpha(透明度)字节。因此,图像中的每个像素都由 4 个字节表示。由于我们在这里查看的是图像的前 12 个字节,这意味着我们查看的是第一个12/4=3图像中的像素。
因此,根据前 12 个字节(或 3 个像素)的情况,以及每 4 个字节对应 255 个值,我们可以说图像中的每个像素很可能都将 Alpha 值(或透明度)设置为 100%。这或许并非事实,但却是最有可能的。此外,如果我们查看图像本身(如果您还记得的话,它显示在图 15.1中),我们可以看到整个图像的透明度并没有发生变化,这进一步证实了这一理论。
try stdout.print("{any}\n", .{buffer[0..12]});
{
200, 194, 216, 255, 203, 197,
219, 255, 206, 200, 223, 255
}
从上面的结果中我们可以看到,图像中的第一个像素有 200 个红色像素、194 个绿色像素和 216 个蓝色像素。我如何知道这些颜色在序列中的出现顺序呢?如果你还没猜到,那是因为 RGB 这个缩写。首先是红色,然后是绿色,最后是蓝色。如果我们按照 0% 到 100%(0 到 255)的比例缩放这些整数值,我们会得到 78% 的红色、76% 的绿色和 85% 的蓝色。
15.5应用图像滤镜
现在我们有了图像中每个像素的数据,我们可以专注于对这些像素应用图像滤镜了。记住,我们的目标是对图像应用灰度滤镜。灰度滤镜是一种将彩色图像转换为灰度图像的滤镜。
将彩色图像转换为灰度图像有多种公式和策略。但所有这些不同的策略通常都涉及对每个像素的颜色进行一些数学运算。在本项目中,我们将使用最通用的公式,如下所示。该公式考虑了r作为像素的红色,克作为绿色,b蓝色,页′作为像素的线性亮度。
(15.1)页′=(0.2126×r)+(0.7152×克)+(0.0722×b)
公式15.1是计算像素线性亮度的公式。值得注意的是,此公式仅适用于像素使用 sRGB 颜色空间(这是 Web 的标准颜色空间)的图像。因此,理想情况下,Web 上的所有图像都应使用此颜色空间。幸运的是,我们这里的情况就是这样,即图像使用的是 sRGB 颜色空间,因此 pedro_pascal.png,我们可以使用公式 15.1 。您可以在维基百科的灰度页面( Wikipedia 2024 )上阅读有关此公式的更多信息。
下面展示的函数总结了将公式 15.1应用于图像像素的apply_image_filter()必要步骤。我们只需将此函数应用于包含像素数据的缓冲区对象,结果,存储在此缓冲区对象中的像素数据现在应该代表图像的灰度版本。
fn apply_image_filter(buffer:[]u8) !void {
const len = buffer.len;
const red_factor: f16 = 0.2126;
const green_factor: f16 = 0.7152;
const blue_factor: f16 = 0.0722;
var index: u64 = 0;
while (index < len) : (index += 4) {
const rf: f16 = @floatFromInt(buffer[index]);
const gf: f16 = @floatFromInt(buffer[index + 1]);
const bf: f16 = @floatFromInt(buffer[index + 2]);
const y_linear: f16 = (
(rf * red_factor) + (gf * green_factor)
+ (bf * blue_factor)
);
buffer[index] = @intFromFloat(y_linear);
buffer[index + 1] = @intFromFloat(y_linear);
buffer[index + 2] = @intFromFloat(y_linear);
}
}
try apply_image_filter(buffer[0..]);
15.6保存图像的灰度版本
由于我们现在已将图像的灰度版本存储在缓冲区对象中,因此我们需要将此缓冲区对象重新编码为“PNG 格式”,并将编码数据保存到文件系统中的新 PNG 文件中,以便我们可以访问并查看由我们的小程序生成的图像的灰度版本。
为此,libspng库再次提供了一个“将数据编码为 PNG”类型的函数,即spng_encode_image()函数。但是,为了使用 函数“将数据编码为 PNG” libspng,我们需要创建一个新的上下文对象。这个新的上下文对象必须使用一个“编码器上下文”,该上下文由枚举值 标识SPNG_CTX_ENCODER。
下面展示的函数save_png()总结了将图像的灰度版本保存到文件系统中新的 PNG 文件的所有必要步骤。默认情况下,此函数会将灰度图像保存到pedro_pascal_filter.pngCWD 中指定的文件中。
image_header请注意,在此代码示例中,我们使用了之前通过函数获取的图像头对象 ( ) get_image_header()。记住,这个图像头对象是一个 C 结构体 ( spng_ihdr),它包含 PNG 文件的基本信息,例如图像尺寸、使用的颜色模型等。
如果我们想在这个新的 PNG 文件中保存一个非常不同的图像,例如具有不同尺寸的图像,或者使用不同颜色模型、不同位深度等的图像,我们必须创建一个新的图像头(spng_ihdr)对象来描述这个新图像的属性。
但我们本质上保存的是与最初保存的图像相同的图像(图像尺寸、颜色模型等都保持不变)。两幅图像唯一的区别在于像素的颜色,现在变成了“灰度”。因此,我们可以安全地在这个新的 PNG 文件中使用完全相同的图像头数据。
fn save_png(image_header: *c.spng_ihdr, buffer: []u8) !void {
const path = "pedro_pascal_filter.png";
const file_descriptor = c.fopen(path.ptr, "wb");
if (file_descriptor == null) {
return error.CouldNotOpenFile;
}
const ctx = (
c.spng_ctx_new(c.SPNG_CTX_ENCODER)
orelse unreachable
);
defer c.spng_ctx_free(ctx);
_ = c.spng_set_png_file(ctx, @ptrCast(file_descriptor));
_ = c.spng_set_ihdr(ctx, image_header);
const encode_status = c.spng_encode_image(
ctx,
buffer.ptr,
buffer.len,
c.SPNG_FMT_PNG,
c.SPNG_ENCODE_FINALIZE
);
if (encode_status != 0) {
return error.CouldNotEncodeImage;
}
if (c.fclose(file_descriptor) != 0) {
return error.CouldNotCloseFileDescriptor;
}
}
try save_png(&image_header, buffer[0..]);
执行此save_png()函数后,我们的 CWD 中应该会有一个名为 的新 PNG 文件pedro_pascal_filter.png。打开这个 PNG 文件,我们将看到与图 15.2中相同的图像。
15.7构建我们的项目
现在我们已经编写了代码,让我们讨论一下如何构建/编译这个项目。为此,我将在项目的根目录中创建一个文件,并开始编写编译项目所需的代码,使用我们从第 9 章build.zig学到的知识。
我们首先为可执行文件创建构建目标,用于执行我们的 Zig 代码。假设我们所有的 Zig 代码都写入了一个名为 的 Zig 模块中image_filter.zig。exe下面构建脚本中公开的对象描述了我们可执行文件的构建目标。
由于我们在 Zig 代码中使用了libspng库中的一些 C 代码,因此我们需要将 Zig 代码(位于exe构建目标中)链接到 C 标准库和库libspng。我们通过调用构建目标中的linkLibC()和linkSystemLibrary()方法来实现这一点exe。
const std = @import("std");
pub fn build(b: *std.Build) void {
const target = b.standardTargetOptions(.{});
const optimize = b.standardOptimizeOption(.{});
const exe = b.addExecutable(.{
.name = "image_filter",
.root_source_file = b.path("src/image_filter.zig"),
.target = target,
.optimize = optimize,
});
exe.linkLibC();
// Link to libspng library:
exe.linkSystemLibrary("spng");
b.installArtifact(exe);
}
由于我们使用的是该方法,这意味着系统会搜索linkSystemLibrary()库文件并将其链接到构建目标。如果您尚未构建并安装该库到您的系统中,则此链接步骤可能无法正常工作。因为它无法在您的系统中找到库文件。libspng``exe``libspng
libspng所以,如果你想构建这个项目,只需记住在你的系统中安装即可。有了上面编写的构建脚本,我们最终可以通过zig build在终端中运行命令来构建我们的项目。
zig build