zig-book-cn
英文原版书籍链接: Introduction to Zig
github仓库链接: https://github.com/pedropark99/zig-book
请支持作者的项目.
About this book
This is an open (i.e., open-source), technical and introductory book for the Zig programming language, which is a new general purpose, and low-level programming language for building optimal and robust software.
Official repository of the book: https://github.com/pedropark99/zig-book.
This book is designed for both beginners and experienced developers. It explores the exciting world of Zig through small and simple projects (in a similar style to the famous "Python Crash Course" book from Eric Matthes). Some of these projects are: a Base64 encoder/decoder, a HTTP Server and an image filter.
As you work through the book, you will learn:
- The syntax of the language, and how it compares to C, C++ and Rust.
- Data structures, memory allocators, filesystem and I/O.
- Optionals as a new paradigm to handle nullability.
- How to test and debug a Zig application.
- Errors as values, and how to handle them.
- How to build C and Zig code with the build system that is embedded into the language.
- Zig interoperability with C.
- Parallelism with threads and SIMD.
- And more.
FAQ
- .{} 用法如何理解
正如我们在2.4 节中所述,当你在结构体字面量前面添加一个点时,zig编译器会自动推断该结构体字面量的类型。本质上,zig编译器会寻找一些关于该结构体类型的提示。这些提示可以是函数参数的类型注解,也可以是函数返回值的类型注解,或者是一个现有对象的类型注解。如果编译器找到了这样的类型注解,它就会在你的结构体字面量中使用它。
在 Zig 中,匿名结构体通常用作函数参数的输入。一个您经常看到的例子是print()来自stdout对象的函数。该函数接受两个参数。第一个参数是一个模板字符串,其中包含字符串格式说明符,用于指示如何将第二个参数中提供的值打印到消息中。
Zig 中的类型推断是使用点字符 ( .) 来完成的。每当您在结构体字面量、枚举值或类似符号前看到一个点字符时,您就知道这个点字符在这里起着特殊的作用。更具体地说,它告诉zig编译器类似这样的信息:“嘿!你能帮我推断一下这个值的类型吗?拜托!”。换句话说,这个点字符的作用类似于autoC++ 中的关键字。
其他zig资料
zig cookbook
https://republicroad.github.io/republic/lang/zig.html
1 Zig 简介
在本章中,我想向您介绍 Zig 的世界。Zig 是一种非常年轻的语言,目前正在积极开发中。因此,它的世界仍然充满未知,有待探索。本书旨在帮助您踏上理解和探索 Zig 精彩世界的个人旅程。
我假设你之前已经使用过本书中的某种编程语言,不一定是低级编程语言。所以,如果你有 Python 或 JavaScript 的经验,那就没问题。但是,如果你有 C、C++ 或 Rust 等低级语言的经验,那么你通过本书学习的速度可能会更快。
1.1什么是 Zig?
Zig 是一种现代、低级且通用的编程语言。一些程序员认为 Zig 是 C 语言的现代升级版。
在作者的个人理解中,Zig 与“少即是多”紧密相连。Zig 并非试图通过添加越来越多的功能来成为一门现代语言,而是带来了许多核心改进,实际上是为了移除 C 和 C++ 中令人讨厌的行为/功能。换句话说,Zig 试图通过简化语言,并使其行为更加一致和健壮来变得更好。因此,与 C 或 C++ 相比,在 Zig 中分析、编写和调试应用程序变得更容易、更简单。
Zig 官方网站的以下语句清楚地表明了这一理念:
“专注于调试您的应用程序而不是调试您的编程语言知识”。
这句话对于 C++ 程序员来说尤其适用。因为 C++ 是一门庞大的语言,拥有海量的特性,而且有很多不同的“C++ 风格”。正是这些因素使得 C++ 如此复杂,难以学习。Zig 则试图反其道而行之。Zig 是一种非常简单的语言,与 C 和 Go 等其他简单语言的关系更为密切。
上面这句话对 C 程序员来说仍然很重要。因为即使 C 语言本身很简单,阅读和理解 C 代码有时仍然很困难。例如,C 语言中的预处理器宏经常会让人感到困惑。有时,它们甚至会让调试 C 程序变得非常困难。因为宏本质上是嵌入在 C 语言中的第二种语言,它会掩盖你的 C 代码。使用宏,你不再能 100% 确定哪些代码片段会被发送到编译器,也就是说,它们会掩盖你编写的实际源代码。
Zig 中没有宏。在 Zig 中,你编写的代码是编译器编译的实际代码。你也没有在后台发生的隐藏控制流。而且,你也没有标准库中的函数或操作符在你背后进行隐藏的内存分配。
作为一种更简单的语言,Zig 变得更加清晰,更易于读写,但同时,它也达到了更加健壮的状态,在边缘情况下的行为更加一致。再一次,少即是多。
1.2 Zig 中的 Hello World
我们从创建一个小型的“Hello World”程序开始我们的 Zig 之旅。要在计算机上启动一个新的 Zig 项目,只需调用编译器init中的命令即可zig。只需在计算机上创建一个新目录,然后在该目录中初始化一个新的 Zig 项目,如下所示:
mkdir hello_world
cd hello_world
zig init
info: created build.zig
info: created build.zig.zon
info: created src/main.zig
info: created src/root.zig
info: see `zig build --help` for a menu of options
1.2.1了解项目文件
从编译器运行init命令后zig,当前目录中会创建一些新文件。首先,src创建一个“源”()目录,其中包含两个文件:main.zig和root.zig。每个.zig文件都是一个单独的 Zig 模块,它只是一个包含一些 Zig 代码的文本文件。
按照惯例,main.zig模块是你的主函数所在的位置。因此,如果你在 Zig 中构建一个可执行程序,你需要声明一个main()函数,它代表程序的入口点,即程序执行开始的地方。
但是,如果您要构建的是库(而不是可执行程序),那么通常的做法是删除此main.zig文件,然后从模块开始root.zig。按照惯例,root.zig模块是库的根源文件。
tree .
.
├── build.zig
├── build.zig.zon
└── src
├── main.zig
└── root.zig
1 directory, 4 files
该init命令还会在我们的工作目录中创建两个附加文件:build.zig和build.zig.zon。第一个文件(build.zig)表示用 Zig 编写的构建脚本。当您build从zig编译器调用该命令时,将执行此脚本。换句话说,此文件包含执行构建整个项目所需步骤的 Zig 代码。
低级语言通常使用编译器将源代码构建为二进制可执行文件或二进制库。然而,随着项目规模越来越大,编译源代码并构建二进制可执行文件或二进制库的过程在编程世界中成为了一项真正的挑战。因此,程序员创建了“构建系统”,这是旨在简化编译和构建复杂项目过程的第二套工具。
构建系统的示例包括 CMake、GNU Make、GNU Autoconf 和 Ninja,它们用于构建复杂的 C 和 C++ 项目。使用这些系统,您可以编写脚本,这些脚本称为“构建脚本”。它们只是描述了编译/构建项目所需步骤的脚本。
然而,这些都是独立的工具,不属于 C/C++ 编译器,例如gcc或clang。因此,在 C/C++ 项目中,您不仅需要安装和管理 C/C++ 编译器,还需要单独安装和管理这些构建系统。
在 Zig 中,我们无需使用单独的工具来构建项目,因为语言本身就嵌入了构建系统。我们可以使用此构建系统在 Zig 中编写小脚本,这些脚本描述了构建/编译 Zig 项目1 的必要步骤。因此,构建一个复杂的 Zig 项目所需的只是zig编译器,仅此而已。
第二个生成的文件(build.zig.zon)是一个类似 JSON 的文件,您可以在其中描述您的项目,并声明一组您想要从互联网获取的项目依赖项。换句话说,您可以使用此build.zig.zon文件在项目中引入外部库列表。
在您的项目中包含外部 Zig 库的一种可能方法是在您的系统中手动构建和安装该库,然后在您的项目的构建步骤中将您的源代码与该库链接起来。
但是,如果这个外部 Zig 库在 GitHub 上可用,并且它build.zig.zon在项目的根文件夹中有一个描述项目的有效文件,那么您只需在build.zig.zon文件中列出这个外部库,就可以轻松地将该库包含在您的项目中。
换句话说,此build.zig.zon文件的工作方式与package.jsonJavascript 项目中的文件、PipfilePython 项目中的文件或Cargo.tomlRust 项目中的文件类似。您可以在互联网上的几篇文章中阅读有关此特定文件的更多信息2 3 ,也可以在 Zig 4build.zig.zon官方存储库中的文档文件中查看此文件的预期模式。
1.2.2文件root.zig
让我们看一下这个root.zig文件。你可能注意到,每行带有表达式的代码都以分号 ( ;) 结尾。这遵循了 C 语言家族的语法5。
另外,请注意@import()第一行的调用。我们使用这个内置函数将其他 Zig 模块的功能导入到当前模块中。此@import()函数的工作原理类似于#includeC 或 C++ 中的预处理器,或者importPython 或 JavaScript 代码中的语句。在此示例中,我们导入了std模块,这使您可以访问 Zig 标准库。
在此root.zig文件中,我们还可以看到如何在 Zig 中进行赋值(即创建新对象)。您可以使用语法在 Zig 中创建新对象(const|var) name = value;。在下面的示例中,我们创建了两个常量对象(std和testing)。在第 1.4 节中,我们将更详细地讨论一般对象。
const std = @import("std");
const testing = std.testing;
export fn add(a: i32, b: i32) i32 {
return a + b;
}
Zig 中的函数使用关键字声明fn。在此root.zig模块中,我们声明了一个名为的函数add(),它有两个名为a和 的参数b。该函数返回一个 类型的整数i32作为结果。
Zig 是一种强类型语言。在某些特定情况下,如果编译器可以推断出对象的类型(我们将在2.4 节zig中详细讨论),您可以(如果愿意)在代码中省略对象的类型。但在其他情况下,您确实需要明确指定。例如,您必须明确指定每个函数参数的类型,以及在 Zig 中创建的每个函数的返回类型。
在 Zig 中,我们使用冒号 ( :) 来指定对象或函数参数的类型,后跟该对象/函数参数名称后的类型。通过表达式a: i32和,我们知道和参数的类型b: i32都是,它是一个有符号的 32 位整数。在这一部分中,Zig 中的语法与 Rust 中的语法相同,后者也使用冒号字符来指定类型。a``b``i32
最后,在打开花括号开始编写函数主体之前,我们在行尾给出了函数的返回类型。在上面的例子中,此类型也是一个有符号的 32 位整数(i32)。
请注意,函数声明前还有一个export关键字。此关键字类似于externC 语言中的关键字。它暴露函数,使其在库 API 中可用。因此,如果您正在编写一个供其他人使用的库,则必须使用此关键字将您编写的函数暴露在该库的公共 API 中。如果我们从函数声明中export删除该关键字,那么该函数将不再在编译器构建的库对象中暴露。export``add()``zig
1.2.3文件main.zig
现在我们已经从文件中了解了很多关于 Zig 语法的知识root.zig,让我们来看看这个main.zig文件。我们在 中看到的很多元素root.zig也出现在 中main.zig。但是还有一些我们还没有看到的元素,所以让我们深入了解一下。
首先,查看此文件中函数的返回类型main()。我们可以看到一个细微的变化。函数的返回类型(void)后面跟着一个感叹号(!)。这个感叹号告诉我们,该main()函数可能返回错误。
值得注意的是,main()Zig 中的函数可以返回任何内容(void),或者返回一个无符号的 8 位整数(u8)值6,或者返回一个错误。换句话说,您可以main()在 Zig 中编写函数使其基本上不返回任何内容(void),或者,如果您愿意,也可以编写一个更像 C 语言的main()函数,它返回一个通常用作进程“状态代码”的整数值。
在此示例中,返回类型注释main()表示此函数可以不返回任何内容(void),也可以返回错误。返回类型注释中的感叹号是 Zig 一个有趣且强大的功能。总而言之,如果您编写了一个函数,并且该函数主体内部的某些内容可能会返回错误,那么您就必须:
- 要么在函数的返回类型中添加感叹号,并明确表示该函数可能会返回错误。
- 在函数内部明确处理此错误。
_在大多数编程语言中,我们通常通过try catch_模式来处理错误。Zig 确实同时包含try和catch关键字。但它们的工作方式可能与你在其他语言中习惯的方式略有不同。
如果我们查看main()下面的函数,您会发现第五行确实有一个关键字。但是这段代码中try没有关键字。在 Zig 中,我们使用关键字来执行可能返回错误的表达式,在本例中,该表达式就是该表达式。catch``try``stdout.print()
本质上,try关键字 执行表达式stdout.print()。如果此表达式返回有效值,则try关键字什么也不做,只是将值传递下去,就像这个关键字从未存在过一样try。但是,如果表达式返回错误,则try关键字将解包错误值,然后从函数中返回此错误,并将当前堆栈跟踪打印到stderr。
如果你之前学过高级语言,这可能听起来很奇怪。因为在高级语言(例如 Python)中,如果某个地方发生错误,这个错误会自动返回,即使你不想停止程序的执行,程序的执行也会自动停止。你必须面对这个错误。
const std = @import("std");
pub fn main() !void {
const stdout = std.io.getStdOut().writer();
try stdout.print("Hello, {s}!\n", .{"world"});
}
您可能还注意到,此代码示例中的main()函数使用了pub关键字 。它将该main()函数标记为此模块的_公共函数_。默认情况下,Zig 模块中的每个函数都是此 Zig 模块的私有函数,并且只能在模块内部调用。除非您使用关键字 明确将此函数标记为公共函数pub。
仔细想想,Zig 中的这个关键字的作用与 C/C++ 中的关键字作用pub本质上相反。通过将函数设置为“public”,您可以允许其他 Zig 模块访问和调用该函数。调用方 Zig 模块使用内置函数导入另一个模块,这使得被导入模块的所有公共函数对调用方 Zig 模块可见。static``@import()
1.2.4编译源代码
build-exe您可以通过运行编译器中的命令将 Zig 模块编译为二进制可执行文件zig。只需在命令后列出所有要构建的 Zig 模块build-exe,并用空格分隔即可。在下面的示例中,我们正在编译模块main.zig。
zig build-exe src/main.zig
由于我们正在构建一个可执行文件,编译器会在命令后列出的任何文件中zig查找声明的函数。如果编译器在某个地方找不到声明的函数,则会引发编译错误,警告此错误。main()``build-exe``main()
编译zig器还提供了build-lib和build-obj命令,其工作方式与 命令完全相同build-exe。唯一的区别是,它们分别将 Zig 模块编译为可移植的 C ABI 库或目标文件。
就该命令而言build-exe,编译器会在项目的根目录中创建一个二进制可执行文件zig。如果我们现在使用一个简单的命令查看当前目录的内容,ls就可以看到main编译器创建的二进制文件。
ls
build.zig build.zig.zon main src
如果我执行这个二进制可执行文件,我会在终端中收到“Hello World”消息,正如我们所期望的。
./main
Hello, world!
1.2.5同时编译和执行
在上一节中,我介绍了zig build-exe将 Zig 模块编译为可执行文件的命令。然而,这意味着,为了执行该可执行文件,我们必须运行两个不同的命令。首先运行该zig build-exe命令,然后调用编译器创建的可执行文件。
但是如果我们想在一个命令中同时执行这两个步骤怎么办?我们可以通过使用zig run命令来实现。
zig run src/main.zig
Hello, world!
1.2.6 Windows 用户重要提示
首先,这是 Windows 特有的,因此不适用于其他操作系统,例如 Linux 和 macOS。总之,如果您有一段 Zig 代码,其中包含一些全局变量,这些变量的初始化依赖于运行时资源,那么在 Windows 上尝试编译这段 Zig 代码时可能会遇到一些麻烦。
一个例子是访问stdout(即系统的_标准输出_std.io.getStdOut()),这通常在 Zig 中使用表达式来完成。如果使用此表达式在 Zig 模块中实例化全局变量,那么 Zig 代码的编译很可能会在 Windows 上失败,并出现“无法评估 comptime 表达式”的错误消息。
编译过程中出现这种失败是因为Zig中的所有全局变量都是在_编译时_初始化的。然而,在Windows上,访问(或打开文件)之类的操作依赖于仅在_运行_stdout时可用的资源(您将在第3.1.1节中了解有关编译时与运行时的更多信息)。
例如,如果您尝试在 Windows 上编译此代码示例,则可能会收到下面显示的错误消息:
const std = @import("std");
// ERROR! Compile-time error that emerges from
// this next line, on the `stdout` object
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
_ = try stdout.write("Hello\n");
}
t.zig:2107:28: error: unable to evaluate comptime expression
break :blk asm {
^~~
为了避免在 Windows 上出现此问题,我们需要强制zig编译器仅在运行时实例化此stdout对象,而不是在编译时实例化它。我们可以通过简单地将表达式移到函数体中来实现这一点。
这解决了问题,因为Zig中函数体内部的所有表达式都只在运行时求值,除非你comptime显式使用关键字来改变这种行为。你将在第12.1节comptime中了解有关此关键字的更多信息。
const std = @import("std");
pub fn main() !void {
// SUCCESS: Stdout initialized at runtime.
const stdout = std.io.getStdOut().writer();
_ = try stdout.write("Hello\n");
}
Hello
您可以在官方 Zig 存储库中打开的几个 GitHub 问题中阅读有关此 Windows 特定限制的更多详细信息。更具体地说,是问题 17186 7和 19864 8。
1.2.7编译整个项目
正如我在第 1.2.1 节中所描述的,随着项目规模和复杂性的增长,我们通常更喜欢使用某种“构建系统”将项目的编译和构建过程组织成构建脚本。
换句话说,随着项目规模和复杂度的增长,build-exe、build-lib和build-obj命令变得越来越难以直接使用。因为那时,我们开始同时列出多个模块。我们还开始添加内置编译标志来根据需求定制构建过程等等。手动编写必要的命令变得非常繁琐。
在 C/C++ 项目中,程序员通常选择使用 CMake、NinjaMakefile或configure脚本来组织此过程。然而,在 Zig 中,我们拥有语言本身的原生构建系统。因此,我们可以在 Zig 中编写构建脚本来编译和构建 Zig 项目。然后,我们需要做的就是调用命令zig build来构建我们的项目。
因此,当你执行该zig build命令时,编译器将在当前目录中zig搜索名为 Zig 的模块,该模块应该是你的构建脚本,其中包含编译和构建项目所需的代码。如果编译器在你的目录中找到了这个文件,那么它实际上会在这个文件上执行一个命令,编译并执行这个构建脚本,进而编译并构建你的整个项目。build.zig``build.zig``zig run``build.zig
zig build
执行此“build project”命令后,zig-out将在项目目录的根目录中创建一个目录,您可以在其中找到根据您在中指定的构建命令从 Zig 模块创建的二进制可执行文件和库build.zig。我们将在本书后面详细讨论 Zig 中的构建系统。
在下面的示例中,我正在执行hello_world编译器在命令后生成的名为的二进制可执行文件zig build。
./zig-out/bin/hello_world
Hello, world!
1.3如何学习Zig?
学习 Zig 的最佳策略是什么?首先,这本书当然会在你学习 Zig 的过程中提供很大帮助。但如果你想真正精通 Zig,你还需要一些额外的资源。
作为第一个提示,您可以加入 Zig 程序员社区,以便在需要时获得一些帮助:
- Reddit 论坛:https://www.reddit.com/r/Zig/;
- Ziggit 社区:https://ziggit.dev/;
- Discord、Slack、Telegram 等:https://github.com/ziglang/zig/wiki/Community;
现在,学习 Zig 的最佳方法之一就是阅读 Zig 代码。尝试经常阅读 Zig 代码,事情就会变得更加清晰。AC/C++ 程序员可能也会给你同样的建议。因为这个策略真的有效!
那么,在哪里可以找到 Zig 代码来阅读呢?我个人认为,阅读 Zig 代码的最佳方法是阅读 Zig 标准库的源代码。Zig 标准库位于Zig 官方 GitHub 仓库的第 9 个lib/std文件夹下。访问此文件夹,即可开始探索 Zig 模块。
另外,一个很好的选择是从其他大型 Zig 代码库中读取代码,例如:
- Javascript 运行时Bun 10。
- 游戏引擎Mach 11。
- Zig 12中的LLama 2 LLM 模型实现。
- 金融交易
tigerbeetle数据库13 . - 命令行参数解析器
zig-clap14。 - UI
capy框架15 . - Zig 的语言协议实现,
zls16。 - 事件循环库
libxev17。
所有这些资源都可以在 GitHub 上找到,这很棒,因为我们可以利用 GitHub 的搜索栏来查找符合我们描述的 Zig 代码。例如,lang:Zig当您搜索特定模式时,您可以随时在 GitHub 的搜索栏中输入。这将把搜索范围限制在 Zig 模块上。
另外,一个很好的选择是查阅在线资源和文档。以下是我个人经常使用的资源列表,用于每天学习这门语言:
- Zig 语言参考:https://ziglang.org/documentation/master/;
- Zig 标准库参考:https://ziglang.org/documentation/master/std/;
- Zig 指南:https://zig.guide/;
- Karl Seguin博客:https://www.openmymind.net/;
- Zig 新闻:https://zig.news/;
- 阅读 Zig 核心团队成员之一编写的代码:https://github.com/kubkon;
- 一些现场编码会议在 Zig Showtime Youtube 频道上播出:https://www.youtube.com/@ZigSHOWTIME/videos;
学习 Zig,或者坦白说,学习任何你想学的语言,另一个好策略就是通过做练习来练习。例如,Zig 社区里有一个著名的代码库,叫做Ziglings 18,里面有 100 多个你可以解决的小练习。这个代码库里存放着用 Zig 编写的、目前有问题的小程序,你的责任就是修复这些程序,让它们重新运行。
一位名为 The Primeagen 的著名科技 YouTuber也在 YouTube 上发布了一些视频,其中他解答了 Ziglings 的这些练习。第一个视频名为“尝试 Zig 第一部分” 19。
另一个不错的选择是解决《代码降临》练习20。有些人已经花时间学习和解决了这些练习,并且他们也把解决方案发布在了 GitHub 上。所以,如果你在解决练习时需要一些资源来比较,可以看看这两个仓库:
1.4在Zig中创建新对象(即标识符)
让我们进一步讨论一下 Zig 中的对象。曾经使用过其他编程语言的读者可能会通过不同的名称来了解这个概念,例如“变量”或“标识符”。在本书中,我选择使用“对象”一词来指代这个概念。
要在 Zig 中创建新对象(或新的“标识符”),我们使用关键字const或var。这些关键字指定要创建的对象是否可变。如果使用const,则创建的对象是常量(或不可变)对象,这意味着一旦声明了此对象,就不能再更改存储在此对象中的值。
另一方面,如果使用var,则表示您正在创建一个变量(或可变)对象。您可以根据需要多次更改此对象的值。在 Zig 中使用 关键字与在 Rust 中var使用 关键字类似。let mut
1.4.1常量对象与变量对象
在下面的代码示例中,我们创建了一个名为 的新常量对象age。该对象存储一个表示某人年龄的数字。然而,此代码示例无法成功编译。因为在下一行代码中,我们尝试将对象的值更改age为 25。
编译zig器检测到我们正在尝试更改常量对象/标识符的值,因此,编译器将引发编译错误,警告我们该错误。
const age = 24;
// The line below is not valid!
age = 25;
t.zig:10:5: error: cannot assign to constant
age = 25;
~~^~~
因此,如果要更改对象的值,则需要将不可变(或“常量”)对象转换为可变(或“变量”)对象。您可以使用var关键字来实现这一点。此关键字代表“变量”,当您将此关键字应用于某个对象时,您就是在告诉 Zig 编译器,与该对象关联的值可能会在某个时候发生变化。
因此,如果我们回到前面的示例,并将age对象的声明更改为使用var关键字,那么程序就能成功编译。因为现在,zig编译器检测到我们正在更改允许此行为的对象的值,因为它是一个“变量对象”。
但是,如果您查看下面的示例,您会注意到我们不仅age用关键字声明了对象,而且这次还用typevar明确地注释了对象的数据类型。基本思想是,当我们使用变量/可变对象时,Zig 编译器要求我们更明确地说明我们想要什么,更清楚地说明我们的代码的作用。这意味着我们需要更明确地说明我们想要在对象中使用的数据类型。age``u8
因此,如果将对象转换为变量/可变对象,请务必记住在代码中显式注释对象的类型。否则,Zig 编译器可能会引发编译错误,要求您将对象转换回对象const,或者赋予对象一个“显式类型”。
var age: u8 = 24;
age = 25;
1.4.2不带初始值的声明
默认情况下,在 Zig 中声明新对象时,必须赋予其初始值。换句话说,这意味着我们必须声明并同时初始化在源代码中创建的每个对象。
另一方面,你实际上可以在源代码中声明一个新对象,而不赋予它显式的值。但我们需要为此使用一个特殊的关键字,即undefined关键字。
需要强调的是,你应该undefined尽可能避免使用 this 关键字。因为当你使用 this 关键字时,你的对象处于未初始化状态。因此,如果出于某种原因,你的代码在未初始化的情况下使用了该对象,那么你的程序中肯定会出现未定义的行为和重大错误。
在下面的示例中,我age再次声明了该对象。但这次,我没有赋予它初始值。该变量仅在第二行代码中初始化,我将数字 25 存储在该对象中。
var age: u8 = undefined;
age = 25;
undefined记住这些要点,只需记住在代码中尽可能避免使用关键字。务必声明并初始化对象。因为这会大大提高程序的安全性。但如果您确实需要声明一个对象而不进行初始化……那么undefined在 Zig 中,关键字是实现此目的的方法。
1.4.3不存在未使用的对象
在 Zig 中声明的每个对象(常量或变量)都必须以某种方式使用。您可以将此对象作为函数参数提供给函数调用,或者,您可以在另一个表达式中使用它来计算另一个对象的值,或者,您可以调用属于此特定对象的方法。
无论你以何种方式使用它,只要你使用它就行。如果你试图违反此规则,例如,如果你试图声明一个对象但不使用它,zig编译器将不会编译你的 Zig 源代码,并且会发出一条错误消息,警告你代码中存在未使用的对象。
让我们用一个例子来证明这一点。在下面的源代码中,我们声明了一个名为的常量对象age。如果你尝试用下面这行代码编译一个简单的 Zig 程序,编译器将返回一个错误,如下所示:
const age = 15;
t.zig:4:11: error: unused local constant
const age = 15;
^~~
每次在 Zig 中声明一个新对象时,您有两个选择:
- 您要么使用这个对象的值;
- 或者你明确地丢弃该对象的值;
要显式地丢弃任何对象(常量或变量)的值,您只需将该对象分配给 Zig 中的特殊字符,即下划线 ( _)。当您将对象分配给下划线时(如下例所示),zig编译器将自动丢弃此特定对象的值。
您可以在下面的示例中看到,这一次,编译器没有抱怨任何“未使用的常量”,并成功编译了我们的源代码。
// It compiles!
const age = 15;
_ = age;
现在,请记住,每次将特定对象赋值给下划线时,该对象实际上都会被销毁。它会被编译器丢弃。这意味着你不能再在代码中使用该对象。它已经不存在了。
因此,如果您尝试在下面的示例中使用该常量age,在我们丢弃它之后,您将从编译器收到一条响亮的错误消息(谈论“无意义的丢弃”),警告您有关此错误。
// It does not compile.
const age = 15;
_ = age;
// Using a discarded value!
std.debug.print("{d}\n", .{age + 2});
t.zig:7:5: error: pointless discard
of local constant
同样的规则也适用于变量对象。每个变量对象也必须以某种方式使用。如果你将一个变量对象赋值给下划线,这个对象也会被丢弃,你将无法再使用它。
1.4.4必须改变每个变量对象
你在源代码中创建的每个变量对象都必须在某个时刻被修改。换句话说,如果你使用关键字 将一个对象声明为变量对象,var并且在未来某个时刻没有更改该对象的值,zig编译器就会检测到这种情况,并抛出一个错误,警告你这个错误。
其背后的概念是,您在 Zig 中创建的每个对象最好都是常量对象,除非您确实需要一个在程序执行期间其值会发生变化的对象。
因此,如果我尝试声明如下所示的变量对象where_i_live,并且我没有以某种方式更改该对象的值,则zig编译器会引发一条错误消息,并显示“变量永远不会变异”。
var where_i_live = "Belo Horizonte";
_ = where_i_live;
t.zig:7:5: error: local variable is never mutated
t.zig:7:5: note: consider using 'const'
1.5原始数据类型
Zig 有许多不同的原始数据类型可供使用。您可以在官方语言参考第 21页查看可用数据类型的完整列表。
但这里有一个简短的列表:
- 无符号整数:
u8,8位整数;u16,16位整数;u32,32位整数;u64,64位整数;u128,128位整数。 - 有符号整数:
i8,8位整数;i16,16位整数;i32,32位整数;i64,64位整数;i128,128位整数。 - 浮点数:
f16,16位浮点数;f32,32位浮点数;f64,64位浮点数;f128,128位浮点数; - 布尔值:
bool,表示真值或假值。 - C ABI 兼容类型:
c_long、、、、、、以及许多其他类型c_char。c_short``c_ushort``c_int``c_uint - 指针大小的整数:
isize和usize。
1.6数组
在 Zig 中,您可以使用类似于 C 语言的语法创建数组。首先,在括号内指定要创建的数组的大小(即数组中存储的元素数量)。
然后,指定将存储在此数组中的元素的数据类型。Zig 中,数组中存在的所有元素必须具有相同的数据类型。例如,不能在同一个数组中混合使用 类型的元素f32和 类型的元素。i32
之后,只需将要存储在此数组中的值用一对花括号括起来即可。在下面的示例中,我创建了两个包含不同数组的常量对象。第一个对象包含一个包含 4 个整数值的数组,而第二个对象包含一个包含 3 个浮点值的数组。
现在,您应该注意到,在 object 中ls,我没有在括号内明确指定数组的大小。ns我没有使用字面值(例如我在 object 中使用的值 4),而是使用了特殊字符下划线 ( _)。此语法告诉zig编译器用花括号内列出的元素数量来填充此字段。因此,这种语法[_]适合那些懒惰(或聪明)的程序员,他们将计算花括号内元素数量的工作留给了编译器。
const ns = [4]u8{48, 24, 12, 6};
const ls = [_]f64{432.1, 87.2, 900.05};
_ = ns; _ = ls;
值得注意的是,这些是静态数组,这意味着它们的大小无法增长。一旦声明了数组,就无法更改其大小。这在低级语言中很常见。因为低级语言通常希望将内存的完全控制权交给程序员,而数组的扩展方式与内存管理紧密相关。
1.6.1选择数组元素
一种非常常见的操作是选择源代码中数组的特定部分。在 Zig 中,您可以从数组中选择特定元素,只需在对象名称后的括号内提供该特定元素的索引即可。在下面的示例中,我将从ns数组中选择第三个元素。请注意,Zig 是一种基于“零索引”的语言,类似于 C、C++、Rust、Python 和许多其他语言。
const ns = [4]u8{48, 24, 12, 6};
try stdout.print("{d}\n", .{ ns[2] });
12
相反,您也可以使用范围选择器来选择数组的特定切片(或部分)。一些程序员也将这些选择器称为“切片选择器”,它们也存在于 Rust 中,并且具有与 Zig 完全相同的语法。无论如何,范围选择器是 Zig 中的一种特殊表达式,它定义了索引范围,其语法为start..end。
在下面示例中,第二行代码中,sl对象存储了数组的一个切片(或一部分)ns。更准确地说,是数组中索引 1 和 2 处的元素ns。
const ns = [4]u8{48, 24, 12, 6};
const sl = ns[1..3];
_ = sl;
使用该start..end语法时,范围选择器的“末尾”是不包含的,这意味着末尾的索引不包含在从数组中选择的范围中。因此,该语法start..end实际上意味着start..end - 1。
例如,您可以使用语法创建一个从数组的第一个元素到最后一个元素的切片,ar[0..ar.len]换句话说,它是一个访问数组中所有元素的切片。
const ar = [4]u8{48, 24, 12, 6};
const sl = ar[0..ar.len];
_ = sl;
start..您还可以在范围选择器中使用该语法。该语法指示zig编译器选择从索引开始到数组最后一个元素的数组部分start。在下面的示例中,我们选择从索引 1 到数组末尾的范围。
const ns = [4]u8{48, 24, 12, 6};
const sl = ns[1..];
_ = sl;
1.6.2关于切片的更多信息
正如我们之前讨论过的,在 Zig 中,您可以选择现有数组的特定部分。这在 Zig 中称为 切片( Sobeston 2024 ),因为当您选择数组的一部分时,您将从该数组创建一个切片对象。
切片对象本质上是一个指针对象,并附带一个长度数字。指针对象指向切片中的第一个元素,长度数字则告诉zig编译器此切片中有多少个元素。
切片可以被认为是一对
[*]T(指向数据的指针)和一个usize(元素计数)(Sobeston 2024)。
通过切片内部的指针,您可以访问从原始数组中选择的范围(或部分)内的元素(或值)。但长度值(您可以通过len切片对象的属性访问)才是 Zig 带来的真正重大改进(例如,相对于 C 数组而言)。
因为有了这个长度数字,zig编译器就可以轻松地检查你是否试图访问超出此特定切片范围的索引,或者是否导致了任何缓冲区溢出问题。在下面的示例中,我们访问了len切片的属性sl,它告诉我们该切片包含 2 个元素。
const ns = [4]u8{48, 24, 12, 6};
const sl = ns[1..3];
try stdout.print("{d}\n", .{sl.len});
2
1.6.3数组运算符
Zig 中有两个非常有用的数组运算符:数组连接运算符(++)和数组乘法运算符(**)。顾名思义,它们都是数组运算符。
关于这两个运算符的一个重要细节是,它们只有当两个操作数的大小(或“长度”)在编译时已知时才有效。我们将在第 3.1.1 节中详细讨论“编译时已知”和“运行时已知”之间的区别。但现在,请记住,并非在所有情况下都可以使用这些运算符。
总而言之,该++运算符创建一个新数组,该数组是两个作为操作数的数组的连接。因此,该表达式a ++ b生成一个新数组,其中包含数组a和b的所有元素。
const a = [_]u8{1,2,3};
const b = [_]u8{4,5};
const c = a ++ b;
try stdout.print("{any}\n", .{c});
{ 1, 2, 3, 4, 5 }
此运算符对于连接字符串特别有用。Zig 中的字符串在1.8 节++中有深入描述。总而言之,Zig 中的字符串对象本质上是一个字节数组。因此,您可以使用此数组连接运算符有效地将字符串连接在一起。
相反,**运算符用于多次复制数组。换句话说,该表达式创建一个新数组,其中包含重复 3 次a ** 3的数组元素。a
const a = [_]u8{1,2,3};
const c = a ** 2;
try stdout.print("{any}\n", .{c});
{ 1, 2, 3, 1, 2, 3 }
1.6.4切片的运行时与编译时已知长度
我们将在本书中大量讨论编译时已知和运行时已知之间的区别,尤其是在第 3.1.1 节中。但基本思想是,当我们在编译时知道某个事物的所有信息(值、属性和特性)时,该事物就是编译时已知的。相反,运行时已知是指该事物的确切值仅在运行时计算。因此,我们无法在编译时知道该事物的值,只能在运行时知道。
我们在1.6.1 节中了解到,切片是使用_范围选择器_创建的,该选择器表示一个索引范围。当这个“索引范围”(即范围的起始和结束)在编译时已知时,创建的切片对象实际上只是一个指向数组的单项指针。
你现在不需要精确理解这意味着什么。我们将在第六章详细讨论指针。现在,你只需要理解,当索引范围在编译时已知时,创建的切片只是一个指向数组的指针,并附带一个表示切片大小的长度值。
如果你有一个像这样的切片对象,即一个编译时已知范围的切片,你可以对这个切片对象使用常见的指针操作。例如,你可以使用.*方法来取消引用这个切片的指针,就像对普通指针对象执行的操作一样。
const arr1 = [10]u64 {
1, 2, 3, 4, 5,
6, 7, 8, 9, 10
};
// This slice has a compile-time known range.
// Because we know both the start and end of the range.
const slice = arr1[1..4];
_ = slice;
另一方面,如果在编译时不知道索引的范围,那么创建的切片对象就不再是指针,因此它不支持指针操作。例如,起始索引可能在编译时已知,但结束索引未知。在这种情况下,切片的范围将变为仅在运行时才可知。
在下面的示例中,我们正在读取一个文件,然后尝试创建一个切片对象,该对象覆盖包含该文件内容的整个缓冲区。这显然是一个运行时已知范围的示例,因为该范围的结束索引在编译时是未知的。
换句话说,范围的结束索引就是数组的大小file_contents。然而,的大小file_contents在编译时是未知的。因为我们不知道这个shop-list.txt文件里面存储了多少字节。而且,由于这是一个文件,明天可能会有人编辑这个文件,添加或删除行。因此,这个文件的大小在每次执行时可能会有很大差异。
现在,如果文件大小在每次运行中都会有所不同,那么我们可以得出结论,file_contents.len下面示例中显示的表达式的值在每次运行中也会有所不同。因此,表达式的值file_contents.len仅在运行时才可知,因此,其范围0..file_contents.len也仅在运行时才可知。
const std = @import("std");
const builtin = @import("builtin");
fn read_file(allocator: std.mem.Allocator, path: []const u8) ![]u8 {
const file = try std.fs.cwd().openFile(path, .{});
defer file.close();
return try file.reader().readAllAlloc(
allocator, std.math.maxInt(usize)
);
}
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
const path = "../ZigExamples/file-io/shop-list.txt";
const file_contents = try read_file(allocator, path);
const slice = file_contents[0..file_contents.len];
_ = slice;
}
1.7块和作用域
在 Zig 中,块由一对花括号创建。块只是包含在一对花括号内的一组表达式(或语句)。包含在这对花括号内的所有这些表达式都属于同一作用域。
换句话说,块只是在代码中划定了一个作用域。在同一个块内定义的对象属于同一个作用域,因此可以在该作用域内访问。同时,这些对象在该作用域之外无法访问。所以,你也可以说块用于限制你在源代码中创建的对象的作用域。用通俗的术语来说,块用于指定在源代码中可以访问任何对象的位置。
所以,代码块只是包含在一对花括号内的一组表达式。每个代码块都有其独立的范围,与其他代码块相隔离。函数体就是一个典型的代码块示例。if 语句、for 和 while 循环(以及该语言中任何其他使用花括号的结构)也是代码块的示例。
这意味着,你在源代码中创建的每个 if 语句、for 循环等都有其各自独立的作用域。这就是为什么你无法在外部作用域(即 for 循环之外的作用域)访问你在 for 循环(或 if 语句)内部定义的对象。因为你试图访问的对象所属的作用域与你当前作用域不同。
您可以在块内创建块,并具有多层嵌套。您还可以(如果需要)使用冒号 ( :) 为特定块添加标签。只需label:在打开分隔块的花括号之前写入即可。在 Zig 中标记块时,可以使用break关键字从该块返回一个值,就像它是函数的主体一样。您只需编写break关键字,后跟格式为 的块标签:label,以及定义要返回值的表达式。
就像下面的例子一样,我们y从块中返回对象的值add_one,并将结果保存在x对象内部。
var y: i32 = 123;
const x = add_one: {
y += 1;
break :add_one y;
};
if (x == 124 and y == 124) {
try stdout.print("Hey!", .{});
}
Hey!
1.8字符串在 Zig 中如何工作?
本书将要构建和讨论的第一个项目是 Base64 编码器/解码器(第 4 章)。但为了构建这样一个东西,我们需要更好地理解字符串在 Zig 中的工作方式。因此,让我们来讨论一下 Zig 的这个具体方面。
Zig 中的字符串与 C 语言中的字符串非常相似,但它们有一些额外的注意事项,从而提高了安全性和效率。您也可以说 Zig 只是使用了一种更现代、更安全的方法来管理和使用字符串。
Zig 中的字符串本质上是一个任意字节的数组,或者更具体地说,是一个u8值数组。这与 C 语言中的字符串非常相似,它也被解释为任意字节的数组,或者在 C 语言中,是一个值数组char(在大多数系统中通常表示一个无符号的 8 位整数值)。
现在,由于 Zig 中的字符串是一个数组,因此您可以自动获取嵌入在值本身中的字符串长度(即数组的长度)。这至关重要!因为现在,Zig 编译器可以使用嵌入在字符串中的长度值来检查代码中是否存在“缓冲区溢出”或“错误的内存访问”问题。
要在 C 语言中实现同样的安全性,你必须做很多看似毫无意义的工作。所以,在 C 语言中实现这种安全性并非自动实现,而且难度更大。例如,如果你想在 C 语言程序中跟踪字符串的长度,那么首先需要循环遍历表示该字符串的字节数组,找到空元素('\0')的位置,从而确定数组的确切结束位置,或者换句话说,找出字节数组包含多少个元素。
为此,您需要在 C 中执行类似这样的操作。在此示例中,存储在对象中的 C 字符串array长为 25 个字节:
#include <stdio.h>
int main() {
char* array = "An example of string in C";
int index = 0;
while (1) {
if (array[index] == '\0') {
break;
}
index++;
}
printf("Number of elements in the array: %d\n", index);
}
Number of elements in the array: 25
在 Zig 中,你不需要做这样的工作。因为字符串的长度始终存在,并且可以在字符串值本身中访问。你可以通过len属性轻松访问字符串的长度。例如,string_object下面的对象长度为 43 个字节:
const std = @import("std");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const string_object = "This is an example of string literal in Zig";
try stdout.print("{d}\n", .{string_object.len});
}
43
另一点是,Zig 始终假设字符串中的字节序列是 UTF-8 编码的。对于您处理的每个字节序列,这可能并非如此,但 Zig 的真正职责并非修复字符串的编码(您可以使用22来解决这个问题)。如今,现代世界中的大多数文本,尤其是在网络上,都应该采用 UTF-8 编码。因此,如果您的字符串文字不是 UTF-8 编码的,那么您在 Zig 中可能会遇到问题。iconv
以单词“Hello”为例。在UTF-8编码中,该字符序列(H,e,l,l,o)用十进制数序列72、101、108、108、111表示。在十六进制中,该序列为,,,,,0x48。因此,如果我采用这个十六进制值序列,并要求Zig将此字节序列打印为字符序列(即字符串),那么文本“Hello”将打印到终端中:0x65``0x6C``0x6C``0x6F
const std = @import("std");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const bytes = [_]u8{0x48, 0x65, 0x6C, 0x6C, 0x6F};
try stdout.print("{s}\n", .{bytes});
}
Hello
1.8.1使用切片与标记终止数组
在内存中,Zig 中的所有字符串值始终以相同的方式存储。它们只是存储为任意字节的序列/数组。但是,您可以通过两种不同的方式使用和访问此字节序列。您可以通过以下方式访问此字节序列:
- 以标记终止的值数组
u8。 - 或者作为价值观的一部分
u8。
1.8.1.1哨兵终止数组
Zig 中的哨兵终止数组在 Zig 23语言参考中进行了描述。总而言之,哨兵终止数组只是一个普通数组,但不同之处在于它们在数组的最后一个索引/元素处包含一个“哨兵值”。使用哨兵终止数组,您可以将数组的长度和哨兵值嵌入到对象的类型本身中。
例如,如果您在代码中写入一个字符串文字值,并要求 Zig 打印该值的数据类型,通常会得到以下格式的数据类型*const [n:0]u8。n数据类型中的 表示字符串的大小(即数组的长度)。数据类型部分n:后面的零是标记值(哨兵)本身。
// This is a string literal value:
_ = "A literal value";
try stdout.print("{any}\n", .{@TypeOf("A literal value")});
*const [15:0]u8
因此,使用这种数据类型,*const [n:0]u8本质上就是说你有一个u8长度为的数组n,其中,与数组长度对应的索引处的元素n是数字零。如果你认真思考这个描述,你会发现这只是在 C 语言中描述字符串的一种奇特方式,字符串是一个以空值结尾的字节数组。CNULL语言中的值是数字零。因此,在 C 语言中以空值/零值结尾的数组本质上是 Zig 语言中的标记终止数组,其中数组的标记值是数字零。
因此,Zig 中的字符串文字值只是一个指向以空字符结尾的字节数组的指针(即类似于 C 字符串)。但在 Zig 中,字符串文字值还将字符串的长度以及它们以“空字符结尾”的事实嵌入到值本身的数据类型中。
1.8.1.2切片
您还可以访问和使用将字符串表示为值切片的任意字节序列u8。Zig 标准库中的大多数函数通常以值切片的形式接收字符串作为输入(切片在1.6 节u8中介绍)。
因此,您会看到许多数据类型为[]u8或 的字符串值[]const u8,具体取决于存储此字符串的对象是用 标记为常量const,还是用 标记为变量var。现在,由于本例中的字符串被解释为切片,因此此切片不一定以空值结尾,因为现在标记值不再是必需的。您可以根据需要在切片中包含空值/零值,但没有必要这样做。
// This is a string value being
// interpreted as a slice.
const str: []const u8 = "A string value";
try stdout.print("{any}\n", .{@TypeOf(str)});
[]const u8
1.8.2遍历字符串
如果要查看 Zig 中表示字符串的实际字节数,可以使用for循环遍历字符串中的每个字节,并要求 Zig 将每个字节以十六进制值的形式打印到终端。您可以使用print()带有X格式说明符的语句来执行此操作,就像通常使用C 语言中的printf()函数24一样。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const string_object = "This is an example";
try stdout.print("Bytes that represents the string object: ", .{});
for (string_object) |byte| {
try stdout.print("{X} ", .{byte});
}
try stdout.print("\n", .{});
}
Bytes that represents the string object: 54 68 69
73 20 69 73 20 61 6E 20 65 78 61 6D 70 6C 65
1.8.3更好地了解对象类型
现在,我们可以更好地检查 Zig 创建的对象类型。要检查 Zig 中任何对象的类型,可以使用该@TypeOf()函数。如果我们查看下面的对象类型simple_array,您会发现该对象是一个包含 4 个元素的数组。每个元素都是一个 32 位有符号整数,与 Zig 中的数据类型相对应i32。这就是类型对象的含义[4]i32。
但是,如果我们仔细观察下面显示的字符串字面值的类型,就会发现它是一个*const指向 16 个元素(或 16 个字节)数组的常量指针(因此有注释)。每个元素都是一个字节(更准确地说,是一个无符号的 8 位整数 - u8),这就是为什么我们有[16:0]u8下面的类型部分。此外,由于数据类型中字符后面的零值,您还可以看到这是一个以空字符结尾的数组:。换句话说,下面显示的字符串字面值长度为 16 个字节。
现在,如果我们创建一个指向该simple_array对象的指针,那么我们将得到一个指向 4 个元素的数组的常量指针(*const [4]i32),这与字符串文字值的类型非常相似。这表明 Zig 中的字符串文字值已经是一个指向以空字符结尾的字节数组的指针。
此外,如果我们看一下string_obj对象的类型,您将看到它是一个切片对象(因此是[]该类型的部分),是一系列常u8量值(因此是const u8该类型的部分)。
const std = @import("std");
pub fn main() !void {
const simple_array = [_]i32{1, 2, 3, 4};
const string_obj: []const u8 = "A string object";
std.debug.print(
"Type 1: {}\n", .{@TypeOf(simple_array)}
);
std.debug.print(
"Type 2: {}\n", .{@TypeOf("A string literal")}
);
std.debug.print(
"Type 3: {}\n", .{@TypeOf(&simple_array)}
);
std.debug.print(
"Type 4: {}\n", .{@TypeOf(string_obj)}
);
}
Type 1: [4]i32
Type 2: *const [16:0]u8
Type 3: *const [4]i32
Type 4: []const u8
1.8.4字节与unicode点
需要指出的是,数组中的每个字节不一定代表一个字符。这是由于单个字节和单个 Unicode 点之间的差异造成的。
UTF-8 编码的原理是为字符串中的每个字符分配一个数字(称为 Unicode 点)。例如,字符“H”在 UTF-8 中存储为十进制数 72。这意味着数字 72 是字符“H”的 Unicode 点。UTF-8 编码字符串中可能出现的每个字符都有其自己的 Unicode 点。
例如,带删除线的拉丁大写字母 A(Ⱥ)用数字(或 unicode 点)570 表示。但是,这个十进制数(570)大于单个字节内存储的最大数字 255。换句话说,用单个字节可以表示的最大十进制数是 255。这就是为什么 unicode 点 570 实际上以字节的形式存储在计算机内存中的原因C8 BA。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const string_object = "Ⱥ";
_ = try stdout.write(
"Bytes that represents the string object: "
);
for (string_object) |char| {
try stdout.print("{X} ", .{char});
}
}
Bytes that represents the string object: C8 BA
这意味着要将字符 Ⱥ 存储在 UTF-8 编码的字符串中,我们需要使用两个字节一起来表示数字 570。这就是为什么字节和 unicode 点之间的关系并不总是 1 对 1 的原因。每个 unicode 点都是字符串中的单个字符,但单个字节并不总是对应单个 unicode 点。
所有这些意味着,如果你在 Zig 中循环遍历字符串的元素,你将循环遍历表示该字符串的字节,而不是该字符串的字符。在上面的 Ⱥ 示例中,for 循环需要两次迭代(而不是一次迭代)才能打印出表示这个 Ⱥ 字母的两个字节。
现在,所有英文字母(或者如果你愿意,也可以是 ASCII 字母)都可以用 UTF-8 的一个字节表示。因此,如果你的 UTF-8 字符串只包含英文字母(或 ASCII 字母),那么你很幸运。因为字节数等于该字符串中的字符数。换句话说,在这种特定情况下,字节数和 Unicode 点数的关系是 1:1。
但另一方面,如果您的字符串包含其他类型的字母……例如,您可能正在处理包含中文、日文或拉丁字母的文本数据,那么表示 UTF-8 字符串所需的字节数可能会比该字符串中的字符数高得多。
如果您需要遍历字符串的字符而不是字节,那么您可以使用std.unicode.Utf8View结构来创建一个遍历字符串的 unicode 点的迭代器。
在下面的例子中,我们循环遍历日文字符“アメリカ”。此字符串中的四个字符每个都由三个字节表示。但 for 循环迭代了四次,每个字符/unicode 点迭代一次:
const std = @import("std");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
var utf8 = try std.unicode.Utf8View.init("アメリカ");
var iterator = utf8.iterator();
while (iterator.nextCodepointSlice()) |codepoint| {
try stdout.print(
"got codepoint {}\n",
.{std.fmt.fmtSliceHexUpper(codepoint)},
);
}
}
got codepoint E382A2
got codepoint E383A1
got codepoint E383AA
got codepoint E382AB
1.8.5一些有用的字符串函数
在本节中,我只想快速描述Zig标准库中的一些函数,这些函数在处理字符串时非常有用。最值得注意的是:
std.mem.eql():比较两个字符串是否相等。std.mem.splitScalar():根据给定的分隔符值将字符串拆分为子字符串数组。std.mem.splitSequence():根据给定的子字符串分隔符将字符串拆分为子字符串数组。std.mem.startsWith():检查字符串是否以子字符串开头。std.mem.endsWith():检查字符串是否以子字符串结尾。std.mem.trim():从字符串的开头和结尾删除特定值。std.mem.concat():将字符串连接在一起。std.mem.count():统计字符串中子字符串的出现次数。std.mem.replace():替换字符串中出现的子字符串。
请注意,所有这些函数都来自memZig 标准库的模块。该模块包含多个函数和方法,通常可用于处理内存和字节序列。
该eql()函数用于检查两个数据数组是否相等。由于字符串只是任意的字节数组,因此我们可以使用此函数比较两个字符串。该函数返回一个布尔值,指示两个字符串是否相等。该函数的第一个参数是被比较数组元素的数据类型。
const name: []const u8 = "Pedro";
try stdout.print(
"{any}\n", .{std.mem.eql(u8, name, "Pedro")}
);
true
splitScalar()和函数splitSequence()可用于将字符串拆分成多个片段,类似于split()Python 字符串中的 方法。这两种方法的区别在于, 函数splitScalar()使用单个字符作为分隔符来拆分字符串,而 函数则splitSequence()使用字符序列(也称为子字符串)作为分隔符。本书后面会提供一个关于这两个函数的实际示例。
startsWith()和函数endsWith()非常简单。它们返回一个布尔值,指示字符串(或者更准确地说,数据数组)是否以提供的序列开始( startsWith)或结束( )。endsWith
const name: []const u8 = "Pedro";
try stdout.print(
"{any}\n", .{std.mem.startsWith(u8, name, "Pe")}
);
true
concat()顾名思义,该函数用于将两个或多个字符串连接在一起。由于连接字符串的过程需要分配足够的空间来容纳所有字符串,因此该concat()函数接收一个分配器对象作为输入。
const str1 = "Hello";
const str2 = " you!";
const str3 = try std.mem.concat(
allocator, u8, &[_][]const u8{ str1, str2 }
);
try stdout.print("{s}\n", .{str3});
可以想象,该replace()函数用于将字符串中的子字符串替换为另一个子字符串。该函数的工作原理与replace()Python 字符串中的方法非常相似。因此,您需要提供一个要搜索的子字符串,每当函数replace()在输入字符串中找到此子字符串时,它都会用您提供的“替换子字符串”替换此子字符串。
在下面的示例中,我们取输入字符串“Hello”,并将其中所有出现的子字符串“el”替换为“34”,并将结果保存在buffer对象中。结果,该replace()函数返回一个usize值,指示执行了多少次替换。
const str1 = "Hello";
var buffer: [5]u8 = undefined;
const nrep = std.mem.replace(
u8, str1, "el", "34", buffer[0..]
);
try stdout.print("New string: {s}\n", .{buffer});
try stdout.print("N of replacements: {d}\n", .{nrep});
New string: H34lo
N of replacements: 1
1.9 Zig 的安全性
现代低级编程语言的普遍趋势是安全性。随着现代世界与科技和计算机的联系日益紧密,所有这些技术产生的数据已成为我们拥有的最重要(也是最危险)的资产之一。
这或许是现代低级编程语言高度重视安全性(尤其是内存安全性)的主要原因,因为内存损坏仍然是黑客攻击的主要目标。事实上,我们并没有简单的解决方案。目前,我们只有一些技术和策略来缓解这些问题。
正如理查德·费尔德曼在他最近的 GOTO 大会演讲25中所解释的那样,我们还没有找到一种在技术上实现真正安全的方法。换句话说,我们还没有找到一种方法来构建 100% 确定不会被利用的软件。我们可以通过例如确保内存安全来大幅降低软件被利用的风险。但这还不足以达到“真正的安全”境界。
因为即使你用“安全语言”编写程序,黑客仍然可以利用程序所在操作系统的漏洞(例如,运行代码的系统可能存在“后门漏洞”,仍然可能以意想不到的方式影响你的代码),或者,他们还可以利用计算机架构的特性。最近发现的一个漏洞利用 ARM 芯片中的“内存标签”特性来使内存失效,就是一个例子(Kim 等人,2024 年)。
问题是:Zig 和其他语言做了什么来缓解这个问题?以 Rust 为例,Rust 在大多数情况下,通过强制开发人员遵守特定规则,是一种内存安全的语言。换句话说,Rust 的关键特性——借用检查器,强制你在编写 Rust 代码时遵循特定的逻辑,而每次你试图摆脱这种模式时,Rust 编译器都会报错。
相比之下,Zig 语言默认并非内存安全语言。Zig 中有一些内存安全特性是免费的,尤其是在数组和指针对象中。但该语言还提供了一些默认不使用的工具。换句话说,zig编译器并不强制你使用这些工具。
下面列出的工具与内存安全相关。也就是说,它们可以帮助您在 Zig 代码中实现内存安全:
defer允许您将释放操作在物理上靠近分配操作。这有助于避免内存泄漏、“释放后使用”以及“重复释放”问题。此外,它还将释放操作在逻辑上与当前作用域的末尾绑定,从而大大减少了对象生命周期相关的心理开销。errdefer帮助您保证您的程序释放分配的内存,即使发生运行时错误。- 默认情况下,指针和对象不可为空。这有助于避免因取消引用空指针而可能引起的内存问题。
- Zig 提供了一些原生类型的分配器(称为“测试分配器”),可以检测内存泄漏和双重释放。这些类型的分配器在单元测试中被广泛使用,因此它们将单元测试转变为一种可以用来检测代码中内存问题的武器。
- Zig 中的数组和切片的长度嵌入在对象本身中,这使得
zig编译器能够非常有效地检测“索引超出范围”类型的错误,并避免缓冲区溢出。
尽管 Zig 提供的这些功能与内存安全问题相关,但该语言也有一些规则可以帮助您实现另一种类型的安全性,这种安全性与程序逻辑安全性更相关。这些规则是:
- 默认情况下,指针和对象不可为空。这消除了可能破坏程序逻辑的极端情况。
- switch 语句必须穷尽所有可能的选项。
- 编译
zig器强制您处理程序中所有可能的错误。
1.10 Zig 的其他部分
我们已经学习了很多关于 Zig 的语法,以及一些相当技术性的细节。简单回顾一下:
- 我们在第 1.2.2 节和第 1.2.3 节中讨论了如何在 Zig 中编写函数。
- 如何在第 1.2.2 节(尤其是第 1.4 节)中创建新的对象/标识符。
- 第 1.8 节中介绍了字符串在 Zig 中的工作原理。
- 1.6 节中介绍如何使用数组和切片。
- 如何从第 1.2.2 节中的其他 Zig 模块导入功能。
但就目前而言,这些知识足以让我们继续阅读本书。之后,在接下来的章节中,我们还会进一步讨论 Zig 语法中其他同样重要的部分。例如:
- 如何通过第 2.3 节中的_结构声明_在 Zig 中进行面向对象编程。
- 2.1 节中的基本控制流语法。
- 第 7.6 节中的枚举;
- 第 6 章中的指针和可选项;
- 第 10 章中使用
tryand进行错误处理;catch - 第 8 章中的单元测试;
- 第 17 章中的向量;
- 第 9 章中的构建系统;
- https://ziglang.org/learn/overview/#zig-build-system。↩︎
- https://zig.news/edyu/zig-package-manager-wtf-is-zon-558e ↩︎
- https://medium.com/@edlyuu/zig-package-manager-2-wtf-is-build-zig-zon-and-build-zig-0-11-0-update-5bc46e830fc1 ↩︎
- https://github.com/ziglang/zig/blob/master/doc/build.zig.zon.md ↩︎
- https://en.wikipedia.org/wiki/List_of_C-family_programming_languages ↩︎
- 您可以在文件中看到一个
main()返回值的函数示例,https://github.com/pedropark99/zig-book/blob/main/ZigExamples/zig-basics/return-integer.zig ↩︎u8``return-integer.zig - https://github.com/ziglang/zig/issues/17186 ↩︎
- https://github.com/ziglang/zig/issues/19864 ↩︎
- https://github.com/ziglang/zig/tree/master/lib/std ↩︎
- https://github.com/oven-sh/bun。↩︎
- https://github.com/hexops/mach ↩︎
- https://github.com/cgbur/llama2.zig/tree/main ↩︎
- https://github.com/tigerbeetle/tigerbeetle ↩︎
- https://github.com/Hejsil/zig-clap ↩︎
- https://github.com/capy-ui/capy ↩︎
- https://github.com/zigtools/zls ↩︎
- https://github.com/mitchellh/libxev ↩︎
- https://ziglings.org。↩︎
- https://www.youtube.com/watch?v=OPuztQfM3Fg&t=2524s&ab_channel=TheVimeagen。↩︎
- https://adventofcode.com/ ↩︎
- https://ziglang.org/documentation/master/#Primitive-Types。↩︎
- https://www.gnu.org/software/libiconv/ ↩︎
- https://ziglang.org/documentation/master/#Sentinel-Termminate-Arrays。↩︎
- https://cplusplus.com/reference/cstdio/printf/ ↩︎
- https://www.youtube.com/watch?v=jIZpKpLCOiU&ab_channel=GOTOConferences ↩︎
- 实际上,许多现有的 Rust 代码仍然是内存不安全的,因为它们通过 FFI(外部函数接口
unsafe)与外部库通信,这会通过关键字禁用借用检查器功能。↩︎
2 控制流、结构、模块和类型
我们在上一章中讨论了 Zig 的大量语法,尤其是在1.2.2 节和1.2.3 节中。但我们仍然需要讨论该语言的其他一些非常重要的元素。这些元素将在你的日常工作中不断使用。
本章首先讨论 Zig 中与控制流相关的不同关键字和结构(例如循环和 if 语句)。然后,我们讨论结构体以及如何在 Zig 中使用它们来实现一些基本的面向对象 (OOP) 模式。我们还讨论了类型推断和类型转换。最后,我们以讨论模块及其与结构体的关系来结束本章。
2.1控制流
有时,你需要在程序中做出一些决策。也许你需要决定是否执行一段特定的代码。又或者,你需要对一系列值应用相同的操作。这类任务需要使用能够改变程序“控制流”的结构体。
在计算机科学中,“控制流”通常指给定语言或程序中表达式(或命令)的求值顺序。但该术语也用于指能够改变给定语言/程序执行的命令“求值顺序”的结构。
这些结构通常被称为“循环”、“if/else 语句”、“switch 语句”等等。循环和 if/else 语句是可以改变程序“控制流”的结构示例。关键字continue和break也是可以改变求值顺序的符号示例,因为它们可以将程序移动到循环的下一次迭代,或者完全停止循环。
2.1.1 If/else 语句
if/else 语句执行“条件流操作”。条件流控制(或选择控制)允许您根据逻辑条件执行或忽略特定的命令块。许多程序员和计算机科学专业人士在这种情况下也使用术语“分支”。本质上,if/else 语句允许我们根据逻辑测试的结果来决定是否执行给定的命令块。
在 Zig 中,我们使用关键字if和编写 if/else 语句else。我们以关键字 开头,if后跟一对括号内的逻辑测试,然后是一对花括号,其中包含在逻辑测试返回值时要执行的代码行true。
之后,您可以选择添加一条else语句。为此,只需添加关键字,后跟一对花括号,并在定义的逻辑测试返回else时执行代码行。if``false
在下面的示例中,我们测试对象是否x包含大于 10 的数字。根据控制台打印的输出判断,我们知道此逻辑测试返回了。因为控制台中的输出与if/else 语句分支false中的代码行兼容。else
const x = 5;
if (x > 10) {
try stdout.print(
"x > 10!\n", .{}
);
} else {
try stdout.print(
"x <= 10!\n", .{}
);
}
x <= 10!
2.1.2 Switch 语句
Zig 中也提供 Switch 语句,其语法与 Rust 中的 switch 语句非常相似。正如您所料,要在 Zig 中编写 switch 语句,我们使用switch关键字。我们在一对括号内提供要“切换”的值。然后,我们在一对花括号内列出可能的组合(或“分支”)。
我们来看下面的代码示例。可以看到,我正在创建一个名为 Role 的枚举类型。我们将在7.6 节Role中详细讨论枚举。总而言之,此类型列出了一家虚构公司中的不同类型的职位,例如软件工程师SE 、数据工程师DE、产品经理PM等等。
请注意,我们在 switch 语句中使用了role对象的值,以发现需要在area变量对象中存储的具体区域。还要注意,我们在 switch 语句中使用了类型推断,并使用了点字符,正如我们将在2.4 节中描述的那样。这使得zig编译器能够为我们推断出值的正确数据类型(PM、SE等)。
还要注意,我们在 switch 语句的同一个分支中对多个值进行了分组。我们只需用逗号分隔每个可能的值即可。例如,如果role包含 或DE,DA则area变量将包含值"Data & Analytics", ,而不是"Platform"或"Sales"。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
const Role = enum {
SE, DPE, DE, DA, PM, PO, KS
};
pub fn main() !void {
var area: []const u8 = undefined;
const role = Role.SE;
switch (role) {
.PM, .SE, .DPE, .PO => {
area = "Platform";
},
.DE, .DA => {
area = "Data & Analytics";
},
.KS => {
area = "Sales";
},
}
try stdout.print("{s}\n", .{area});
}
Platform
2.1.2.1 Switch 语句必须穷尽所有可能性
Zig 中 switch 语句的一个非常重要的方面是它们必须穷尽所有现有的可能性。换句话说,role对象内部可能找到的所有可能值都必须在此 switch 语句中明确处理。
由于该role对象的类型为Role,因此Role该对象中唯一可能的值是PM、SE、DPE、PO、DE、DA和KS。此role对象中没有其他可能的值可以存储。因此,switch 语句必须针对这些值中的每一个都有一个组合(分支)。这就是“穷尽所有现有可能性”的含义。switch 语句涵盖了所有可能的情况。
因此,你不能在 Zig 中编写 switch 语句,而留下一个没有明确操作的边缘情况。这与 Rust 中的 switch 语句类似,后者也必须处理所有可能的情况。
2.1.2.2 else 分支
dump_hex_fallible()以下面的函数为例。此函数来自 Zig 标准库。更准确地说,来自模块debug.zig1。此函数中有多行代码,但我省略了它们,以便仅关注其中的 switch 语句。请注意,此 switch 语句有四种可能的情况(即四个显式分支)。另外,请注意,我们else在本例中使用了一个分支。
switch 语句中的分支else充当“默认分支”。当你在 switch 语句中遇到多个 case 并希望执行完全相同的操作时,可以使用分支else来实现。
pub fn dump_hex_fallible(bytes: []const u8) !void {
// Many lines ...
switch (byte) {
'\n' => try writer.writeAll("␊"),
'\r' => try writer.writeAll("␍"),
'\t' => try writer.writeAll("␉"),
else => try writer.writeByte('.'),
}
}
许多程序员也会使用else分支来处理“不支持”的情况。也就是说,你的代码无法正确处理这种情况,或者只是不应该“修复”的情况。因此,你可以使用分支else在程序中触发 panic(或引发错误)来停止当前执行。
以下面的代码示例为例。我们可以看到,我们正在处理对象为level1、2 或 3 的情况。所有其他可能的情况默认情况下均不受支持,因此,在这种情况下,我们会通过@panic()内置函数引发运行时错误。
还要注意,我们将 switch 语句的结果赋值给一个名为 的新对象category。这是在 Zig 中使用 switch 语句可以做的另一件事。如果分支输出一个值作为结果,则可以将 switch 语句的结果值存储到一个新对象中。
const level: u8 = 4;
const category = switch (level) {
1, 2 => "beginner",
3 => "professional",
else => {
@panic("Not supported level!");
},
};
try stdout.print("{s}\n", .{category});
thread 13103 panic: Not supported level!
t.zig:9:13: 0x1033c58 in main (switch2)
@panic("Not supported level!");
^
2.1.2.3在 switch 中使用范围
此外,您还可以在 switch 语句中使用值的范围。也就是说,您可以在 switch 语句中创建一个分支,只要输入值在指定范围内,就会使用该分支。这些“范围表达式”由运算符创建...。需要强调的是,此运算符创建的范围包含两端。
例如,我可以轻松地更改前面的代码示例以支持 0 到 100 之间的所有级别。如下所示:
const level: u8 = 4;
const category = switch (level) {
0...25 => "beginner",
26...75 => "intermediary",
76...100 => "professional",
else => {
@panic("Not supported level!");
},
};
try stdout.print("{s}\n", .{category});
beginner
这很简洁,而且它也能用于字符范围。也就是说,我可以简单地写'a'...'z', 来匹配任何小写字母的字符值,这样就可以了。
2.1.2.4带标签的 switch 语句
在1.7 节中,我们讨论了如何给代码块添加标签,以及如何使用这些标签从代码块中返回值。从 0.14.0 及以后的zig编译器版本开始,你也可以在 switch 语句上添加标签,这使得我们几乎可以实现goto类似“C”的模式。
例如,如果你给xswswitch 语句指定了标签,则可以将此标签与关键字结合使用continue,以返回到 switch 语句的开头。在下面的示例中,执行过程两次返回到 switch 语句的开头,然后结束于分支3。
xsw: switch (@as(u8, 1)) {
1 => {
try stdout.print("First branch\n", .{});
continue :xsw 2;
},
2 => continue :xsw 3,
3 => return,
4 => {},
else => {
try stdout.print(
"Unmatched case, value: {d}\n", .{@as(u8, 1)}
);
},
}
2.1.3关键字defer
使用defer关键字 ,你可以注册一个在退出当前作用域时执行的表达式。因此,该关键字的功能与on.exit()R 中的函数类似。以foo()下面的函数为例。执行此foo()函数时,打印“Exiting function ...”消息的表达式仅在函数退出其作用域时执行。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
fn foo() !void {
defer std.debug.print(
"Exiting function ...\n", .{}
);
try stdout.print("Adding some numbers ...\n", .{});
const x = 2 + 2; _ = x;
try stdout.print("Multiplying ...\n", .{});
const y = 2 * 8; _ = y;
}
pub fn main() !void {
try foo();
}
Adding some numbers ...
Multiplying ...
Exiting function ...
因此,我们可以使用defer来声明一个表达式,该表达式将在代码退出当前作用域时执行。有些程序员喜欢将“退出当前作用域”解释为“当前作用域的结束”。但这种解释可能并不完全正确,这取决于你对“当前作用域的结束”的定义。
我的意思是,你认为当前作用域的结束在哪里?是作用域的右花括号(})吗?是函数中最后一个表达式执行的时候吗?是函数返回到前一个作用域的时候吗?等等。例如,将“退出当前作用域”解释为作用域的右花括号是不对的。因为函数可能从比这个右花括号更早的位置退出(例如,在函数内部的上一行生成了一个错误值;函数到达了更早的 return 语句;等等)。无论如何,请谨慎对待这种解释。
现在,如果你还记得我们在1.7 节中讨论过的内容,你会发现语言中有多种结构会创建各自独立的作用域。例如,for/while 循环、if/else 语句、函数、普通代码块等等。这也会影响 的解释defer。例如,如果你defer在 for 循环中使用 ,那么每次这个特定的 for 循环退出其自身作用域时,都会执行给定的表达式。
在继续之前,值得强调的是,该defer关键字是“无条件延迟”的。这意味着无论代码如何退出当前作用域,给定的表达式都会被执行。例如,你的代码可能因为生成错误值、return 语句、break 语句等而退出当前作用域。
2.1.4关键字errdefer
在上一节中,我们讨论了defer关键字,它可以用于注册一个在当前作用域退出时执行的表达式。但是这个关键字还有一个兄弟,那就是errdefer关键字。关键字defer是“无条件延迟”,而errdefer关键字 是“有条件延迟”。这意味着,只有在特定情况下退出当前作用域时,给定的表达式才会执行。
更详细地说,仅当当前作用域发生错误时,才会执行给定的表达式。因此,如果函数(或 for/while 循环、if/else 语句等)在正常情况下退出当前作用域,且没有发生错误,则不会执行errdefer给定的表达式。errdefer
这使得errdefer关键字成为 Zig 中可用于错误处理的众多工具之一。在本节中,我们更关注周围的控制流方面errdefer。但我们稍后将在10.2.4 节errdefer中讨论它作为错误处理工具的作用。
下面的代码示例演示了三件事:
- 这
defer是一个“无条件延迟”,因为无论函数如何foo()退出其自身范围,给定的表达式都会被执行。 errdefer由于函数foo()返回了错误值而执行该操作。- and表达式按照 LIFO (后进先出)的顺序
defer执行errdefer。
const std = @import("std");
fn foo() !void { return error.FooError; }
pub fn main() !void {
var i: usize = 1;
errdefer std.debug.print("Value of i: {d}\n", .{i});
defer i = 2;
try foo();
}
Value of i: 2
error: FooError
/t.zig:6:5: 0x1037e48 in foo (defer)
return error.FooError;
^
当我说“defer 表达式”按照后进先出 (LIFO) 的顺序执行时,我的意思是代码中最后一个defer或errdefer表达式最先被执行。你也可以理解为:“defer 表达式”从下往上执行,或者从最后面往前执行。
defer因此,如果我改变and表达式的顺序,你会注意到打印到控制台的 thaterrdefer的值变为 1。这并不意味着本例中该表达式没有被执行。实际上,这意味着该表达式仅在该表达式之后执行。下面的代码示例演示了这一点:i``defer``defer``errdefer
const std = @import("std");
fn foo() !void { return error.FooError; }
pub fn main() !void {
var i: usize = 1;
defer i = 2;
errdefer std.debug.print("Value of i: {d}\n", .{i});
try foo();
}
Value of i: 1
error: FooError
/t.zig:6:5: 0x1037e48 in foo (defer)
return error.FooError;
^
2.1.5 For 循环
循环允许你多次执行相同的代码行,从而在程序的执行流程中创建一个“重复空间”。当我们想要在不同的输入上复制相同的函数(或相同的命令集)时,循环特别有用。
Zig 中有不同类型的循环。但其中最重要的可能是_for 循环_。for 循环用于将同一段代码应用于切片或数组的元素。
Zig 中的 for 循环使用了一种其他语言程序员可能不熟悉的语法。首先输入for关键字,然后在一对括号内列出要迭代的项。然后,在一对竖线 ( |) 内,声明一个标识符作为迭代器,或者说是“循环的重复索引”。
for (items) |value| {
// code to execute
}
因此,在 Zig 中,for 循环不使用(value in items)语法,而是使用语法(items) |value|。在下面的示例中,您可以看到我们正在循环遍历存储在对象中的数组项name,并将该数组中每个字符的十进制表示形式打印到控制台。
如果需要,我们也可以迭代数组的某个部分(或切片),而不是迭代存储在name对象中的整个数组。只需使用范围选择器来选择所需的部分即可。例如,我可以为 for 循环提供表达式name[0..3],以便仅迭代数组中的前 3 个元素。
const name = [_]u8{'P','e','d','r','o'};
for (name) |char| {
try stdout.print("{d} | ", .{char});
}
80 | 101 | 100 | 114 | 111 |
在上面的例子中,我们使用数组中每个元素本身的值作为迭代器。但在很多情况下,我们需要使用索引而不是元素的实际值。
您可以通过提供第二组要迭代的项目来实现这一点。更准确地说,您为 for 循环提供了范围选择器0..。所以,是的,您可以在 Zig 的 for 循环中同时使用两个不同的迭代器。
但请记住,从1.4 节开始,在 Zig 中创建的每个对象都必须以某种方式使用。因此,如果在 for 循环中声明了两个迭代器,则必须在 for 循环体中使用这两个迭代器。但是,如果您只想使用索引迭代器,而不使用“值迭代器”,则可以通过将值项与下划线字符匹配来丢弃值迭代器,如下例所示:
const name = "Pedro";
for (name, 0..) |_, i| {
try stdout.print("{d} | ", .{i});
}
0 | 1 | 2 | 3 | 4 |
2.1.6 While 循环
while 循环由关键字创建while。whilefor循环会遍历数组的所有元素,而 whilewhile循环则会无限循环,直到某个逻辑测试(由您指定)为 false。
从关键字开始while,然后在一对括号内定义一个逻辑表达式,并在一对花括号内提供循环主体,如下例所示:
var i: u8 = 1;
while (i < 5) {
try stdout.print("{d} | ", .{i});
i += 1;
}
1 | 2 | 3 | 4 |
您还可以指定在 while 循环开头使用的增量表达式。为此,我们将增量表达式写在冒号 ( :) 后的一对括号内。下面的代码示例演示了另一种模式。
var i: u8 = 1;
while (i < 5) : (i += 1) {
try stdout.print("{d} | ", .{i});
}
1 | 2 | 3 | 4 |
2.1.7使用break和continue
break在 Zig 中,您可以分别使用关键字和显式停止循环的执行,或者跳转到循环的下一次迭代continue。while下一个代码示例中显示的循环乍一看是一个无限循环。因为括号内的逻辑值始终等于。但是,当对象达到计数 10 时,true是什么让这个while循环停止呢?答案是关键字!i``break
在 while 循环中,我们有一个 if 语句,它不断检查i变量是否等于 10。由于我们i在 while 循环的每次迭代中都会增加的值,所以这个i对象的值最终会等于 10,当它等于 10 时,if 语句将执行break表达式,结果,while 循环的执行停止。
注意在 while 循环后使用了expect()Zig 标准库中的函数。该expect()函数是一个“断言”类型的函数。此函数检查提供的逻辑测试是否等于 true。如果是,则函数不执行任何操作。否则(即逻辑测试等于 false),该函数将引发断言错误。
var i: usize = 0;
while (true) {
if (i == 10) {
break;
}
i += 1;
}
try std.testing.expect(i == 10);
try stdout.print("Everything worked!", .{});
Everything worked!
由于此代码示例已被编译器成功执行zig,且未引发任何错误,因此我们知道,在执行 while 循环后,i对象等于 10。因为如果它不等于 10,则会引发错误expect()。
现在,在下一个示例中,我们来看一下该continue关键字的用例。if 语句会不断检查当前索引是否是 2 的倍数。如果是,则跳转到循环的下一次迭代。否则,循环只会将当前索引打印到控制台。
const ns = [_]u8{1,2,3,4,5,6};
for (ns) |i| {
if ((i % 2) == 0) {
continue;
}
try stdout.print("{d} | ", .{i});
}
1 | 3 | 5 |
2.2函数参数是不可变的
我们已经在1.2.2节和1.2.3节中讨论了函数声明背后的许多语法。但我想强调一下Zig中关于函数参数(又称函数参数)的一个有趣的事实。总而言之,函数参数在Zig中是不可变的。
以下面的代码示例为例,我们声明了一个简单的函数,它只是尝试将某个数添加到输入整数中,然后返回结果。如果仔细观察这个函数的主体add2(),你会注意到我们尝试将结果保存回x函数参数中。
换句话说,该函数不仅使用通过函数参数 接收到的值x,而且还尝试通过将加法结果赋值给 来更改该函数参数的值x。但是,Zig 中的函数参数是不可变的。您无法更改它们的值,或者,您无法在函数主体内部为它们赋值。
这就是为什么下面的代码示例无法成功编译的原因。如果您尝试编译此代码示例,您将收到一条关于“试图更改不可变(即常量)对象的值”的编译错误消息。
const std = @import("std");
fn add2(x: u32) u32 {
x = x + 2;
return x;
}
pub fn main() !void {
const y = add2(4);
std.debug.print("{d}\n", .{y});
}
t.zig:3:5: error: cannot assign to constant
x = x + 2;
^
2.2.1免费优化
如果函数参数接收一个对象作为输入,而该对象的数据类型是我们在1.5 节中列出的任何原始类型,则该对象始终以值的形式传递给函数。换句话说,该对象会被复制到函数堆栈框架中。
但是,如果输入对象的数据类型更复杂,例如,它可能是结构体实例、数组或联合值等,在这种情况下,zig编译器将自行决定哪种策略最佳。因此,编译器zig将通过值或引用将对象传递给函数。编译器始终会选择对您来说更快的策略。这种免费获得的优化之所以能够实现,是因为函数参数在 Zig 中是不可变的。
2.2.2如何克服这一障碍
在某些情况下,您可能需要直接在函数体内部更改函数参数的值。当我们将 C 结构体作为输入传递给 Zig 函数时,这种情况更常发生。
在这种情况下,你可以使用指针来克服这个障碍。换句话说,你可以传递一个“指向值的指针”,而不是将值作为输入传递给参数。你可以通过取消引用来更改指针指向的值。
因此,以前面的例子为例,我们可以通过将参数x 标记为“指向u32值的指针”(即*u32数据类型)而不是 u32值,在函数体内add2()更改函数参数x 的值。通过将其设置为指针,我们最终可以在函数add2()体内直接更改此函数参数的值。您可以看到下面的代码示例编译成功。
const std = @import("std");
fn add2(x: *u32) void {
const d: u32 = 2;
x.* = x.* + d;
}
pub fn main() !void {
var x: u32 = 4;
add2(&x);
std.debug.print("Result: {d}\n", .{x});
}
Result: 6
即使在上面的代码示例中,x参数仍然是不可变的。这意味着指针本身是不可变的。因此,您无法更改它指向的内存地址。但是,您可以取消引用该指针来访问它指向的值,并且如果需要,还可以更改该值。
2.3结构体和 OOP
Zig 是一种与 C(一种过程式语言)关系更密切的语言,而不是与 C++ 或 Java(面向对象语言)关系更密切的语言。因此,Zig 中不提供高级的 OOP(面向对象编程)模式,例如类、接口或类继承。不过,Zig 中的 OOP 仍然可以通过使用结构体定义来实现。
使用结构体定义,您可以在 Zig 中创建(或定义)新的数据类型。这些结构体定义的工作方式与 C 语言中的工作方式相同。您需要为这个新结构体(或您正在创建的新数据类型)命名,然后列出这个新结构体的数据成员。您还可以在这个结构体中注册函数,它们将成为这个特定结构体(或数据类型)的方法。这样,您使用此新类型创建的每个对象都将始终具有这些可用且与之关联的方法。
在 C++ 中,当我们创建一个新类时,我们通常有一个构造函数方法(或构造函数),用于构造(或实例化)该特定类的每个对象,我们还有一个析构函数方法(或析构函数),它是负责销毁该类的每个对象的函数。
init()在 Zig 中,我们通常通过在结构体内部声明一个和两个方法来声明结构的构造函数和析构函数deinit()。这只是一个命名约定,在整个 Zig 标准库中都会看到。因此,在 Zig 中,init()结构体的方法通常是该结构体所表示的类的构造函数方法。而deinit()方法是用于销毁该结构体现有实例的方法。
init()和方法都在 Zig 代码中广泛使用,当我们在第 3.3 节deinit()讨论分配器时,您将看到它们都被使用。但是,作为另一个例子,让我们构建一个简单的User结构体来表示某种系统的用户。
如果您查看User下面的结构体,就会看到struct关键字。注意此结构体的数据成员:id、name和。每个数据成员的类型都使用我们之前在1.2.2 节中描述的email冒号 (:) 语法明确注释。但也请注意,结构体中描述数据成员的每一行都以逗号 ( ,) 结尾。因此,每次在 Zig 代码中声明数据成员时,请始终以逗号结束行,而不是以传统的分号 (; ) 结束。
接下来,我们注册了一个init()函数作为该结构体的方法User。此init()方法是构造函数,我们将使用它来实例化每个新User对象。因此,此init()函数会返回一个新User对象作为结果。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
const User = struct {
id: u64,
name: []const u8,
email: []const u8,
fn init(id: u64,
name: []const u8,
email: []const u8) User {
return User {
.id = id,
.name = name,
.email = email
};
}
fn print_name(self: User) !void {
try stdout.print("{s}\n", .{self.name});
}
};
pub fn main() !void {
const u = User.init(1, "pedro", "email@gmail.com");
try u.print_name();
}
pedro
2.3.1关键字pub
关键字pub在结构体声明和 Zig 中的 OOP 中扮演着重要的角色。本质上,这个关键字是“public”的缩写,它使某个项/组件在声明该项/组件的模块之外可用。换句话说,如果我没有pub在某个东西上应用这个关键字,就意味着这个“东西”只能在声明这个“东西”的模块内部调用/使用。
为了演示此关键字的效果,让我们再次关注User上一节中声明的结构体。对于此处的示例,假设此User结构体是在名为的 Zig 模块内声明的user.zig。如果我不在结构体pub上使用关键字User,则意味着我只能在声明该结构的模块内(在本例中为模块)创建一个User对象并调用其方法(print_name()和) 。init()``User``user.zig
User这就是前面代码示例运行良好的原因。因为我们在同一个模块中声明并使用了该结构体。但是,当我们尝试从另一个模块导入并调用/使用这个结构体时,问题就开始出现了。例如,如果我创建一个名为 的新模块register.zig,并将该user.zig模块导入其中,并尝试用该User类型注释任何变量,编译器就会报错。
// register.zig
const user = @import("user.zig");
pub fn main() !void {
const u: user.User = undefined;
_ = u;
}
register.zig:3:18: error: 'User' is not marked 'pub'
const u: user.User = undefined;
~~~~^~~~~
user.zig:3:1: note: declared here
const User = struct {
^~~~~
因此,如果你想在声明这个“东西”的模块之外使用它,你必须用pub关键字标记它。这个“东西”可以是模块、结构体、函数、对象等等。
对于我们这里的例子,如果我们回到user.zig模块,并将pub关键字添加到User结构声明中,那么我就可以成功编译register.zig模块。
// user.zig
// Added the `pub` keyword to `User`
pub const User = struct {
// ...
// register.zig
// This works fine now!
const user = @import("user.zig");
pub fn main() !void {
const u: user.User = undefined;
_ = u;
}
现在,如果我尝试实际调用结构体register.zig中的任何方法,你认为会发生什么User?例如,如果我尝试调用该init()方法?答案是:我会收到一条类似的错误消息,警告我该init()方法未标记为pub,如下所示:
const user = @import("user.zig");
pub fn main() !void {
const u: user.User = user.User.init(
1, "pedro", "email@gmail.com"
);
_ = u;
}
register.zig:3:35: error: 'init' is not marked 'pub'
const u: user.User = user.User.init(
~~~~~~~~~^~~~~
user.zig:8:5: note: declared here
fn init(id: u64,
^~~~~~~
因此,仅仅因为我们在结构体声明中使用了pub关键字,并不意味着该结构体的方法也变为公共的。如果我们想在声明该结构体的模块之外使用该结构体中的任何方法(例如方法),我们也init()必须使用关键字pub标记此方法。
回到模块user.zig,用关键字pub标记init()和print_name()方法,使它们都可以供外界使用,从而使前面的代码示例能够工作。
// user.zig
// Added the `pub` keyword to `User.init`
pub fn init(
// ...
// Added the `pub` keyword to `User.print_name`
pub fn print_name(self: User) !void {
// ...
// register.zig
// This works fine now!
const user = @import("user.zig");
pub fn main() !void {
const u: user.User = user.User.init(
1, "pedro", "email@gmail.com"
);
_ = u;
}
2.3.2匿名结构体字面量
可以将结构体对象声明为字面值。通常,在左花括号之前写出该结构体字面值的数据类型来指定其数据类型。例如,我可以User像这样写一个我们在上一节中定义的类型的结构体字面值:
const eu = User {
.id = 1,
.name = "Pedro",
.email = "someemail@gmail.com"
};
_ = eu;
然而,在 Zig 中,我们也可以编写匿名结构体字面量。也就是说,你可以编写结构体字面量,但不必明确指定该特定结构的类型。匿名结构体使用以下语法编写.{}。因此,我们实际上用点字符 ( ) 替换了结构体字面量的显式类型.。
正如我们在2.4 节中所述,当你在结构体字面量前面添加一个点时,zig编译器会自动推断该结构体字面量的类型。本质上,zig编译器会寻找一些关于该结构体类型的提示。这些提示可以是函数参数的类型注解,也可以是函数返回值的类型注解,或者是一个现有对象的类型注解。如果编译器找到了这样的类型注解,它就会在你的结构体字面量中使用它。
在 Zig 中,匿名结构体通常用作函数参数的输入。一个您经常看到的例子是来自stdout对象的print()函数。该函数接受两个参数。第一个参数是一个模板字符串,其中包含字符串格式说明符,用于指示如何将第二个参数中提供的值打印到消息中。
第二个参数是一个结构体字面量,它列出了要打印到第一个参数指定的模板消息中的值。通常情况下,你应该在这里使用一个匿名结构体字面量,这样zig编译器就会为你指定这个特定匿名结构体的类型。
const std = @import("std");
pub fn main() !void {
const stdout = std.io.getStdOut().writer();
try stdout.print("Hello, {s}!\n", .{"world"});
}
Hello, world!
2.3.3结构体声明必须是常量
Zig 中的类型必须是const或(我们将在第 12.1 节comptime中详细讨论 comptime )。这意味着您不能创建新的数据类型,并使用关键字 var 将其标记为变量。因此,结构体声明始终是常量。您不能使用关键字 var 声明新的结构体类型。它必须是const。
在下面的示例中Vec3,允许这种声明,因为我使用const关键字来声明这种新的数据类型。
const Vec3 = struct {
x: f64,
y: f64,
z: f64,
};
2.3.4方法self参数
在所有支持 OOP 的语言中,当我们声明某个类或结构体的方法时,我们通常会将其声明为一个带有self参数的函数。该self参数是对调用该方法的对象本身的引用。
使用此参数并非强制要求self。但为什么不使用self呢?没有理由不使用它。因为访问结构体数据成员中存储的数据的唯一方法是通过此self参数访问它们。如果您不需要在方法中使用结构体数据成员中的数据,则很可能不需要方法。您可以将此逻辑声明为一个简单的函数,放在结构体声明之外。
以下面的结构体为例Vec3。在这个Vec3结构体中,我们声明了一个名为 distance() 的方法。该方法根据欧氏空间中的距离公式distance()计算两个Vec3对象之间的距离。注意,该方法接受两个Vec3对象作为输入,分别为 self 和 other。
const std = @import("std");
const m = std.math;
const Vec3 = struct {
x: f64,
y: f64,
z: f64,
pub fn distance(self: Vec3, other: Vec3) f64 {
const xd = m.pow(f64, self.x - other.x, 2.0);
const yd = m.pow(f64, self.y - other.y, 2.0);
const zd = m.pow(f64, self.z - other.z, 2.0);
return m.sqrt(xd + yd + zd);
}
};
参数self对应于调用Vec3此方法的对象。而other是一个单独的Vec3对象,作为此distance()方法的输入。在下面的示例中,参数 self 对应于对象,因为该方法是distance()从对象 v1 调用的,而参数 other 对应于对象v2。
const v1 = Vec3 {
.x = 4.2, .y = 2.4, .z = 0.9
};
const v2 = Vec3 {
.x = 5.1, .y = 5.6, .z = 1.6
};
std.debug.print(
"Distance: {d}\n",
.{v1.distance(v2)}
);
Distance: 3.3970575502926055
2.3.5关于 struct state
有时你不需要关心结构体对象的状态。有时你只需要实例化并使用这些对象,而无需改变它们的状态。你可能会注意到,当你在结构体声明中有一些方法可能会使用数据成员中现有的值,但它们不会以任何方式改变结构体这些数据成员的值。
2.3.4 节Vec3中介绍的结构体就是一个例子。该结构体只有一个名为 distance() 的方法,并且该方法确实使用了结构体所有三个数据成员( x、y和z)中的值。但同时,该方法在任何时候都不会更改这些数据成员的值。
因此,我们创建Vec3对象时通常将其创建为常量对象,例如2.3.4 节中介绍的v1和v2对象。如果需要,我们也可以使用关键字 var 将它们创建为变量对象。但由于此结构体Vec3的方法在任何时候都不会改变对象的状态,因此无需将它们标记为变量对象。
但为什么呢?我为什么要在这里讨论这个问题?因为self方法中的参数会受到影响,取决于结构体中的方法是否改变对象本身的状态。更具体地说,当结构体中有一个方法会改变对象的状态(即改变数据成员的值)时,self该方法中的参数必须以不同的方式进行注解。
正如我在2.3.4 节中所述,self结构体方法中的参数是指接收调用该方法的对象作为输入的参数。我们通常在方法中用 来注释此参数self,后跟冒号 ( :),以及该方法所属结构体的数据类型(例如 User、Vec3等等)。
如果我们Vec3以上一节中定义的结构体为例,我们可以在distance()方法中看到这个self参数被注释为self: Vec3。因为对象的状态Vec3永远不会被此方法改变。
但是,如果我们确实有一个方法可以通过修改其数据成员的值来改变对象的状态,那么self在这种情况下我们应该如何注解呢?答案是:“我们应该将其注解self为 的指针x,而不仅仅是x”。换句话说,你应该将其注解self为self: *x,而不是将其注解为self: x。
如果我们在对象内部创建一个新方法Vec3,例如,通过将向量的坐标乘以二来扩展向量,那么我们需要遵循上一段中指定的规则。下面的代码示例演示了这个想法:
const std = @import("std");
const m = std.math;
const Vec3 = struct {
x: f64,
y: f64,
z: f64,
pub fn distance(self: Vec3, other: Vec3) f64 {
const xd = m.pow(f64, self.x - other.x, 2.0);
const yd = m.pow(f64, self.y - other.y, 2.0);
const zd = m.pow(f64, self.z - other.z, 2.0);
return m.sqrt(xd + yd + zd);
}
pub fn twice(self: *Vec3) void {
self.x = self.x * 2.0;
self.y = self.y * 2.0;
self.z = self.z * 2.0;
}
};
请注意,在上面的代码示例中,我们向结构体添加了一个Vec3名为 的新方法twice()。此方法将向量对象的坐标值加倍。对于twice(),我们将self参数注释为*Vec3,表示此参数接收一个指向对象的指针(或者,如果您愿意,也可以这样称呼它,即引用)作为Vec3输入。
var v3 = Vec3 {
.x = 4.2, .y = 2.4, .z = 0.9
};
v3.twice();
std.debug.print("Doubled: {d}\n", .{v3.x});
Doubled: 8.4
现在,如果您将此twice()方法中的self参数更改为self: Vec3(就像在distance()方法中一样),您将收到如下所示的编译器错误。请注意,此错误消息显示了twice()方法主体中的一行,表明您无法更改x数据成员的值。
// If we change the function signature of double to:
pub fn twice(self: Vec3) void {
t.zig:16:13: error: cannot assign to constant
self.x = self.x * 2.0;
~~~~^~
此错误消息表明该x数据成员属于常量对象,因此无法更改。最终,此错误消息告诉我们该self参数是常量。
如果您花点时间仔细思考一下这个错误信息,您就会明白。您已经掌握了理解为什么我们会收到此错误信息的工具。我们已经在2.2节讨论过了。所以请记住,在Zig中,每个函数参数都是不可变的,self这条规则也不例外。
在这个例子中,我们将v3对象标记为变量对象。但这无关紧要。因为它与输入对象无关,而是与函数参数有关。
当我们尝试直接修改 的值时self,问题就开始了,因为它是一个函数参数,而每个函数参数默认都是不可变的。你可能会问自己,我们该如何克服这个障碍?同样的,解决方案在2.2 节中也讨论过了。我们通过将self参数显式标记为指针来克服这个障碍。
笔记
如果结构体的方法x通过更改任何数据成员的值来改变对象的状态,那么请记住在该方法的函数签名中使用self: *x,而不是self: x。
x您还可以将本节讨论的内容解释为:“如果您需要在某个方法中更改结构体对象的状态,则必须x通过引用将结构体对象明确传递给self该方法的参数”。
2.4类型推断
Zig 是一种强类型语言。但是,在某些情况下,您不必像使用传统的强类型语言(例如 C 和 C++)那样在源代码中显式地写出每个对象的类型。
在某些情况下,zig编译器可以使用类型推断来帮你解决数据类型问题,从而减轻开发者的一些负担。最常见的做法是通过接收结构体对象作为输入的函数参数。
通常,Zig 中的类型推断是使用点字符 ( .) 来完成的。每当您在结构体字面量、枚举值或类似符号前看到一个点字符时,您就知道这个点字符在这里起着特殊的作用。更具体地说,它告诉zig编译器类似这样的信息:“嘿!你能帮我推断一下这个值的类型吗?拜托!”。换句话说,这个点字符的作用类似于autoC++ 中的关键字。
我在2.3.2 节中给出了一些示例,其中我们使用了匿名结构体字面量。匿名结构体字面量是指使用类型推断来推断特定结构体字面量确切类型的结构体字面量。这种类型推断是通过查找一些关于要使用的正确数据类型的最小提示来完成的。你可以说,zig编译器会查找任何可能告诉它正确类型的邻近类型注解。
在 Zig 中,我们使用类型推断的另一个常见地方是 switch 语句(我们在第 2.1.2 节中讨论过)。在第 2.1.2 节中,我还给出了一些其他类型推断的例子,其中我们推断了 switch 语句中列出的枚举值的数据类型(例如 .DE)。但作为另一个例子,请看一下fence()下面重现的这个函数,它来自Zig 标准库的atomic.zig模块2 。
这个函数中还有很多东西我们还没有讨论,比如:comptime, inline, extern什么意思。让我们忽略所有这些事情,只关注这个函数内部的 switch 语句。
我们可以看到这个 switch 语句使用order对象作为输入。这个order对象是这个函数的输入之一fence(),并且我们可以在类型注释中看到,这个对象的类型是AtomicOrder。我们还可以在 switch 语句中看到一堆以点字符开头的值,例如.release和.acquire。
因为这些奇怪的值前面有一个点字符,所以我们要求zig编译器在 switch 语句中推断这些值的类型。然后,zig编译器会查看当前使用这些值的上下文,并尝试推断这些值的类型。
由于它们是在 switch 语句中使用,zig编译器会检查传递给 switch 语句的输入对象的类型,order在本例中是 object 。由于此对象的类型为AtomicOrder,zig编译器推断这些值是来自此类型的数据成员AtomicOrder。
pub inline fn fence(self: *Self, comptime order: AtomicOrder) void {
// many lines of code ...
if (builtin.sanitize_thread) {
const tsan = struct {
extern "c" fn __tsan_acquire(addr: *anyopaque) void;
extern "c" fn __tsan_release(addr: *anyopaque) void;
};
const addr: *anyopaque = self;
return switch (order) {
.unordered, .monotonic => @compileError(
@tagName(order)
++ " only applies to atomic loads and stores"
),
.acquire => tsan.__tsan_acquire(addr),
.release => tsan.__tsan_release(addr),
.acq_rel, .seq_cst => {
tsan.__tsan_acquire(addr);
tsan.__tsan_release(addr);
},
};
}
return @fence(order);
}
这就是 Zig 中基本类型推断的实现方式。如果我们在这个 switch 语句中的值前没有使用点字符,那么我们将被迫显式地写出这些值的数据类型。例如,.release我们不应该写成 ,而应该写成AtomicOrder.release。我们必须对这个 switch 语句中的每个值都执行此操作,这需要大量的工作。这就是为什么类型推断在 Zig 的 switch 语句中被广泛使用的原因。
2.5类型转换
在本节中,我想和大家讨论一下类型转换(type casting)。当我们有一个类型为“x”的对象,并且想要将其转换为类型为“y”的对象时,我们会使用类型转换,也就是说,我们想要改变该对象的数据类型。
大多数语言都有执行类型转换的正式方法。例如,在 Rust 中,我们通常使用关键字as;在 C 语言中,我们通常使用类型转换语法,例如 (int) x。在 Zig 中,我们使用@as()内置函数将类型为“x”的对象转换为类型为“y”的对象。
此@as()函数是在 Zig 中执行类型转换(或类型强制转换)的首选方法。因为它是显式的,并且只有在明确且安全的情况下才会执行强制转换。要使用此函数,只需在第一个参数中提供目标数据类型,并在第二个参数中提供要强制转换的对象。
const std = @import("std");
const expect = std.testing.expect;
test {
const x: usize = 500;
const y = @as(u32, x);
try expect(@TypeOf(y) == u32);
}
1/1 file3fc93b4ea641.test_0...OKAll 1 tests passed
d.
这是在 Zig 中执行类型转换的一般方法。但请记住,@as()只有当类型转换明确且安全时,才有效。在很多情况下,这些假设并不成立。例如,
当将整数值转换为浮点值或反之亦然时,编译器不清楚如何安全地执行此转换。
因此,在这种情况下,我们需要使用专门的“强制类型转换函数”。例如,如果要将整数值转换为浮点数,则应该使用@floatFromInt()函数。反之,则应该使用@intFromFloat()函数。
在这些函数中,你只需提供要强制类型转换的对象作为输入。然后,“类型转换操作”的目标数据类型由保存结果的对象的类型注释决定。在下面的示例中,我们将对象转换x为 类型的值f32,因为y保存结果的对象 被注释为 类型的对象f32。
const std = @import("std");
const expect = std.testing.expect;
test {
const x: usize = 565;
const y: f32 = @floatFromInt(x);
try expect(@TypeOf(y) == f32);
}
1/1 file3fc91795a712.test_0...OKAll 1 tests passed
d.
执行类型转换操作时非常有用的另一个内置函数是@ptrCast()。本质上,@as()当我们想要将 Zig 值/对象从类型“x”显式转换(或强制转换)为类型“y”等时,我们会使用内置函数。但是,指针(我们将在第 6 章更深入地讨论指针)是 Zig 中的一种特殊类型的对象,即,它们的处理方式与“普通对象”不同。
在 Zig 中,每当指针涉及某些“类型转换操作”时,@ptrCast()都会使用该函数。此函数的工作原理与 类似@floatFromInt()。您只需将要转换的指针对象作为输入提供给此函数,目标数据类型再次由存储结果的对象的类型注释决定。
const std = @import("std");
const expect = std.testing.expect;
test {
const bytes align(@alignOf(u32)) = [_]u8{
0x12, 0x12, 0x12, 0x12
};
const u32_ptr: *const u32 = @ptrCast(&bytes);
try expect(@TypeOf(u32_ptr) == *const u32);
}
1/1 file3fc945f8b4b0.test_0...OKAll 1 tests passed
d.
2.6模块
我们已经讨论了什么是模块,以及如何通过_import 语句_将其他模块导入到当前模块中。您在项目中编写的每个 Zig 模块(即.zig文件)在内部都存储为一个结构体对象。以下面显示的行为例。在这一行中,我们将 Zig 标准库导入到当前模块中。
const std = @import("std");
当我们想要访问标准库中的函数和对象时,我们实际上是在访问存储在std对象中的结构体的数据成员。因此,我们使用与普通结构体相同的语法,即点运算符 ( .) 来访问结构体的数据成员和方法。
当执行此“import 语句”时,此表达式的结果是一个包含 Zig 标准库模块、全局变量、函数等的结构对象。并且此结构对象被保存(或存储)在名为的常量对象内std。
以thread_pool.zig项目zap3中的模块为例。该模块的编写方式就像一个大型结构体。因此,我们init()在此模块中编写了一个顶级公共方法。其理念是,此模块中编写的所有顶级函数都是该结构体中的方法,所有顶级对象和结构体声明都是该结构体的数据成员。模块本身就是该结构体。
因此,您可以通过执行以下操作来导入和使用这个模块:
const std = @import("std");
const ThreadPool = @import("thread_pool.zig");
const num_cpus = std.Thread.getCpuCount()
catch @panic("failed to get cpu core count");
const num_threads = std.math.cast(u16, num_cpus)
catch std.math.maxInt(u16);
const pool = ThreadPool.init(
.{ .max_threads = num_threads }
);
-
https://github.com/ziglang/zig/blob/master/lib/std/debug.zig ↩︎
-
https://github.com/ziglang/zig/blob/master/lib/std/atomic.zig。↩︎
-
https://github.com/kprotty/zap/blob/blog/src/thread_pool.zig ↩︎
3 内存和分配器
在本章中,我们将讨论内存。Zig 如何控制内存?使用了哪些常用工具?Zig 的内存有哪些重要方面使其与众不同/特殊?您可以在这里找到答案。
计算机的运行从根本上依赖于内存。内存充当计算过程中生成的数据和值的临时存储空间。如果没有内存,编程语言中“变量”和“对象”这两个核心概念就无法实现。
3.1内存空间
您在 Zig 源代码中创建的每个对象都需要存储在计算机内存中的某个位置。根据您定义对象的位置和方式,Zig 将使用不同的“内存空间”或不同类型的内存来存储该对象。
每种类型的内存通常都有不同的用途。在 Zig 中,我们关心 3 种类型的内存(或 3 种不同的内存空间)。它们是:
- 全局数据寄存器(或“全局数据部分”);
- 栈;
- 堆;
3.1.1编译时已知与运行时已知
Zig 用于决定将声明的每个对象存储在何处的一种策略是查看该特定对象的值。更具体地说,是通过调查该值在“编译时”还是“运行时”已知。
当你用 Zig 编写程序时,程序中写入的某些对象的值 在编译时是已知的。这意味着,当你编译 Zig 源代码时,在编译过程中,zig编译器可以找出源代码中存在的特定对象的确切值。了解每个对象的长度(或大小)也很重要。因此,在某些情况下,程序中写入的每个对象的长度(或大小)在编译时是已知的。
编译zig器更关心的是特定对象的长度(或大小),而不是它的实际值。但是,如果zig编译器知道对象的值,那么它就自动知道该对象的大小。因为它可以通过查看值的大小来简单地计算出对象的大小。
因此,编译器的首要任务zig是发现源代码中每个对象的大小。如果在编译时已知该对象的值,那么zig编译器会自动知道该对象的大小/长度。但是,如果在编译时不知道该对象的值,那么只有当且仅当该对象的类型具有已知的固定大小时,编译器才能在编译时知道该对象的大小。
为了使类型具有已知的固定大小,该类型必须具有大小固定的数据成员。例如,如果此类型包含一个可变大小的数组,则该类型没有已知的固定大小。因为这个数组在运行时可以是任意大小(例如,它可以是一个包含 2 个元素的数组,或者 50 个元素的数组,或者 1000 个元素的数组,等等)。
例如,一个字符串对象,其内部是一个常量 u8 值数组([]const u8),其大小可变。它可以是一个包含 100 个或 500 个字符的字符串对象。如果我们在编译时不知道该字符串对象中存储的具体字符串,那么我们就无法在编译时计算该字符串对象的大小。因此,任何类型或任何结构体声明,如果包含一个没有明确固定大小的字符串数据成员,都会使该类型或您正在声明的这个新结构体成为编译时没有已知固定大小的类型。
相反,如果你声明的结构体类型包含一个数组数据成员,但该数组具有已知的固定大小,例如[60]u8(声明了一个包含 60 个u8值的数组),那么,该类型,或者说你声明的结构体,在编译时就变成了一个具有已知固定大小的类型。因此,在这种情况下,zig编译器在编译时不需要知道该类型任何对象的确切值。因为编译器可以通过查看其类型的大小来确定存储该对象所需的大小。
我们来看一个例子。在下面的源代码中,我们声明了两个常量对象(name和array)。由于这些特定对象的值在源代码本身("Pedro"以及从 1 到 4 的数字序列)中被记录下来,因此编译器可以在编译过程中轻松发现这些常量对象(name和array)zig的值。这就是“编译时已知”的含义。它指的是 Zig 源代码中任何可以在编译时识别其值的对象。
fn input_length(input: []const u8) usize {
const n = input.len;
return n;
}
pub fn main() !void {
const name = "Pedro";
const array = [_]u8{1, 2, 3, 4};
_ = name; _ = array;
}
另一种情况是,对象的值在编译时是未知的。函数参数就是一个典型的例子。因为每个函数参数的值都取决于调用函数时赋给该特定参数的值。
例如,函数input_length()包含一个名为 的参数input,它是一个由常量u8整数组成的数组([]const u8)。在编译时不可能知道这个特定参数的值。同样,也不可能知道这个特定参数的大小/长度。因为它是一个在参数类型注释中没有明确指定固定大小的数组。
所以,我们知道这个input参数是一个u8整数数组。但是在编译时,我们不知道它的值,也不知道它的大小。这些信息只有在运行时,也就是程序执行的时间段内才能知道。因此,表达式的值input.len也只有在运行时才知道。这是任何函数的固有特性。只需记住,函数参数的值通常不是“编译时已知的”。
然而,正如我之前提到的,编译器真正重要的是在编译时知道对象的大小,而不一定是它的值。所以,虽然我们在编译时不知道对象(即n表达式的结果)的值,input.len但我们知道它的大小。因为表达式input.len总是返回一个类型的值usize,而该类型usize具有已知的固定大小。
3.1.2全局数据寄存器
全局数据寄存器是 Zig 程序可执行文件的特定部分,负责存储编译时已知的任何值。
你在源代码中声明的每个常量对象(其值在编译时已知)都存储在全局数据寄存器中。此外,你在源代码中写入的每个字面值(例如字符串"this is a string"、整数10或布尔值true)也存储在全局数据寄存器中。
说实话,你不需要太在意这块内存空间。因为你无法控制它,你也无法故意访问它或将其用于你自己的目的。而且,这块内存空间不会影响你程序的逻辑。它只是存在于你的程序中。
3.1.3栈与堆
如果您熟悉系统编程,或者只是一般的低级编程,您可能听说过栈 (Stack) 与堆 (Heap) 之间的“决斗”。这是两种不同类型的内存,或者说是不同的内存空间,它们在 Zig 中都可以使用。
这两种内存实际上并不相互竞争。这是初学者在看到“x vs y”风格的小报标题时常犯的一个错误。这两种内存实际上是互补的。因此,在你编写的几乎每个 Zig 程序中,你都可能会同时使用这两种内存。我将在接下来的章节中详细描述每种内存空间。但现在,我只想明确这两种内存之间的主要区别。
本质上,栈内存通常用于存储长度固定且在编译时已知的值。相比之下,堆内存是一种 动态 类型的内存空间,这意味着它用于存储在程序执行期间(运行时)长度可能增长的值(Chen 和 Guo 2022)。
运行时增长的长度本质上与“运行时已知”类型的值相关。换句话说,如果你有一个对象,其长度可能在运行时增长,那么在编译时,该对象的长度将变得不可知。如果在编译时长度未知,那么在编译时,该对象的值也将变得不可知。这些类型的对象应该存储在堆内存空间中,这是一个动态内存空间,可以根据对象的大小进行增长或收缩。
3.1.4堆栈
栈是一种利用 栈数据结构 强大功能的内存,因此得名。栈是一种使用“后进先出”(LIFO)机制来存储传入值的 数据结构。我想你对这种数据结构应该很熟悉。但如果还不熟悉,维基百科 _第 1页或Geeks For Geeks 第2页都是非常实用且易于理解的资源,可以帮助你全面了解这种数据结构的工作原理。
因此,堆栈内存空间是一种使用堆栈数据结构存储值的内存。它遵循“后进先出”(LIFO)原则在内存中添加和删除值。
每次在 Zig 中进行函数调用时,堆栈中都会为此次特定的函数调用保留一定大小的空间(Chen 和 Guo 2022;Zig 软件基金会 2024)。此函数调用中传递给函数的每个函数参数的值都存储在此堆栈空间中。此外,在函数作用域内声明的每个局部对象通常也存储在同一个堆栈空间中。
看下面的例子,result对象是一个在add()函数作用域内声明的局部对象。因此,该对象存储在为add()函数保留的栈空间中。在add()函数作用域外声明的r对象也存储在栈中。但由于它是在“外部”作用域中声明的,因此该对象存储在属于该外部作用域的栈空间中。
fn add(x: u8, y: u8) u8 {
const result = x + y;
return result;
}
pub fn main() !void {
const r = add(5, 27);
_ = r;
}
因此,在函数作用域内声明的任何对象始终存储在为该特定函数保留的堆栈内存空间中。例如,在main()函数作用域内声明的任何对象也是如此。正如您所料,在这种情况下,它们存储在为该函数保留的堆栈空间中main()。
关于堆栈内存的一个非常重要的细节是它会自动释放。这一点非常重要,请记住。当对象存储在堆栈内存中时,您无需执行(或负责)释放/销毁这些对象。因为一旦函数作用域结束时堆栈空间被释放,它们就会被自动销毁。
因此,一旦函数调用返回(或者说结束,如果你愿意这样称呼它),栈中保留的空间就会被销毁,并且该空间中的所有对象也会随之消失。这种机制的存在是因为这个空间以及其中的对象不再需要了,因为函数“完成了它的任务”。以add()我们上面公开的函数为例,这意味着result一旦函数返回,对象就会被自动销毁。
重要的
存储在函数堆栈空间中的本地对象会在函数范围结束时自动释放/销毁。
同样的逻辑也适用于 Zig 中任何其他特殊结构,这些结构通过用花括号 ( {}) 括起来而拥有自己的作用域。例如,for 循环、while 循环、if else 语句等。例如,如果在 for 循环的范围内声明任何本地对象,则该本地对象只能在该特定 for 循环的范围内访问。因为一旦此 for 循环的作用域结束,堆栈中为此 for 循环保留的空间就会被释放。下面的示例演示了这个想法。
// This does not compile successfully!
const a = [_]u8{0, 1, 2, 3, 4};
for (0..a.len) |i| {
const index = i;
_ = index;
}
// Trying to use an object that was
// declared in the for loop scope,
// and that does not exist anymore.
std.debug.print("{d}\n", .{index});
这种机制的一个重要后果是,一旦函数返回,你就无法再访问堆栈中为该特定函数保留的空间内的任何内存地址。因为这个空间已经被销毁了。这意味着,如果这个本地对象存储在堆栈中,你就无法创建一个返回指向该对象的指针的函数。
想一想。如果栈中的所有局部对象在函数作用域结束时都被销毁,你为什么还要考虑返回指向这些对象之一的指针呢?这个指针充其量是无效的,或者更有可能是“未定义的”。
总而言之,编写一个返回本地对象本身作为结果的函数是完全没问题的,因为这样你返回的就是该对象的值。但是,如果这个本地对象存储在堆栈中,你永远不应该编写一个返回指向该本地对象的指针的函数。因为指针指向的内存地址已经不存在了。
因此,再次以该add()函数为例,如果你重写该函数,使其返回一个指向本地对象的指针result,zig编译器实际上会编译你的程序,而不会出现任何警告或错误。乍一看,这似乎是一段按预期运行的好代码。但这是个谎言!
如果您尝试查看对象内部的值r,或者尝试r在另一个表达式或函数调用中使用此对象,那么您将会出现未定义的行为,并且程序中会出现重大错误(Zig Software Foundation 2024,请参阅“生命周期和所有权” 3和“未定义行为” 4部分)。
fn add(x: u8, y: u8) *const u8 {
const result = x + y;
return &result;
}
pub fn main() !void {
// This code compiles successfully. But it has
// undefined behaviour. Never do this!!!
// The `r` object is undefined!
const r = add(5, 27); _ = r;
}
“指向堆栈变量的无效指针”问题在许多编程语言社区中都很常见。例如,如果你尝试在 C 或 C++ 程序中执行同样的操作(即返回存储在堆栈中的本地对象的地址),程序中也会出现未定义的行为。
重要的
如果函数中的局部对象存储在堆栈中,则永远不应从函数返回指向该局部对象的指针。因为函数返回后,该指针始终会变为 undefined,因为函数的堆栈空间在其作用域结束时会被销毁。
但是,如果函数返回后你确实需要以某种方式使用这个本地对象,该怎么办呢?该怎么做呢?答案是:“就像在 C 或 C++ 程序中一样。通过返回存储在堆中的对象的地址”。堆内存的生命周期更加灵活,并且允许你获取指向已从其作用域返回的函数的本地对象的有效指针。
3.1.5堆
栈的一个重要限制是,只有在编译时已知长度/大小的对象才能存储在其中。相比之下,堆是一种更加动态(且灵活)的内存类型。对于在程序执行过程中大小/长度可能增长的对象来说,堆是理想的内存类型。
几乎任何充当服务器的应用程序都是堆的经典用例。HTTP 服务器、SSH 服务器、DNS 服务器、LSP 服务器……任何类型的服务器。总而言之,服务器是一种长时间运行的应用程序,它负责处理(或“处理”)到达该特定服务器的任何传入请求。
对于这类系统来说,堆是一个不错的选择,主要是因为服务器在运行期间无法预先知道会收到多少用户请求。这些请求可能是单个请求,也可能是 5000 个请求,甚至可能是零个请求。服务器需要能够根据收到的请求数量来分配和管理内存。
栈和堆之间的另一个关键区别是,堆是一种由程序员完全控制的内存类型。这使得堆成为一种更灵活的内存类型,但也使其更难使用。因为程序员需要负责管理与之相关的一切,包括内存分配的位置、分配的内存量以及释放内存的位置。
与栈内存不同,堆内存由程序员明确分配,并且直到明确释放时才会被释放(Chen 和 Guo 2022)。
要将对象存储在堆中,程序员需要明确地告诉 Zig 这样做,方法是使用分配器在堆中分配一些空间。在第 3.3 节中,我将介绍如何在 Zig 中使用分配器分配内存。
重要的
您在堆中分配的每个内存都需要由程序员明确释放。
Zig 中的大多数分配器确实在堆上分配内存。但此规则的一些例外是ArenaAllocator()和FixedBufferAllocator()。ArenaAllocator()是一种特殊类型的分配器,可与第二种类型的分配器协同工作。另一方面,FixedBufferAllocator()是一种基于在堆栈上创建的缓冲区对象工作的分配器。这意味着FixedBufferAllocator()仅在堆栈上进行分配。
3.1.6总结
在讨论了所有这些无聊的细节之后,我们可以快速回顾一下我们所学到的内容。总而言之,Zig 编译器将使用以下规则来决定声明的每个对象的存储位置:
- 每个文字值(例如
"this is string"、10或true)都存储在全局数据部分中。 - 每个在编译时已知的
const常量对象( )也存储在全局数据部分中。 - 每个在编译时已知长度/大小的对象(无论是否为常量)都存储在当前范围的堆栈空间中。
- 如果使用分配器对象的方法
alloc()或create()方法创建对象,则该对象将存储在该特定分配器对象使用的内存空间中。Zig 中大多数可用的分配器都使用堆内存,因此,该对象很可能存储在堆中(FixedBufferAllocator()这是例外)。 - 堆只能通过分配器访问。如果你的对象不是通过分配器对象的
alloc()或create()方法创建的,那么它肯定不是存储在堆中的对象。
3.2堆栈溢出
在栈上分配内存通常比在堆上分配内存更快。但这种更好的性能也伴随着许多限制。我们已经在3.1.4 节中讨论过栈的许多限制。但还有一个更重要的限制我想谈谈,那就是栈本身的大小。
栈的大小是有限制的。不同计算机的栈大小有所不同,并且取决于很多因素(例如计算机架构、操作系统等等)。不过,栈的大小通常不会很大。这就是为什么我们通常只使用栈来存储内存中的临时对象和小对象。
本质上,如果你尝试在堆栈上分配空间,而空间过大,超出了堆栈大小的限制,就会发生 堆栈溢出,程序就会因此崩溃。换句话说,当你尝试使用超过堆栈可用空间时,就会发生堆栈溢出。
这类问题与 缓冲区溢出 非常相似,即你试图使用超出“缓冲区对象”可用空间的内存。然而,堆栈溢出总是会导致程序崩溃,而缓冲区溢出并不总是会导致程序崩溃(尽管它经常会崩溃)。
您可以在下面的示例中看到堆栈溢出的示例。我们尝试u64在堆栈上分配一个非常大的数组。您可以在下面看到该程序无法成功运行,因为它崩溃了,并出现了“段错误”错误消息。
var very_big_alloc: [1000 * 1000 * 24]u64 = undefined;
@memset(very_big_alloc[0..], 0);
Segmentation fault (core dumped)
这个段错误是由于在栈上分配了过大的内存来存储very_big_alloc对象,从而导致栈溢出而引起的。这就是为什么非常大的对象通常存储在堆上,而不是栈上。
3.3分配器
Zig 的一个关键方面是,Zig 中“没有隐藏的内存分配”。这实际上意味着“标准库中不会在你背后进行任何分配” ( Sobeston 2024 )。
这是一个已知问题,尤其是在 C++ 中。因为在 C++ 中,有些操作符会在后台分配内存,而你无法知道这一点,除非你真正阅读这些操作符的源代码,找到内存分配调用。许多程序员觉得这种行为很烦人,而且很难跟踪。
但是,在 Zig 中,如果函数、运算符或标准库中的任何内容在执行期间需要分配一些内存,那么该函数/运算符需要接收(作为输入)用户提供的分配器,才能真正分配所需的内存。
这就明确区分了“不分配”内存的函数和“实际分配”内存的函数。只需查看这个函数的参数即可。如果一个函数或运算符将分配器对象作为其输入/参数之一,那么你肯定知道这个函数/运算符在执行期间会分配一些内存。
一个例子是allocPrint()Zig 标准库中的函数。使用此函数,您可以使用格式说明符编写一个新字符串。因此,此函数与sprintf()C 语言中的函数非常相似。为了编写这样的新字符串,该allocPrint()函数需要分配一些内存来存储输出字符串。
这就是为什么,此函数的第一个参数是一个分配器对象,您(用户/程序员)将其作为函数的输入。在下面的示例中,我使用GeneralPurposeAllocator()作为我的分配器对象。但我可以轻松使用Zig标准库中的任何其他类型的分配器对象。
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
const name = "Pedro";
const output = try std.fmt.allocPrint(
allocator,
"Hello {s}!!!",
.{name}
);
try stdout.print("{s}\n", .{output});
Hello Pedro!!!
您可以很好地控制此函数可以分配的内存位置和大小。因为是您(用户/程序员)提供了该函数使用的分配器。这使得在 Zig 中更容易实现对内存管理的“完全控制”。
3.3.1什么是分配器?
Zig 中的分配器是可用于为程序分配内存的对象。它们类似于 C 语言中的内存分配函数,例如malloc()和calloc()。因此,如果您需要使用比最初拥有的更多的内存,那么在程序执行期间,您只需使用分配器对象即可请求更多内存。
Zig 提供不同类型的分配器,它们通常可通过std.heap标准库模块获取。因此,只需将 Zig 标准库导入到您的 Zig 模块中(使用@import("std")),即可在代码中开始使用这些分配器。
此外,每个分配器对象都构建在 Zig 的接口之上Allocator。这意味着,您在 Zig 中找到的每个分配器对象都必须具有方法alloc()、create()和。因此,您可以更改正在使用的分配器类型,但无需更改对执行程序内存分配(和释放内存操作)free()的destroy()方法的函数调用。
3.3.2为什么需要分配器?
正如我们在3.1.4 节中所述,每次在 Zig 中进行函数调用时,堆栈中都会为该函数调用保留一个空间。但是堆栈有一个关键的限制:存储在堆栈中的每个对象都有已知的固定长度。
但实际上,有两种非常常见的情况,堆栈的这种“固定长度限制”会成为交易破坏因素:
- 您在函数内部创建的对象可能会在函数执行期间增大。
- 有时,我们不可能预先知道会收到多少输入,或者输入有多大。
另外,还有另一种情况可能需要使用分配器,那就是当您想要编写一个返回指向本地对象的指针的函数时。正如我在3.1.4 节中所述,如果此本地对象存储在栈中,则无法执行此操作。但是,如果此对象存储在堆中,则可以在函数末尾返回指向此对象的指针。因为您(程序员)控制着您分配的任何堆内存的生命周期。您可以决定何时销毁/释放这块内存。
这些是堆栈不适用的常见情况。因此,您需要一种不同的内存管理策略来在函数内部存储这些对象。您需要使用一种可以随对象一起增长的内存类型,或者可以控制该内存的生命周期。堆就符合这种描述。
在堆上分配内存通常称为动态内存管理。随着程序执行过程中创建的对象大小不断增长,您可以通过在堆中分配更多内存来存储这些对象,从而增加内存量。在 Zig 中,您可以使用分配器对象来实现这一点。
3.3.3不同类型的分配器
在撰写本书时,在 Zig 中,标准库中有 6 种不同的分配器可用:
GeneralPurposeAllocator()。page_allocator()。FixedBufferAllocator()和ThreadSafeFixedBufferAllocator()。ArenaAllocator()。c_allocator()(需要您链接到 libc)。
每个分配器都有其自身的优势和局限性。除FixedBufferAllocator()和 之外的所有ArenaAllocator()分配器都使用堆内存。因此,使用这些分配器分配的任何内存都将放置在堆中。
3.3.4通用分配器
GeneralPurposeAllocator()顾名思义,它是一个“通用”分配器。你可以用它来完成各种类型的任务。在下面的例子中,我为对象分配了足够的空间来存储一个整数some_number。
const std = @import("std");
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
const some_number = try allocator.create(u32);
defer allocator.destroy(some_number);
some_number.* = @as(u32, 45);
}
虽然有用,但您可能希望使用c_allocator(),它是 C 标准分配器 的别名malloc()。所以,是的,malloc()如果您愿意,您可以在 Zig 中使用。只需使用c_allocator()Zig 标准库中的 即可。但是,如果您确实使用了c_allocator(),则必须在使用编译器编译源代码时链接到 Libc zig,方法是在编译过程中包含该标志-lc。如果您不将源代码链接到 Libc,Zig 将无法malloc()在您的系统中找到该实现。
3.3.5页面分配器
是一个page_allocator()在堆中分配整页内存的分配器。换句话说,每次使用 分配内存时page_allocator(),都会分配堆中的整页内存,而不是其中的一小部分。
此页的大小取决于您使用的系统。大多数系统在堆中使用 4KB 的页大小,因此,这通常是每次调用时分配的内存量page_allocator()。这就是为什么page_allocator()在 Zig 中,它被认为是一个快速但“浪费”的分配器。因为它在每次调用中都会分配大量内存,而您的程序很可能不需要那么多内存。
3.3.6缓冲区分配器
FixedBufferAllocator()和是分配器ThreadSafeFixedBufferAllocator()对象,它们与后端固定大小的缓冲区对象协同工作。换句话说,它们使用固定大小的缓冲区对象作为内存的基础。当您请求这些分配器对象为您分配内存时,它们实际上是在这个固定大小的缓冲区对象中预留了一些空间供您使用。
这意味着,为了使用这些分配器,您必须首先在代码中创建一个缓冲区对象,然后将该缓冲区对象作为输入提供给这些分配器。
这也意味着,这些分配器对象既可以在栈中分配内存,也可以在堆中分配内存。一切都取决于你提供的缓冲区对象的位置。如果这个缓冲区对象位于栈中,那么分配的内存就是“基于栈的”。但如果它位于堆中,那么分配的内存就是“基于堆的”。
在下面的例子中,我buffer在堆栈上创建了一个长度为 10 个元素的对象。注意,我将这个buffer对象赋给了FixedBufferAllocator()构造函数。由于这个buffer对象的长度为 10 个元素,这意味着我只能使用这个空间。我无法用这个分配器对象分配超过 10 个元素。如果我尝试分配超过 10 个元素,该alloc()方法将返回OutOfMemory错误值。
var buffer: [10]u8 = undefined;
for (0..buffer.len) |i| {
buffer[i] = 0; // Initialize to zero
}
var fba = std.heap.FixedBufferAllocator.init(&buffer);
const allocator = fba.allocator();
const input = try allocator.alloc(u8, 5);
defer allocator.free(input);
请记住,这些分配器对象分配的内存可以来自堆栈,也可以来自堆。这完全取决于你提供的缓冲区对象所在的位置。在上面的例子中,对象buffer位于堆栈中,因此分配的内存基于堆栈。但如果它基于堆呢?
正如我们在3.2 节中所述,使用堆而不是栈的主要原因之一是需要分配大量空间来存储非常大的对象。因此,假设您想使用一个非常大的缓冲区对象作为分配器对象的基础。您必须在堆上分配这个非常大的缓冲区对象。下面的示例演示了这种情况。
const heap = std.heap.page_allocator;
const memory_buffer = try heap.alloc(
u8, 100 * 1024 * 1024 // 100 MB memory
);
defer heap.free(memory_buffer);
var fba = std.heap.FixedBufferAllocator.init(
memory_buffer
);
const allocator = fba.allocator();
const input = try allocator.alloc(u8, 1000);
defer allocator.free(input);
3.3.7竞技场分配器
是ArenaAllocator()一个分配器对象,它接受一个子分配器作为输入。Zig 中 背后的理念ArenaAllocator()类似于编程语言 Go 5中“arena”的概念。它是一个分配器对象,允许您分配任意多次内存,但所有内存只能释放一次。换句话说,例如,如果您调用了 5 次某个对象的alloc()方法,那么只需调用同一ArenaAllocator()对象的deinit()方法,就可以一次性释放在这 5 次调用中分配的ArenaAllocator()所有内存。
例如,如果你像下面的例子一样,将一个GeneralPurposeAllocator()对象作为ArenaAllocator()构造函数的输入,那么你执行的分配操作实际上将由传入的底层对象进行。因此,使用竞技场分配器GeneralPurposeAllocator(),你请求的任何新内存都由子分配器分配alloc()。竞技场分配器GeneralPurposeAllocator()真正能做的唯一一件事就是帮助你用一个命令释放所有多次分配的内存。在下面的例子中,我调用了alloc()3 次。所以,如果我没有使用竞技场分配器,那么我需要调用free()3 次才能释放所有分配的内存。
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
var aa = std.heap.ArenaAllocator.init(gpa.allocator());
defer aa.deinit();
const allocator = aa.allocator();
const in1 = try allocator.alloc(u8, 5);
const in2 = try allocator.alloc(u8, 10);
const in3 = try allocator.alloc(u8, 15);
_ = in1; _ = in2; _ = in3;
3.3.8和方法alloc()free()
在下面的代码示例中,我们访问stdin标准输入通道 ,以接收来自用户的输入。我们使用 方法来读取用户的输入readUntilDelimiterOrEof()。
现在,读取用户的输入后,我们需要将其存储在程序的某个位置。因此,我在本例中使用了分配器。我使用它来分配一定量的内存来存储用户提供的输入。更具体地说,alloc()分配器对象的方法用于分配一个可存储 50 个u8值的数组。
请注意,此alloc()方法接收两个输入。第一个参数是类型。它定义了分配的数组将存储什么类型的值。在下面的示例中,我们分配了一个无符号 8 位整数数组(u8)。但您可以创建一个数组来存储任何类型的值。接下来,在第二个参数中,我们通过指定此数组将包含多少个元素来定义分配数组的大小。在下面的示例中,我们分配了一个包含 50 个元素的数组。
在1.8 节中,我们描述了 Zig 中的字符串只是字符数组。每个字符都由一个u8值表示。因此,这意味着在对象中分配的数组input能够存储长度为 50 个字符的字符串。
因此,本质上,该表达式var input: [50]u8 = undefined将在当前作用域的堆栈中创建一个包含 50 个值的数组u8。但是,您可以使用表达式在堆中分配相同的数组var input = try allocator.alloc(u8, 50)。
const std = @import("std");
const stdin = std.io.getStdIn();
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var input = try allocator.alloc(u8, 50);
defer allocator.free(input);
for (0..input.len) |i| {
input[i] = 0; // initialize all fields to zero.
}
// read user input
const input_reader = stdin.reader();
_ = try input_reader.readUntilDelimiterOrEof(
input,
'\n'
);
std.debug.print("{s}\n", .{input});
}
另外,请注意,在此示例中,我们使用defer关键字(我在2.1.3 节中描述过)在当前作用域的末尾运行一小段代码,即表达式allocator.free(input)。执行此表达式时,分配器将释放它为input对象分配的内存。
我们在3.1.5 节中讨论过这个问题。你应该始终明确地释放使用分配器分配的任何内存!你可以使用free()分配此内存时使用的分配器对象的方法来执行此操作。defer本例中使用关键字只是为了帮助我们在当前作用域的末尾执行此释放操作。
3.3.9和方法create()destroy()
使用alloc()和free()方法,你可以分配内存来一次存储多个元素。换句话说,使用这些方法,我们总是分配一个数组来一次存储多个元素。但是,如果你只需要足够的空间来存储单个元素怎么办?你应该通过 分配一个包含单个元素的数组吗alloc()?
答案是否定的!在这种情况下,您应该使用create()分配器对象的方法。每个分配器对象都提供create()和destroy()方法,分别用于为单个项目分配和释放内存。
因此,本质上,如果您想分配内存来存储元素数组,则应该使用alloc()和free()。但是,如果您只需要存储单个项目,那么create()和destroy()方法是理想的选择。
在下面的例子中,我定义了一个结构体来表示某种类型的用户。它可以是游戏的用户,也可以是管理资源的软件,都可以。请注意,这次我使用了方法,在程序中create()存储单个对象。还要注意,我使用了方法在作用域结束时释放此对象占用的内存。User``destroy()
const std = @import("std");
const User = struct {
id: usize,
name: []const u8,
pub fn init(id: usize, name: []const u8) User {
return .{ .id = id, .name = name };
}
};
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
const user = try allocator.create(User);
defer allocator.destroy(user);
user.* = User.init(0, "Pedro");
}
-
https://ziglang.org/documentation/master/#Lifetime-and-Ownership ↩︎
-
https://ziglang.org/documentation/master/#Undefined-Behavior ↩︎
4 项目 1 - 构建 base64 编码器/解码器
作为我们的第一个小项目,我想和你一起实现一个 Base64 编码器/解码器。Base64 是一种将二进制数据转换为文本的编码系统。网络上很大一部分使用 Base64 将二进制数据传输到只能读取文本数据的系统。
现代 base64 最常见的用例基本上是任何电子邮件系统,例如 GMail、Outlook 等。因为电子邮件系统通常使用简单邮件传输协议 (SMTP),这是一种仅支持文本数据的 Web 协议。因此,如果您出于任何原因需要将二进制文件(例如 PDF 或 Excel 文件)作为电子邮件附件发送,这些二进制文件通常会先转换为 base64 编码,然后再包含在 SMTP 消息中。因此,这些电子邮件系统广泛使用 base64 编码来将二进制数据包含在 SMTP 消息中。
4.1 base64算法如何工作?
但是 Base64 编码背后的算法究竟是如何工作的呢?让我们来讨论一下。首先,我将解释一下 Base64 的标度,也就是 64 个字符的标度,它是 Base64 编码系统的基础。
之后,我会解释 base64 编码器背后的算法,它是算法的一部分,负责将消息编码到 base64 编码系统中。之后,我会解释 base64 解码器背后的算法,它是算法的一部分,负责将 base64 消息翻译回其原始含义。
如果您不确定“编码器”和“解码器”之间的区别,请参阅第 4.2 节。
4.1.1 base64 缩放比例
Base64 编码系统基于 0 到 63 的数值范围(因此得名)。该范围中的每个索引都由一个字符表示(即 64 个字符的数值范围)。因此,为了将二进制数据转换为 Base64 编码,我们需要将每个二进制数转换为该“64 个字符的数值范围”中对应的字符。
base64 编码的标度以全部 ASCII 大写字母(A 到 Z)开头,代表该标度的前 25 个索引(0 到 25)。之后,全部 ASCII 小写字母(a 到 z),代表标度中的 26 到 51 的范围。之后,是一位数(0 到 9),代表标度中的 52 到 61 的索引。最后,标度中的最后两个索引(62 和 63)分别用字符+和表示/。
这些是组成 base64 标度的 64 个字符。等号 ( =) 本身不属于标度,但它是 base64 编码系统中的特殊字符。此字符仅用作后缀,用于标记字符序列的结束,或者标记序列中有意义字符的结束。
以下要点总结了 base64 的比例:
- 范围 0 到 25 表示为:ASCII 大写字母
-> [A-Z]; - 范围 26 到 51 表示为:ASCII 小写字母
-> [a-z]; - 范围 52 至 61 表示为:一位数
-> [0-9]; - 索引 62 和 63 分别用字符
+和表示/; - 该字符
=表示序列中有意义字符的结束;
4.1.2创建查找表形式的量表
在代码中表示此比例的最佳方法是将其表示为_查找表_。查找表是计算机科学中加速计算的经典策略。其基本思想是用基本的数组索引操作替换运行时计算(这可能需要很长时间才能完成)。
您无需每次需要时都计算结果,而是一次性计算所有可能的结果,然后将它们存储在一个数组(其行为类似于“表”)中。这样,每次需要使用 Base64 编码的某个字符时,无需耗费大量资源来计算要使用的确切字符,只需从存储了所有 Base64 编码可能字符的数组中检索该字符即可。我们直接从内存中检索所需的字符。
我们可以开始构建一个 Zig 结构体来存储我们的 Base64 解码器/编码器逻辑。我们从Base64下面的结构体开始。目前,该结构体中只有一个数据成员,即成员_table,它代表我们的查找表。我们还有一个init()方法,用于创建对象的新实例Base64,以及一个_char_at()方法,用于“获取索引处的字符”。x”类型的函数。
const Base64 = struct {
_table: *const [64]u8,
pub fn init() Base64 {
const upper = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
const lower = "abcdefghijklmnopqrstuvwxyz";
const numbers_symb = "0123456789+/";
return Base64{
._table = upper ++ lower ++ numbers_symb,
};
}
pub fn _char_at(self: Base64, index: usize) u8 {
return self._table[index];
}
};
换句话说,该_char_at()方法负责获取查找表(即_table结构体数据成员)中与“base64 编码”中特定索引对应的字符。因此,在下面的例子中,我们知道与“base64 编码”中索引 28 对应的字符是字符“c”。
const base64 = Base64.init();
try stdout.print(
"Character at index 28: {c}\n",
.{base64._char_at(28)}
);
Character at index 28: c
4.1.3 base64编码器
Base64 编码器背后的算法通常作用于 3 个字节的窗口。由于每个字节有 8 位,因此 3 个字节构成一组8×3=24位。这对于 base64 算法来说是理想的,因为 24 位可以被 6 整除,从而形成24/6=4每组 6 位。
因此,base64 算法的工作原理是每次将 3 个字节转换为 4 个 base64 字符。它会不断迭代输入字符串,每次 3 个字节,并将其转换为 base64 字符,每次迭代产生 4 个字符。它会不断迭代,不断产生这些“新字符”,直到到达输入字符串的末尾。
现在你可能会想,如果你有一个特定的字符串,其字节数不能被 3 整除,会发生什么?例如,如果你有一个只包含两个字符/字节的字符串,例如“Hi”。在这种情况下,算法会如何表现?你可以在图 4.1中找到答案。你可以在图 4.1中看到,字符串“Hi”在转换为 base64 后变成了字符串“SGk=”:
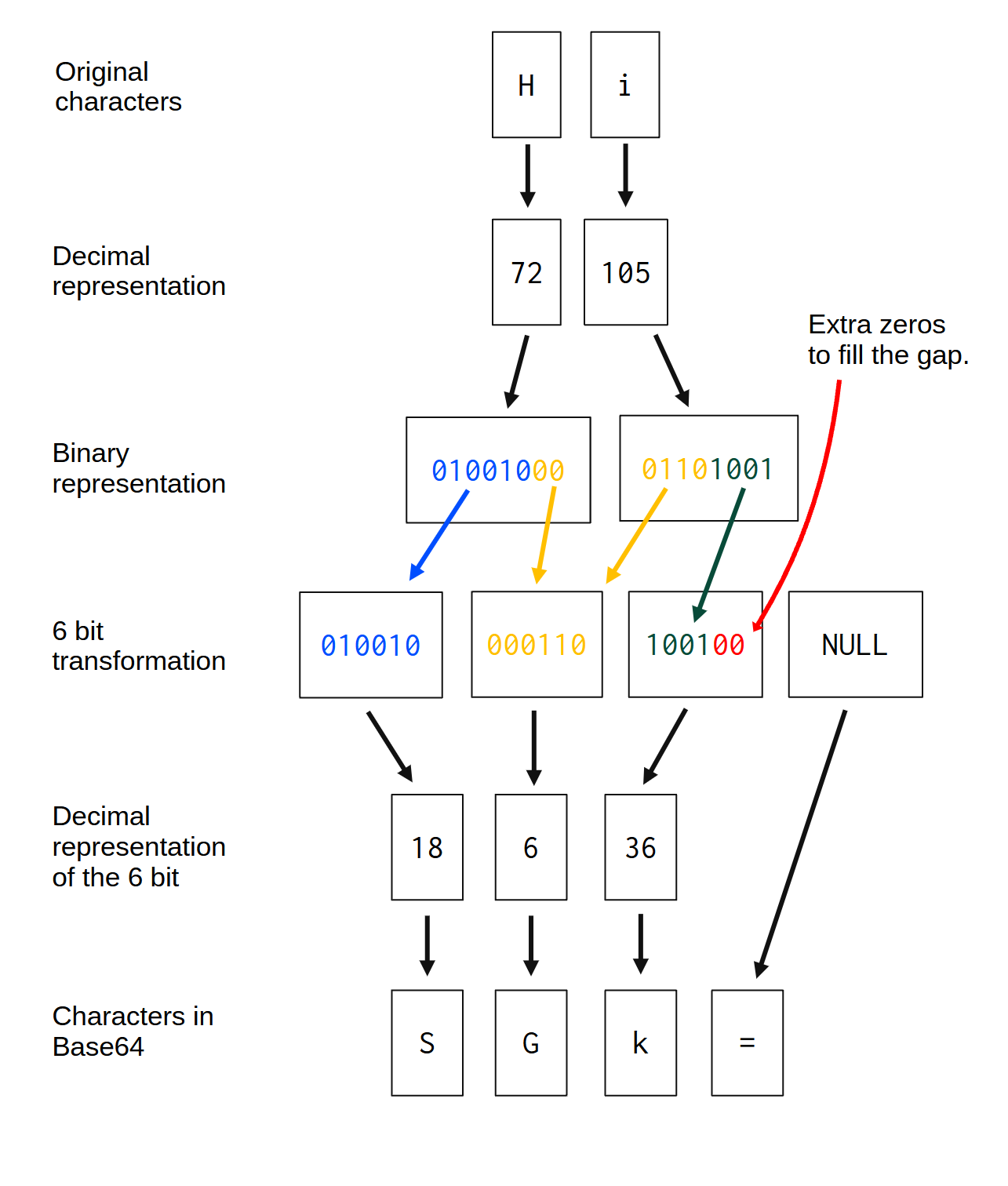
图 4.1:base64 编码器背后的逻辑
以字符串“Hi”为例,它有 2 个字节,也就是 16 位。因此,我们缺少一个完整的字节(8 位)来填充 base64 算法所需的 24 位窗口。该算法首先会检查如何将输入字节分成 6 位一组。
如果算法注意到有一组 6 位不完整,这意味着该组包含nb我吨秒, 在哪里0<nb我吨秒<6,
算法只是在这个组中额外添加一些零来填补所需的空间。这就是为什么在图 4.1中,经过 6 位变换后的第三组中,额外添加了 2 个零来填补空缺。
当一个 6 位组未完全填满时(例如第三个组),会添加额外的零来填补空缺。但是,如果整个 6 位组都为空,或者根本就不存在,该怎么办呢?图 4.1所示的第四个 6 位组就属于这种情况。
第四组是必需的,因为该算法处理 4 组 6 位数据。但输入字符串没有足够的字节来创建第四组 6 位数据。每当整个 6 位数据组为空时,该组就会变成“填充组”。每个“填充组”都会映射到字符=(等号),该字符表示“空”,或者序列中有意义字符的结尾。因此,每当算法生成一个“填充组”时,该组都会自动映射到=。
再举一个例子,如果将字符串“0”作为base64编码器的输入,该字符串将被转换为base64序列“MA==”。字符“0”的二进制表示为序列001100001 。因此,按照图 4.1所示的6位转换,这个字符将产生两个6位组:001100,000000。剩下的两个6位组成为“填充组”。这就是为什么输出序列(MA==)中的最后两个字符是==。
4.1.4 base64解码器
Base64 解码器背后的算法本质上是 Base64 编码器的逆过程。Base64 解码器需要将 Base64 消息转换回其原始含义,即原始的二进制数据序列。
Base64 解码器通常处理 4 个字节的窗口。因为它需要将这 4 个字节转换回原始的 3 个字节序列,而原始的 3 个字节序列又被 Base64 编码器转换成了 4 组 6 位数据。记住,在 Base64 解码器中,我们实际上是在还原 Base64 编码器的转换过程。
输入字符串(base64 编码的字符串)中的每个字节通常会在输出(原始二进制数据)中重新创建两个不同的字节。换句话说,base64 解码器输出的每个字节都是通过将输入中的两个不同字节进行变换或合并而生成的。您可以在图 4.2中直观地看到这种关系:
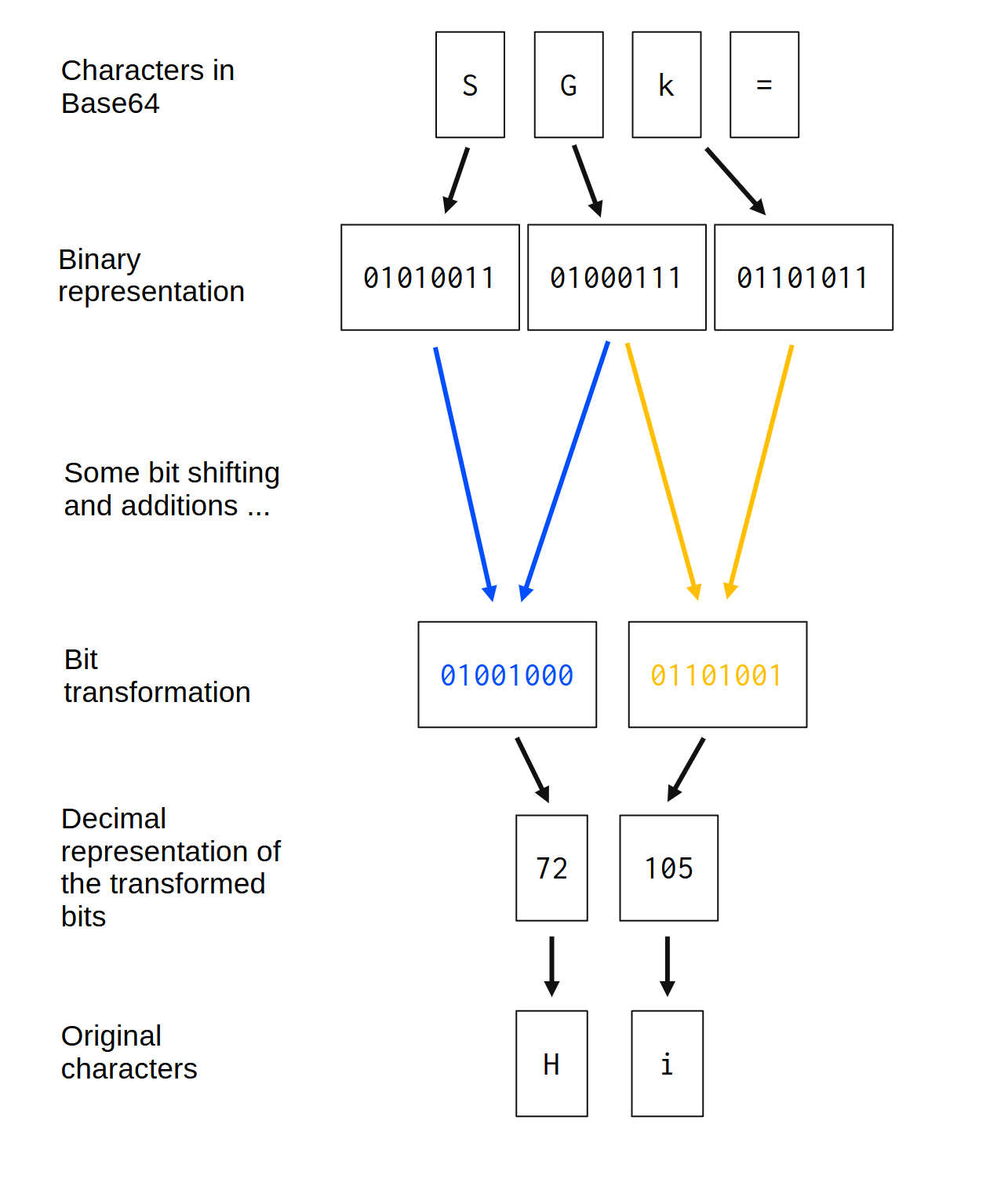
图 4.2:base64 解码器背后的逻辑
确切的转换,或者说,对输入中的每个字节应用到输出字节的具体步骤,在这样的图中很难直观地展现。因此,我在图中将这些转换概括为“一些位移位和加法……”。这些转换将在稍后深入描述。
除此之外,如果你再次查看图 4.2,你会注意到该字符=被算法完全忽略了。记住,这只是一个特殊字符,用于标记 base64 序列中有意义字符的结尾。因此,=base64 编码序列中的每个字符都应该被 base64 解码器忽略。
4.2编码和解码的区别
如果您以前没有使用过 Base64,您可能无法理解“编码”和“解码”之间的区别。本质上,这里的“编码”和“解码”与加密领域中的含义完全相同(即,它们与哈希算法(例如 MD5 算法)中的“编码”和“解码”含义相同)。
因此,“encode” 表示我们要进行编码,或者换句话说,我们要将一些消息转换为 base64 编码系统。我们希望生成一个 base64 字符序列,以在 base64 编码系统中表示原始消息。
相反,“解码”代表逆过程。我们希望解码,或者换句话说,将 Base64 消息转换回其原始内容。因此,在这个过程中,我们输入一个 Base64 字符序列,并输出由该 Base64 字符序列表示的二进制数据。
任何 base64 库通常由以下两部分组成:1)编码器,它是将任何二进制数据序列编码(即转换)为 base64 字符序列的函数;2)解码器,它是将 base64 字符序列转换回原始二进制数据序列的函数。
4.3计算输出的大小
我们需要做的一项任务是计算需要为编码器和解码器的输出预留多少空间。这是一个简单的数学问题,可以在 Zig 中轻松完成,因为每个数组的长度(元素数量)都可以通过查询.len数组的属性轻松访问。
对于编码器来说,其逻辑如下:输入中每出现 3 个字节,输出中就会产生 4 个新字节。因此,我们将输入的字节数除以 3,使用一个上限函数,然后将结果乘以 4。这样,我们就得到了编码器输出的总字节数。
下面的函数_calc_encode_length()封装了这个逻辑。在这个函数中,我们获取输入数组的长度,将其除以 3,然后使用divCeil()Zig 标准库中的函数对结果进行 ceil 运算。最后,我们将最终结果乘以 4 即可得到所需的答案。
另外,你可能已经注意到,如果输入长度小于 3 个字节,那么编码器的输出长度始终为 4 个字节。对于所有小于 3 个字节的输入都是如此,因为正如我在4.1.3 节中所述,该算法在最终结果中始终会生成足够多的“填充组”,以填满 4 个字节的窗口。
const std = @import("std");
fn _calc_encode_length(input: []const u8) !usize {
if (input.len < 3) {
return 4;
}
const n_groups: usize = try std.math.divCeil(
usize, input.len, 3
);
return n_groups * 4;
}
现在,计算解码器输出长度的逻辑稍微复杂一些。但它基本上就是我们在编码器中使用的逻辑的逆:输入中每 4 个字节,解码器就会输出 3 个字节。然而,这次我们需要考虑字符,正如我们在4.1.4 节和图 4.2=中所述,它总是被解码器忽略。
本质上,我们取输入的长度并将其除以 4,然后对结果应用向下取整函数,然后将结果乘以 3,然后从结果中减去=在输入中找到该字符的次数。
下面展示的函数_calc_decode_length()总结了我们之前描述的逻辑。它类似于函数_calc_encode_length()。请注意,除法部分有所不同。还要注意,这次我们使用divFloor()函数对除法的输出进行了向下取整运算(而不是使用 进行向上取整运算divCeil())。
const std = @import("std");
fn _calc_decode_length(input: []const u8) !usize {
if (input.len < 4) {
return 3;
}
const n_groups: usize = try std.math.divFloor(
usize, input.len, 4
);
var multiple_groups: usize = n_groups * 3;
var i: usize = input.len - 1;
while (i > 0) : (i -= 1) {
if (input[i] == '=') {
multiple_groups -= 1;
} else {
break;
}
}
return multiple_groups;
}
4.4构建编码器逻辑
在本节中,我们将开始构建函数背后的逻辑encode(),该函数将负责将消息编码到 base64 编码系统中。如果您急切地想查看这个 base64 编码器/解码器的完整实现源代码,您可以在本书官方仓库的文件夹中找到ZigExamples它。
4.4.1 6位变换
图 4.1中所示的 6 位变换是 base64 编码器算法的核心部分。通过理解代码中如何实现这一变换,算法的其余部分将变得更容易理解。
本质上,这种 6 位转换是借助位运算符完成的。位运算符对于任何类型的位级低级运算都至关重要。对于 Base64 算法,需要使用位左移( <<)、位右移( >>) 和_位与_( &) 运算符。它们是 6 位转换的核心解决方案。
在这个转换过程中,我们需要考虑三种不同的情况。首先,是理想情况,即我们有一个包含 3 个字节的理想窗口可供处理。其次,是只有 2 个字节的窗口可供处理。最后,是只有一个字节的窗口可供处理。
在这三种情况下,6 位转换的工作原理略有不同。为了便于解释,我将使用 变量output引用 base64 编码器输出的字节,使用 变量input引用编码器输入的字节。
因此,如果您有 3 个字节的完美窗口,则以下是 6 位转换的步骤:
output[0]是通过将位从input[0]两个位置向右移动而生成的。output[1]通过将两个分量相加而得出。首先,取其中的最后两位input[0],然后将其向左移动四位。然后,将这input[1]四位向右移动。将这两个分量相加。output[2]通过将两个分量相加而得出。首先,从中取出最后四位input[1],然后将它们向左移动两位。然后,将这input[2]六位向右移动。将这两个分量相加。output[3]是通过从中取出最后六位生成的input[2]。
这是最理想的情况,我们有一个包含 3 个字节的完整窗口可供处理。为了尽可能清晰地说明,图 4.3以直观的方式演示了上述步骤 2 的工作原理。因此,output编码器中的第二个字节是通过从输入中取出第一个字节(深紫色)和第二个字节(橙色)生成的。您可以看到,在处理结束时,我们得到了一个新字节,它包含 中第一个字节的后 2 位input以及 中第二个字节的前 4 位input。
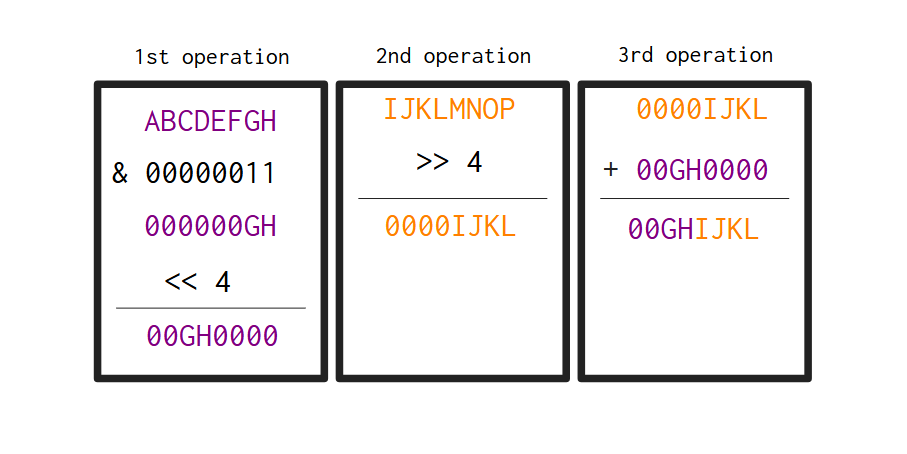
图 4.3:编码器输出中的第 2 个字节是如何由输入的第 1 个字节(深紫色)和第 2 个字节(橙色)产生的。
另一方面,我们必须为没有完美 3 字节窗口的情况做好准备。如果窗口大小为 2 字节,那么步骤 3 和 4(即产生字节output[2]和output[3])会略有变化,最终变成:
output[2]是通过从中取出最后 4 位input[1],然后将它们向左移动两个位置而得到的。output[3]是角色'='。
最后,如果您有一个单字节窗口,则步骤 2 至 4 将产生字节output[1],output[2]并output[3]发生变化,变为:
output[1]是通过从中取出最后两位input[0],然后将它们向左移动四位而得到的。output[2]并且output[3]是 角色=。
如果这些要点让您感到困惑,您可能会发现表 4.1更直观。该表将所有这些逻辑统一到一个简单的表中。请注意,该表还提供了 Zig 中创建相应输出字节的精确表达式。
表 4.1:在不同的窗口设置下,6 位转换如何转换为代码。
| 窗口中的字节数 | 输出中的字节索引 | 在代码中 |
|---|---|---|
| 3 | 0 | 输入[0] >> 2 |
| 3 | 1 | ((输入[0] & 0x03) << 4) + (输入[1] >> 4) |
| 3 | 2 | ((输入[1] & 0x0f) << 2) + (输入[2] >> 6) |
| 3 | 3 | 输入[2] & 0x3f |
| 2 | 0 | 输入[0] >> 2 |
| 2 | 1 | ((输入[0] & 0x03) << 4) + (输入[1] >> 4) |
| 2 | 2 | ((输入[1] & 0x0f) << 2) |
| 2 | 3 | '=' |
| 1 | 0 | 输入[0] >> 2 |
| 1 | 1 | ((输入[0] & 0x03) << 4) |
| 1 | 2 | '=' |
| 1 | 3 | '=' |
4.4.2 Zig 中的位移位
Zig 中的位移位与 C 语言中的位移位类似。C 语言中所有位运算符在 Zig 中均可用。在 base64 编码器算法中,它们对于产生我们想要的结果至关重要。
对于不熟悉这些运算符的人来说,它们是在值的位级别上进行操作的运算符。这意味着这些运算符获取构成值的位,并以某种方式对其进行更改。这最终也会改变值本身,因为该值的二进制表示发生了变化。
我们已经在图 4.3中看到了位移位产生的效果。让我们用 Base64 编码器输出的第一个字节作为另一个例子来说明位移位的含义。这是输出中 4 个字节中最容易构建的字节。因为我们只需要使用_位移位_运算符( >>) 将输入中第一个字节的位向右移动两位即可。
以图 4.1中使用的字符串“Hi”为例,该字符串的第一个字节是“H”,也就是01001000二进制序列。如果我们将该字节的位向右移动两位,就得到了00010010结果序列。这个二进制序列既是十进制值18,也是0x12十六进制值。注意,“H”的前 6 位被移动到了字节的末尾。通过此操作,我们得到了输出的第一个字节。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const input = "Hi";
try stdout.print("{d}\n", .{input[0] >> 2});
}
18
如果你回想一下图 4.1,输出中的第一个字节应该相当于 6 位组010010。虽然视觉上有所不同,但序列010010和00010010语义上是相同的。它们的含义相同。它们都用十进制表示数字 18,用十六进制表示值0x12。
所以,不要太在意“6 位组”这个因素。我们不一定需要得到一个 6 位序列作为结果。只要我们得到的 8 位序列的含义与 6 位序列相同,就没问题了。
4.4.3使用&运算符选择特定位
如果你回到4.4.1 节,你会发现,为了生成输出中的第二和第三个字节,我们需要从输入字符串的第一和第二个字节中选择特定的位。但是我们该怎么做呢?答案依赖于_按位与_( &) 运算符。
图4.3已经展示了该运算符对其操作数的 位产生的影响&。让我们对其进行更清晰的描述。
简而言之,该&运算符对其操作数的位执行逻辑与运算。更详细地说,该运算符将&第一个操作数的每个位与第二个操作数的相应位进行比较。如果两个位都为 1,则将相应的结果位设置为 1。否则,将相应的结果位设置为 0 (Microsoft 2021)。
因此,如果我们将此运算符应用于二进制序列1000100,则00001101此运算的结果为二进制序列00000100。因为在两个二进制序列中,只有第六个位置的值是 1。因此,在两个二进制序列中,任何未设置为 1 的位置,在最终的二进制序列中都会得到 0 位。
在这种情况下,我们会丢失两个序列的原始位值信息。因为我们不再知道最终二进制序列中的这个 0 位是 0 与 0 组合而成,还是 1 与 0 组合而成,又或者 0 与 1 组合而成。
举个例子,假设你有一个二进制序列10010111,用十进制表示就是151。那么如何得到一个只包含该序列第三位和第四位的新二进制序列呢?
我们只需使用运算符将此序列与00110000(0x30十六进制的 )组合即可&。注意,此二进制序列中只有第三和第四个位置被设置为 1。因此,两个二进制序列中只有第三和第四个值可能保留在输出中。输出序列中所有剩余位置都被设置为零,即00010000(十进制的 16)。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const bits = 0b10010111;
try stdout.print("{d}\n", .{bits & 0b00110000});
}
16
4.4.4为输出分配空间
正如我在3.1.4 节中所述,要将对象存储在堆栈中,该对象需要在编译时具有已知且固定的长度。这对于我们的 Base64 编码器/解码器而言是一个重要的限制。因为输出的大小(来自编码器和解码器)直接取决于输入的大小。
考虑到这一点,我们无法在编译时知道编码器和解码器的输出大小。所以,如果我们无法在编译时知道输出的大小,就意味着我们无法将编码器和解码器的输出都存储在堆栈中。
因此,我们需要将此输出存储在堆上,并且正如我在3.1.5 节中所述,我们只能使用分配器对象将对象存储在堆上。因此,encode()和decode()函数的参数中都需要有一个分配器对象,因为我们确切地知道,在这些函数体中的某个时刻,我们需要在堆上分配空间来存储这些函数的输出。
这就是为什么我在本书中介绍的encode()和函数都有一个名为的参数,它接收一个分配器对象作为输入,该对象由Zig 标准库中的类型标识。decode()``allocator``std.mem.Allocator
4.4.5编写encode()函数
现在我们已经对位运算符的工作原理以及它们如何帮助我们实现想要的结果有了基本的了解。现在,我们可以将图 4.1和表 4.1中描述的所有逻辑封装到一个函数中,并将其添加到我们在4.1.2 节Base64中开始的结构体定义中。
您可以在下面找到该encode()函数。请注意,该函数的第一个参数是Base64结构体本身。因此,这个参数清楚地表明该函数是Base64结构体的一个方法。
由于encode()函数本身相当长,Base64为了简洁起见,我特意省略了源代码中的结构体定义。因此,只需记住此函数是Base64结构体中的公共函数(或公共方法)。
此外,该encode()函数还有另外两个参数:
input是要以 base64 编码的字符输入序列;allocator是在必要的内存分配中使用的分配器对象。
我在第 3.3 节中描述了你需要了解的关于分配器对象的所有知识。所以,如果你不熟悉它们,我强烈建议你回到那一节并仔细阅读。通过查看encode()函数,你会发现我们使用这个分配器对象分配了足够的内存来存储编码过程的输出。
函数中的主 for 循环负责遍历整个输入字符串。在每次迭代中,我们使用一个count变量来计算当前的迭代次数。当迭代count次数达到 3 时,我们尝试对临时缓冲区对象 ( ) 中累积的 3 个字符(或字节)进行编码buf。
对这 3 个字符进行编码并将结果存储在output变量中后,我们将count变量重置为零,并在循环的下一次迭代中重新开始计数。如果循环到达字符串末尾,并且count变量小于 3,则表示临时缓冲区包含输入的最后 1 或 2 个字节。这就是为什么我们if在 for 循环后添加了两个语句,分别处理每种可能的情况。
pub fn encode(self: Base64,
allocator: std.mem.Allocator,
input: []const u8) ![]u8 {
if (input.len == 0) {
return "";
}
const n_out = try _calc_encode_length(input);
var out = try allocator.alloc(u8, n_out);
var buf = [3]u8{ 0, 0, 0 };
var count: u8 = 0;
var iout: u64 = 0;
for (input, 0..) |_, i| {
buf[count] = input[i];
count += 1;
if (count == 3) {
out[iout] = self._char_at(buf[0] >> 2);
out[iout + 1] = self._char_at(
((buf[0] & 0x03) << 4) + (buf[1] >> 4)
);
out[iout + 2] = self._char_at(
((buf[1] & 0x0f) << 2) + (buf[2] >> 6)
);
out[iout + 3] = self._char_at(buf[2] & 0x3f);
iout += 4;
count = 0;
}
}
if (count == 1) {
out[iout] = self._char_at(buf[0] >> 2);
out[iout + 1] = self._char_at(
(buf[0] & 0x03) << 4
);
out[iout + 2] = '=';
out[iout + 3] = '=';
}
if (count == 2) {
out[iout] = self._char_at(buf[0] >> 2);
out[iout + 1] = self._char_at(
((buf[0] & 0x03) << 4) + (buf[1] >> 4)
);
out[iout + 2] = self._char_at(
(buf[1] & 0x0f) << 2
);
out[iout + 3] = '=';
iout += 4;
}
return out;
}
4.5构建解码器逻辑
现在,我们可以专注于编写 Base64 解码器逻辑了。记住,图 4.2中提到,Base64 解码器执行的是编码器的逆过程。因此,我们需要做的就是编写一个函数来执行我在4.4 节decode()中介绍的逆过程。
4.5.1将 base64 字符映射到其索引
为了解码 base64 编码的消息,我们需要做的一件事是计算在解码器输入中遇到的每个 base64 字符在 base64 比例中的索引。
换句话说,解码器接收一个 base64 字符序列作为输入。我们需要将此字符序列转换为一个索引序列。这些索引是每个字符在 base64 编码中的索引。这样,我们就得到了在编码器过程中 6 位转换步骤中计算出的值/字节。
可能有更好/更快的方法来计算这个,尤其是使用“分而治之”类型的策略。但目前,我对简单的“蛮力”策略感到满意。_char_index()下面的函数包含此策略。
我们本质上是在用 base64 编码循环遍历_查找表_,并将得到的字符与 base64 编码中的每个字符进行比较。如果匹配,则返回该字符在 base64 编码中的索引作为结果。
请注意,如果输入字符为'=',函数将返回索引 64,这在标度中“超出范围”。但是,正如我在4.1.1 节中所述,该字符'='本身不属于 base64 标度。它是 base64 中一个特殊且无意义的字符。
还要注意,由于参数的存在,这个_char_index()函数实际上是我们结构体中的一个方法。同样,为了简洁起见,我在这个例子中省略了结构体的定义。Base64``self``Base64
fn _char_index(self: Base64, char: u8) u8 {
if (char == '=')
return 64;
var index: u8 = 0;
for (0..63) |i| {
if (self._char_at(i) == char)
break;
index += 1;
}
return index;
}
4.5.2 6位变换
再次强调,该算法的核心部分是 6 位变换。如果我们理解了执行此变换的必要步骤,那么算法的其余部分就会变得容易得多。
首先,在实际进行 6 位转换之前,我们需要确保使用_char_index()来将 Base64 字符序列转换为索引序列。因此,下面的代码片段对于即将完成的工作至关重要。 的结果_char_index()存储在一个临时缓冲区中,我们将在 6 位转换中使用这个临时缓冲区,而不是实际的对象input。
for (0..input.len) |i| {
buf[i] = self._char_index(input[i]);
}
现在,base64 解码器不再对输入中每个包含 3 个字符的窗口生成 4 个字节(或 4 个字符)的输出,而是对输入中每个包含 4 个字符的窗口生成 3 个字节(或 3 个字符)的输出。这又是一个逆过程。
因此,生成输出中的 3 个字节的步骤如下:
output[0]由两个分量相加得到。首先,将buf[0]两个位置的位向左移动。然后,将buf[1]四个位置的位向右移动。最后,将这两个分量相加。output[1]通过将两个分量相加而得到。首先,将位从buf[1]左移 4 位。然后,将位从buf[2]右移 2 位。最后,将这两个分量相加。output[2]是通过将两个分量相加而得到的。首先,将位从buf[2]六位向左移动。然后将结果与 相加buf[3]。
在继续之前,让我们先想象一下这些变换是如何生成编码过程之前的原始字节的。首先,回想一下4.4 节中介绍的编码器执行的 6 位变换。编码器输出的第一个字节是通过将输入的第一个字节中的位向右移动两位而生成的。
例如,如果编码器输入的第一个字节是序列ABCDEFGH,那么编码器输出的第一个字节就是00ABCDEF(该序列就是解码器输入的第一个字节)。现在,如果编码器输入的第二个字节是序列IJKLMNOP,那么编码器输出的第二个字节就是(如图 4.300GHIJKL所示)。
因此,如果序列00ABCDEF和00GHIJKL分别是解码器输入的第一个和第二个字节,则图 4.4直观地演示了这两个字节如何转换为解码器输出的第一个字节。注意,输出字节是序列ABCDEFGH,它是来自编码器输入的原始字节。
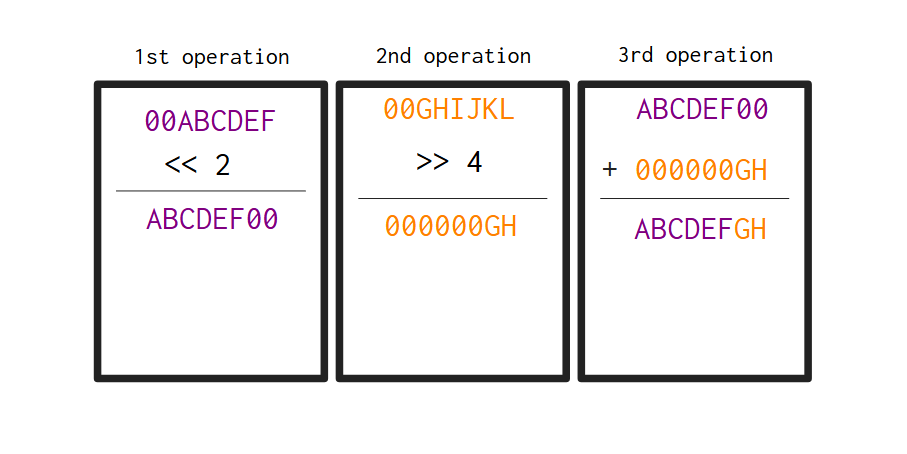
图 4.4:解码器输出中的第一个字节是如何由输入的第一个字节(深紫色)和第二个字节(橙色)生成的
表4.2显示了前面描述的 三个步骤如何转换为 Zig 代码:
表4.2:解码过程中6变换的必要步骤。
| 输出中的字节索引 | 在代码中 |
|---|---|
| 0 | (缓冲区[0] << 2)+(缓冲区[1] >> 4) |
| 1 | (缓冲区[1] << 4)+(缓冲区[2] >> 2) |
| 2 | (缓冲区[2] << 6)+ 缓冲区[3] |
4.5.3编写decode()函数
下面的函数decode()包含整个解码过程。我们首先用 计算输出的大小,_calc_decode_length()然后使用分配器对象为该输出分配足够的内存。
创建了三个临时变量:1) count,用于保存 for 循环每次迭代中的窗口计数;2) iout,用于保存输出中的当前索引;3) buf,用于保存要通过 6 位转换进行转换的 base64 索引的临时缓冲区。
然后,在 for 循环的每次迭代中,我们用当前窗口的字节数填充临时缓冲区。当count命中数字 4 时,我们就有了一个完整的buf待转换索引窗口,然后,我们对临时缓冲区应用 6 位转换。
注意,我们检查了临时缓冲区中的索引 2 和 3 是否为数字 64。如果你还记得4.5.1 节的内容,当_calc_index()函数接收到一个'='字符作为输入时,数字 64 就是这个数字。所以,如果这些索引等于数字 64,decode()函数就知道它可以忽略它们。它们不会被转换,因为正如我之前描述的,尽管该字符'='是序列中有意义字符的结尾,但它没有任何意义。所以当它们出现在序列中时,我们可以放心地忽略它们。
fn decode(self: Base64,
allocator: std.mem.Allocator,
input: []const u8) ![]u8 {
if (input.len == 0) {
return "";
}
const n_output = try _calc_decode_length(input);
var output = try allocator.alloc(u8, n_output);
var count: u8 = 0;
var iout: u64 = 0;
var buf = [4]u8{ 0, 0, 0, 0 };
for (0..input.len) |i| {
buf[count] = self._char_index(input[i]);
count += 1;
if (count == 4) {
output[iout] = (buf[0] << 2) + (buf[1] >> 4);
if (buf[2] != 64) {
output[iout + 1] = (buf[1] << 4) + (buf[2] >> 2);
}
if (buf[3] != 64) {
output[iout + 2] = (buf[2] << 6) + buf[3];
}
iout += 3;
count = 0;
}
}
return output;
}
4.6最终结果
现在我们已经实现了 和decode()。我们在 Zig 中实现了一个功能齐全的 base64 编码器/解码器。下面是我们结构体及其实现的和方法encode()的使用示例。Base64``encode()``decode()
var memory_buffer: [1000]u8 = undefined;
var fba = std.heap.FixedBufferAllocator.init(
&memory_buffer
);
const allocator = fba.allocator();
const text = "Testing some more stuff";
const etext = "VGVzdGluZyBzb21lIG1vcmUgc3R1ZmY=";
const base64 = Base64.init();
const encoded_text = try base64.encode(
allocator, text
);
const decoded_text = try base64.decode(
allocator, etext
);
try stdout.print(
"Encoded text: {s}\n", .{encoded_text}
);
try stdout.print(
"Decoded text: {s}\n", .{decoded_text}
);
Encoded text: VGVzdGluZyBzb21lIG1vcmUgc3R1ZmY=
Decoded text: Testing some more stuff
您还可以通过访问本书的官方存储库3来立即查看完整的源代码。更准确地说,是在ZigExamples文件夹4内。
-
请注意,字符“0”与实际数字 0 不同,后者在二进制中只是零。↩︎
-
https://github.com/pedropark99/zig-book/blob/main/ZigExamples/base64/base64_basic.zig。↩︎
-
https://github.com/pedropark99/zig-book/blob/main/ZigExamples/base64/base64_basic.zig。↩︎
5 调试 Zig 应用程序
对于任何想要使用任何语言进行严肃编程的程序员来说,能够调试应用程序都是至关重要的。因此,在本章中,我们将讨论调试用 Zig 编写的应用程序的可用策略和工具。
5.1打印调试
我们从经典且久经考验的_打印调试_策略开始。调试提供的关键优势是_可视性_。使用_打印语句,_您可以轻松查看应用程序生成的结果和对象。
_这是打印调试_的本质——使用打印表达式查看程序生成的值,从而更好地了解程序的行为方式。
许多程序员经常使用 Zig 中的打印功能,例如stdout.print()、 或std.debug.print(),来更好地理解他们的程序。这是一种众所周知的古老策略,非常简单有效,在编程社区中更广为人知的名称是_打印调试_。在 Zig 中,您可以将信息打印到系统的stdout或流中。stderr
让我们从 开始。首先,您需要通过调用Zig 标准库中的 方法stdout来访问。此方法返回一个_文件描述符_对象,您可以通过该对象读取/写入。我建议您通过查看 Zig 标准库官方参考中类型1 的页面,来查看此对象中可用的所有方法。stdout``getStdOut()``stdoutFile
就我们这里的目的而言,也就是向 写入一些内容stdout,尤其是为了调试我们的程序,我建议你使用writer()方法,它会返回一个_writer_对象。这个_writer_对象提供了一些辅助方法,可以将内容写入代表流的文件描述符对象stdout。具体来说,就是print()方法。
print()此_writer_对象中的方法是一个“打印格式化程序”类型的函数。换句话说,此方法的工作方式printf()与 C 语言或println!()Rust 语言中的函数完全相同。在函数的第一个参数中,指定一个模板字符串;在第二个参数中,提供要插入到模板消息中的值(或对象)列表。
理想情况下,第一个参数中的模板字符串应该包含一些格式说明符。每个格式说明符都与第二个参数中列出的值(或对象)匹配。因此,如果您在第二个参数中提供了 5 个不同的对象,那么模板字符串应该包含 5 个格式说明符,每个提供的对象对应一个。
每个格式说明符都由一个字母表示,并且需要用一对花括号括起来。因此,如果您想使用字符串说明符 ( s) 来格式化对象,则可以将文本插入{s}模板字符串中。以下是一些最常用的格式说明符的简要列表:
d:用于打印整数和浮点数。c:用于打印字符。s:用于打印字符串。p:用于打印内存地址。x:用于打印十六进制值。any:使用任何兼容的格式说明符(即,它会自动为您选择格式说明符)。
print()下面的代码示例为您提供了使用格式说明符使用此方法的示例d。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
fn add(x: u8, y: u8) u8 {
return x + y;
}
pub fn main() !void {
const result = add(34, 16);
try stdout.print("Result: {d}", .{result});
}
Result: 50
需要强调的是,stdout.print()正如您所期望的,该方法会将模板字符串打印到stdout系统流中。但是,stderr如果您愿意,也可以将模板字符串打印到流中。您只需将stdout.print()调用替换为函数即可std.debug.print()。如下所示:
const std = @import("std");
fn add(x: u8, y: u8) u8 {
return x + y;
}
pub fn main() !void {
const result = add(34, 16);
std.debug.print("Result: {d}\n", .{result});
}
Result: 50
您还可以通过获取文件描述符对象stderr,然后创建_写入器_对象stderr,然后使用print()此_写入器_对象的方法来实现完全相同的结果,如下例所示:
const std = @import("std");
const stderr = std.io.getStdErr().writer();
// some more lines ...
try stderr.print("Result: {d}", .{result});
5.2通过调试器进行调试
虽然_打印调试_是一种有效且非常有用的策略,但大多数程序员更喜欢使用调试器来调试他们的程序。由于 Zig 是一种低级语言,因此您可以使用 GDB(GNU 调试器)或 LLDB(LLVM 项目调试器)作为调试器。
两种调试器都可以处理 Zig 代码,这取决于个人喜好。您可以选择自己喜欢的调试器,并使用它进行调试。在本书的示例中,我将使用 LLDB 作为调试器。
5.2.1在调试模式下编译源代码
为了通过调试器调试程序,您必须在Debug模式下编译源代码。因为当您在其他模式下(例如Release)编译源代码时,编译器通常会删除一些调试器用来读取和跟踪程序的基本信息,例如 PDB(程序数据库)文件。
通过以模式编译源代码Debug,可以确保调试器能够在程序中找到调试所需的信息。默认情况下,编译器会使用该Debug模式编译代码。考虑到这一点,当您使用命令(在1.2.4 节build-exe中描述)编译程序时,如果您未通过命令行2参数指定显式模式,那么编译器将以该模式编译代码。-ODebug
5.2.2让我们调试一个程序
作为示例,让我们使用 LLDB 来导航和调查以下 Zig 代码:
const std = @import("std");
const stdout = std.io.getStdOut().writer();
fn add_and_increment(a: u8, b: u8) u8 {
const sum = a + b;
const incremented = sum + 1;
return incremented;
}
pub fn main() !void {
var n = add_and_increment(2, 3);
n = add_and_increment(n, n);
try stdout.print("Result: {d}!\n", .{n});
}
Result: 13!
这个程序本身没有任何问题,但这对我们来说是一个好的开始。首先,我们需要使用zig build-exe命令编译这个程序。在本例中,假设我已经将上面的 Zig 代码编译成一个名为 的二进制可执行文件add_program。
zig build-exe add_program.zig
现在,我们可以使用 启动 LLDB add_program,如下所示:
lldb add_program
从现在开始,LLDB 已启动,您可以通过查看前缀 知道我正在执行 LLDB 命令(lldb)。如果某个命令以 为前缀(lldb),那么您就知道它是一个 LLDB 命令。
我要做的第一件事,就是在main()函数中执行 ,设置一个断点b main。之后,我只需使用 即可开始执行程序run。您可以在下面的输出中看到,main()正如我们预期的那样,执行在函数的第一行停止了。
(lldb) b main
Breakpoint 1: where = debugging`debug1.main + 22
at debug1.zig:11:30, address = 0x00000000010341a6
(lldb) run
Process 8654 launched: 'add_program' (x86_64)
Process 8654 stopped
* thread #1, name = 'add_program',
stop reason = breakpoint 1.1 frame #0: 0x10341a6
add_program`debug1.main at add_program.zig:11:30
8 }
9
10 pub fn main() !void {
-> 11 var n = add_and_increment(2, 3);
12 n = add_and_increment(n, n);
13 try stdout.print("Result: {d}!\n", .{n});
14 }
我可以开始浏览代码,并检查正在生成的对象。如果您不熟悉 LLDB 中可用的命令,我建议您阅读该项目的官方文档3。您还可以查找速查表,其中快速描述了所有可用的命令4。
目前,我们位于main()函数的第一行。在这一行,我们n通过执行add_and_increment()函数来创建对象。要执行当前代码行并转到下一行,我们可以运行nLLDB 命令。让我们执行这个命令。
n执行此行后,我们还可以使用LLDB 命令查看此对象中存储的值p。此命令的语法为p <name-of-object>。
如果我们查看n对象(p n)中存储的值,会发现它存储的是十六进制值0x06,即十进制数 6。我们还可以看到,该值的类型为,它是一个无符号 8 位整数。我们已经在1.8 节unsigned char中讨论过这一点,Zig 中的整数等同于 C 数据类型。u8``unsigned char
(lldb) n
Process 4798 stopped
* thread #1, name = 'debugging',
stop reason = step over frame #0: 0x10341ae
debugging`debug1.main at debug1.zig:12:26
9
10 pub fn main() !void {
11 var n = add_and_increment(2, 3);
-> 12 n = add_and_increment(n, n);
13 try stdout.print("Result: {d}!\n", .{n});
14 }
(lldb) p n
(unsigned char) $1 = '\x06'
现在,在下一行代码中,我们add_and_increment()再次执行该函数。为什么不进入这个函数内部呢?可以吗?我们可以通过执行sLLDB 命令来实现。请注意,在下面的示例中,执行此命令后,我们进入了该函数的上下文add_and_increment()。
还要注意,在下面的例子中,我在函数主体中又走了两行,然后,我执行frame variableLLDB 命令,立即查看在当前范围内创建的每个变量中存储的值。
您可以在下面的输出中看到,该对象sum存储了值\f,该值表示_换页_符。在 ASCII 表中,该字符对应的十六进制值0x0C,或者用十进制表示为数字 12。因此,这意味着在第 5 行执行的表达式的结果a + b为数字 12。
(lldb) s
Process 4798 stopped
* thread #1, name = 'debugging',
stop reason = step in frame #0: 0x10342de
debugging`debug1.add_and_increment(a='\x02', b='\x03')
at debug1.zig:4:39
-> 4 fn add_and_increment(a: u8, b: u8) u8 {
5 const sum = a + b;
6 const incremented = sum + 1;
7 return incremented;
(lldb) n
(lldb) n
(lldb) frame variable
(unsigned char) a = '\x06'
(unsigned char) b = '\x06'
(unsigned char) sum = '\f'
(unsigned char) incremented = '\x06'
5.3如何调查对象的数据类型
由于 Zig 是一种强类型语言,因此与对象关联的数据类型对于程序非常重要。因此,调试与对象关联的数据类型对于了解程序中的错误和错误可能很重要。
当您使用调试器运行程序时,只需使用 LLDBp命令将对象类型打印到控制台即可检查对象类型。此外,您还可以使用语言本身内置的替代方法来访问对象的数据类型。
在 Zig 中,您可以使用内置函数检索对象的数据类型@TypeOf()。只需将此函数应用于对象,即可访问该对象的数据类型。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
const expect = std.testing.expect;
pub fn main() !void {
const number: i32 = 5;
try expect(@TypeOf(number) == i32);
try stdout.print("{any}\n", .{@TypeOf(number)});
}
i32
该函数类似于type()Python的内置函数,或者typeofJavascript中的运算符。
6 指针和可选参数
在我们的下一个项目中,我们将从头开始构建一个 HTTP 服务器。但为了做到这一点,我们需要更多地了解指针以及它们在 Zig 中的工作原理。Zig 中的指针与 C 语言中的指针类似。但它们在 Zig 中具有一些额外的优势。
指针是一个包含内存地址的对象。这个内存地址是特定值在内存中的存储地址。它可以是任何值。大多数情况下,它是来自代码中另一个对象(或变量)的值。
在下面的例子中,我创建了两个对象(number和pointer)。pointer对象 包含存储对象值number(数字 5)的内存地址。简而言之,这是一个指针。它是一个指向内存中特定现有值的内存地址。你也可以说,对象 指向存储对象的pointer内存地址。number
const number: u8 = 5;
const pointer = &number;
_ = pointer;
我们使用&运算符在 Zig 中创建一个指针对象。将此运算符放在现有对象的名称之前,结果将返回该对象的内存地址。将此内存地址存储在新对象中时,该新对象将成为指针对象。因为它存储的是内存地址。
人们通常使用指针作为访问特定值的替代方法。例如,我可以使用pointer对象来访问对象存储的值number。访问指针“指向”的值的操作通常称为_取消引用指针_。我们可以使用指针对象的方法在 Zig 中取消引用指针*。如下例所示,我们取对象指向的数字 5 pointer,并将其加倍。
const number: u8 = 5;
const pointer = &number;
const doubled = 2 * pointer.*;
std.debug.print("{d}\n", .{doubled});
10
这种取消引用指针的语法很棒。因为我们可以轻松地将它与指针指向的值的方法链接起来。我们可以使用在2.3 节User中创建的结构体作为示例。如果您返回该部分,您将看到该结构体有一个名为 的方法。print_name()
举个例子,如果我们有一个用户对象,以及一个指向该用户对象的指针,我们可以使用该指针访问该用户对象,同时print_name()通过将解引用方法(*)与print_name()方法链接起来,调用其上的方法。如下例所示:
const u = User.init(1, "pedro", "email@gmail.com");
const pointer = &u;
try pointer.*.print_name();
pedro
我们还可以使用指针来有效地修改对象的值。例如,我可以使用pointer对象将对象的值设置number为 6,如下例所示。
var number: u8 = 5;
const pointer = &number;
pointer.* = 6;
try stdout.print("{d}\n", .{number});
6
因此,正如我之前提到的,人们使用指针作为访问特定值的另一种方式。尤其是在他们不想“移动”这些值的时候,他们会使用指针。在某些情况下,你想在代码的不同作用域(即不同的位置)访问某个特定值,但又不想将它“移动”到你所在的新作用域(或位置)。
如果这个值很大,这一点尤其重要。因为如果很大,那么移动这个值就会变成一项昂贵的操作。计算机将不得不花费大量时间将该值复制到新的位置。
因此,许多程序员倾向于通过指针访问值,以避免这种繁琐的将值复制到新位置的操作。我们将在接下来的部分中详细讨论这种“移动操作”。现在,只需记住,避免这种“移动操作”是编程语言中使用指针的主要原因之一。
6.1常量对象与变量对象
你可以有一个指向常量对象的指针,或者一个指向变量对象的指针。但无论这个指针指向哪个对象,它都必须始终遵循其指向对象的特性。因此,如果指针指向一个常量对象,你就不能用它改变它指向的值。因为它指向的是一个常量值。正如我们在1.4 节中讨论过的,你无法改变一个常量值。
例如,如果我有一个number常量对象,我无法执行下面的表达式,即尝试number通过该pointer对象将 的值更改为 6。如下所示,当你尝试执行类似的操作时,会收到编译时错误:
const number = 5;
const pointer = &number;
pointer.* = 6;
p.zig:6:12: error: cannot assign to constant
pointer.* = 6;
如果我number通过引入关键字将对象更改为变量对象,var那么我就可以成功地通过指针更改该对象的值,如下所示:
var number: u8 = 5;
const pointer = &number;
pointer.* = 6;
try stdout.print("{d}\n", .{number});
6
你可以在指针对象的数据类型上看到“常量与变量”之间的关系。换句话说,指针对象的数据类型已经为你提供了一些关于它指向的值是否为常量的线索。
当指针对象指向常量值时,该指针的数据类型为*const T,即“指向 类型常量值的指针T”。相反,如果指针指向变量值,则指针的类型通常为*T,即“指向 类型值的指针T”。因此,每当您看到数据类型为 格式的指针对象时*const T,您就知道不能使用此指针更改其指向的值。因为该指针指向 类型的常量值T。
我们已经讨论了指针指向的值是否为常量,以及由此产生的后果。但是,指针对象本身呢?我的意思是,如果指针对象本身是常量,会发生什么?想一想。我们可以有一个指向常量值的常量指针。但我们也可以有一个指向常量值的变量指针。反之亦然。
在此之前,该pointer对象始终是常量,但这对我们来说意味着什么?对象pointer为常量会带来什么后果?后果是,我们无法更改指针对象,因为它是常量。我们可以以多种方式使用指针对象,但无法更改其内部的内存地址。
但是,如果我们将pointer对象标记为变量对象,那么我们就可以更改该对象指向的内存地址pointer。下面的示例演示了这一点。请注意,对象指向的对象pointer从c1变为c2。
const c1: u8 = 5;
const c2: u8 = 6;
var pointer = &c1;
try stdout.print("{d}\n", .{pointer.*});
pointer = &c2;
try stdout.print("{d}\n", .{pointer.*});
5
6
因此,通过将pointer对象设置为var或const对象,您可以指定此指针对象中包含的内存地址是否可以在程序中更改。另一方面,当且仅当该值存储在变量对象中时,您才可以更改指针指向的值。如果该值存储在常量对象中,则您无法通过指针更改该值。
6.2指针的类型
在 Zig 中,有两种类型的指针(Zig Software Foundation 2024),分别是:
- 单项指针(
*); - 多项指针(
[*]);
单项指针对象是指数据类型为 的对象*T。例如,如果一个对象的数据类型为*u32,则表示该对象包含一个指向无符号 32 位整数值的单项指针。再例如,如果一个对象的类型为*User,则表示它包含一个指向某个值的单项指针User。
相比之下,多项指针是数据类型为 格式的对象[*]T。请注意,星号 ( *) 现在位于一对括号 ( []) 内。如果星号位于一对括号内,则表明此对象是多项指针。
当你&对一个对象应用该运算符时,你总是会得到一个单项指针。多项指针更像是语言的“内部类型”,与切片更密切相关。因此,当你特意使用该&运算符创建一个指针时,你总是会得到一个单项指针。
6.3指针运算
Zig 中提供指针运算,其工作方式与 C 中的工作方式相同。当您有一个指向数组的指针时,该指针通常指向数组中的第一个元素,并且您可以使用指针运算来推进该指针并访问数组中的其他元素。
请注意,在下面的例子中,对象最初ptr指向数组中的第一个元素ar。但是,然后我开始遍历数组,通过使用简单的指针算法来推进指针。
const ar = [_]i32{ 1, 2, 3, 4 };
var ptr: [*]const i32 = &ar;
try stdout.print("{d}\n", .{ptr[0]});
ptr += 1;
try stdout.print("{d}\n", .{ptr[0]});
ptr += 1;
try stdout.print("{d}\n", .{ptr[0]});
1
2
3
虽然您可以创建一个指向这样的数组的指针,并开始使用指针算法遍历该数组,但在 Zig 中,我们更喜欢使用切片,如第 1.6 节中介绍的那样。
切片本身就是指针,并且还带有一个len属性,用于指示切片中包含多少个元素。这很有用,因为zig编译器可以使用它来检查潜在的缓冲区溢出以及其他类似的问题。
此外,您无需使用指针运算来遍历切片的元素。您只需使用slice[index]语法即可直接访问切片中所需的任何元素。正如我在1.6 节中提到的,您可以使用括号内的范围选择器从数组中获取切片。在下面的示例中,我创建了一个sl覆盖整个ar数组的切片 ()。我可以从这个切片中访问 的任何元素ar,并且切片本身在底层已经是一个指针了。
const ar = [_]i32{1,2,3,4};
const sl = ar[0..ar.len];
_ = sl;
6.4可选类型和可选指针
让我们讨论一下可选类型以及它们与 Zig 中的指针的关系。默认情况下,Zig 中的对象不可为空。这意味着,在 Zig 中,您可以安全地假设源代码中的任何对象都不为空。
与 C 语言的开发者体验相比,Zig 的这一特性非常强大。因为在 C 语言中,任何对象在任何时候都可能为空,因此,C 语言中的指针也可能指向空值。这是 C 语言中常见的未定义行为来源。程序员在 C 语言中使用指针时,必须不断检查指针是否指向空值。
如果由于某种原因,你的 Zig 代码在某个地方产生了一个空值,并且这个空值最终出现在一个不可空的对象中,那么你的 Zig 程序总是会引发运行时错误。以下面的程序为例。zig编译器可以在编译时看到该null值,因此会引发编译时错误。但是,如果null在运行时产生了一个值,Zig 程序也会引发运行时错误,并显示“尝试使用空值”消息。
var number: u8 = 5;
number = null;
p5.zig:5:14: error: expected type 'u8',
found '@TypeOf(null)'
number = null;
^~~~
在 C 语言中,你无法获得这种安全性。在 C 语言中,你不会收到关于程序中产生空值的警告或错误。如果由于某种原因,你的代码在 C 语言中产生了空值,大多数情况下,你最终会得到一个段错误,这可能意味着很多事情。这就是为什么程序员必须不断检查 C 语言中是否存在空值。
默认情况下,Zig 中的指针也是不可空的。这是 Zig 的另一个令人惊叹的特性。因此,您可以放心地假设您在 Zig 代码中创建的任何指针都指向非空值。因此,您无需费力地检查在 Zig 中创建的指针是否指向空值。
6.4.1什么是可选项?
好的,我们现在知道在 Zig 中所有对象默认都是不可空的。但是,如果我们实际上需要使用一个可能接收空值的对象怎么办?这时可选值就派上用场了。
Zig 中的可选对象是指可以为空的对象。为了将对象标记为可选,我们使用?运算符。当您将此?运算符放在对象的数据类型之前时,会将此数据类型转换为可选数据类型,并且该对象也将成为可选对象。
以下面的代码片段为例。我们创建了一个名为 的新变量对象num。该对象的数据类型为?i32,这意味着,该对象要么包含一个有符号的 32 位整数(i32),要么包含一个空值。这两种情况对于该num对象来说都是有效的值。因此,我可以将该对象的值更改为空值,而编译器不会报错zig,如下所示:
var num: ?i32 = 5;
num = null;
6.4.2可选指针
您还可以将指针对象标记为可选指针,这意味着该对象要么包含空值,要么包含指向值的指针。将指针标记为可选时,该指针对象的数据类型将变为?*const T或?*T,具体取决于指针指向的值是否为常量值。?表示该对象为可选,而*表示该对象为指针对象。
在下面的示例中,我们创建了一个名为 的变量对象num,以及一个名为 的可选指针对象ptr。请注意,对象的数据类型ptr指示它要么是空值,要么是指向i32值的指针。另请注意,即使指针对象不是可选的ptr,也可以将其标记为可选。num
这段代码告诉我们,num变量永远不会包含空值。该变量始终包含一个有效值i32。但与之相反,ptr对象可能包含空值,或者指向某个值的指针i32。
var num: i32 = 5;
var ptr: ?*i32 = #
ptr = null;
num = 6;
但是,如果我们反过来,将num对象而不是指针对象标记为可选,会发生什么呢?如果我们这样做,那么指针对象就不再是可选的了。这将是一个类似(尽管不同)的结果。因为这样一来,我们就会得到一个指向可选值的指针。换句话说,一个指向空值或非空值的指针。
在下面的例子中,我们重现了这个想法。现在,ptr对象的数据类型是*?i32,而不是?*i32。注意,此时*符号 位于 之前?。所以现在,我们有一个指向 null 或有符号 32 位整数的指针。
var num: ?i32 = 5;
// ptr have type `*?i32`, instead of `?*i32`.
const ptr = #
_ = ptr;
6.4.3可选参数中的空值处理
当 Zig 代码中有一个可选对象时,必须明确处理该对象为空的可能性。这就像使用try和进行错误处理一样catch。在 Zig 中,您还必须像处理错误类型一样处理空值。
我们可以通过以下方式实现:
- 一个 if 语句,就像在 C 语言中所做的那样。
- 关键字
orelse。 - 使用该方法解开可选值
?。
使用 if 语句时,需要使用一对竖线符号来解包可选值,并在 if 语句块中使用这个“解包后的对象”。以下面的例子为例,如果对象num为 null,则 if 语句中的代码不会被执行。否则,if 语句会将解包后的对象返回num到该not_null_num对象中。在 if 语句的范围内,该not_null_num对象保证不为 null。
const num: ?i32 = 5;
if (num) |not_null_num| {
try stdout.print("{d}\n", .{not_null_num});
}
5
现在,orelse关键字 的行为类似于二元运算符。您可以使用此关键字连接两个表达式。在 的左侧orelse,提供可能导致空值的表达式;在 的右侧orelse,提供另一个不会导致空值的表达式。
该关键字背后的想法orelse是:如果左侧表达式的结果为非空值,则使用这个非空值。但是,如果左侧表达式的结果为空值,则使用右侧表达式的值。
看下面的例子,由于x对象当前为空,因此orelse决定使用替代值,即数字 15。
const x: ?i32 = null;
const dbl = (x orelse 15) * 2;
try stdout.print("{d}\n", .{dbl});
30
当你想要解决(或处理)这个空值时,可以使用 if 语句或orelse关键字。但是,如果对于这个空值没有明确的解决方案,并且最合乎逻辑和理智的方法是简单地在遇到这个空值时在程序中发出 panic 并发出一个响亮的错误,那么你可以使用?可选对象的方法。
本质上,当您使用此?方法时,可选对象会被解包。如果在可选对象中找到非空值,则使用此非空值。否则,unreachable使用关键字。您可以unreacheable在官方文档1中阅读有关此关键字的更多信息。但本质上,当您使用构建模式ReleaseSafe或构建 Zig 源代码时Debug,此unreacheable关键字会导致程序在运行时崩溃并引发错误,如下例所示:
const std = @import("std");
const stdout = std.io.getStdOut().writer();
fn return_null(n: i32) ?i32 {
if (n == 5) return null;
return n;
}
pub fn main() !void {
const x: i32 = 5;
const y: ?i32 = return_null(x);
try stdout.print("{d}\n", .{y.?});
}
thread 12767 panic: attempt to use null value
p7.zig:12:34: 0x103419d in main (p7):
try stdout.print("{d}\n", .{y.?});
^
7 项目 2 - 从头构建 HTTP 服务器
在本章中,我想和你一起实现一个新的小项目。这次,我们将从零开始实现一个基本的 HTTP 服务器。
Zig 标准库已经实现了一个 HTTP 服务器,可在 中找到std.http.Server。但同样,本章的目标是从头开始实现它。因此,我们无法使用 Zig 标准库中提供的这个服务器对象。
7.1什么是 HTTP 服务器?
首先,什么是 HTTP 服务器?HTTP 服务器,和其他类型的服务器一样,本质上是一个无限循环运行的程序,等待来自客户端的连接。一旦服务器收到连接,它就会接受该连接,并通过该连接与客户端来回发送消息。
但是,在此连接内传输的消息具有特定的格式。它们是 HTTP 消息(即使用 HTTP 协议规范的消息)。HTTP 协议是现代网络的支柱。如果没有 HTTP 协议,我们今天所知的万维网将不复存在。
因此,Web 服务器(HTTP 服务器的别称)是与客户端交换 HTTP 消息的服务器。这些 HTTP 服务器和 HTTP 协议规范对于当今万维网的运行至关重要。
这就是整个过程的全貌。同样,这里涉及两个主体:一个服务器(一个无限期运行、等待接收连接的程序)和一个客户端(一个想要连接到服务器并与其交换 HTTP 消息的实体)。
您可以在 Mozilla MDN 文档1中找到有关 HTTP 协议的资料,这也是一个值得一看的优秀资源。它概述了 HTTP 的工作原理以及服务器在其中扮演的角色。
7.2 HTTP 服务器如何工作?
想象一下,HTTP 服务器就像一家大型酒店的接待员。酒店里有一个接待处,接待处里有一位接待员在等待顾客的到来。HTTP 服务器本质上就是一位接待员,它无限期地等待着新顾客(或者,在 HTTP 的语境中,是新客户端)抵达酒店。
当顾客抵达酒店时,他会与接待员交谈。他会告诉接待员他想在酒店住几天。然后,接待员会搜索可用的公寓。如果目前有空房,顾客会支付酒店费用,然后领取公寓钥匙,最后前往公寓休息。
在完成与客户打交道的整个过程(寻找可用的公寓、收到付款、交出钥匙)之后,接待员又回到了他之前的工作——等待。等待新客户的到来。
简而言之,这就是 HTTP 服务器所做的。它等待客户端连接到服务器。当客户端尝试连接服务器时,服务器接受此连接,并开始通过此连接与客户端交换消息。此连接中发生的第一条消息始终是从客户端发送到服务器的消息。此消息称为_HTTP 请求_。
HTTP 请求是一个 HTTP 消息,其中包含客户端希望从服务器获取的信息。它实际上是一个请求。连接到服务器的客户端正在请求服务器为其执行某些操作。
客户端可以向 HTTP 服务器发送不同类型的请求。但最基本的请求类型是客户端请求 HTTP 服务器为其提供(即发送)某个特定的网页(即 HTML 文件)。当您google.com在 Web 浏览器中输入内容时,实际上是在向 Google 的 HTTP 服务器发送 HTTP 请求。该请求要求这些服务器将 Google 网页发送给您。
尽管如此,当服务器收到第一条消息(_HTTP 请求)_时,它会分析此请求,以了解:客户端是谁?他希望服务器执行什么操作?该客户端是否提供了执行其请求操作所需的所有必要信息?等等。
一旦服务器了解了客户端想要什么,它只需执行所请求的操作,然后,为了完成整个过程,服务器会向客户端发送回一个 HTTP 消息,告知所执行的操作是否成功,最后,服务器结束(或关闭)与客户端的连接。
服务器发送给客户端的最后一条 HTTP 消息称为_HTTP 响应_。因为服务器正在响应客户端请求的操作。此响应消息的主要目的是在服务器关闭连接之前,让客户端知道请求的操作是否成功。
7.3 HTTP 服务器通常如何实现?
我们以 C 语言为例。有很多资料教你如何用 C 语言编写一个简单的 HTTP 服务器,比如Yu ( 2023 )、Weerasiri ( 2023 )或Meehan ( 2021 )。考虑到这一点,我不会在这里展示 C 语言代码示例,因为你可以在互联网上找到它们。但我将描述用 C 语言创建此类 HTTP 服务器所需步骤背后的理论。
本质上,我们通常使用 TCP 套接字在 C 中实现 HTTP 服务器,其中包括以下步骤:
- 创建一个 TCP 套接字对象。
- 将名称(或更具体地说,地址)绑定到此套接字对象。
- 使此套接字对象开始监听并等待传入的连接。
- 当连接到达时,我们接受该连接,并交换 HTTP 消息(HTTP 请求和 HTTP 响应)。
- 然后,我们只需关闭这个连接。
套接字对象本质上是一个通信通道。您正在创建一个可供人们发送消息的通道。当您创建套接字对象时,该对象并未绑定到任何特定地址。这意味着,通过该对象,您手中就拥有了一个通信通道的表示。但是,该通道当前不可用,或者说,当前无法访问,因为它没有已知的地址可供您找到。
这就是“绑定”操作的作用。它将一个名称(或者更确切地说,一个地址)绑定到这个套接字对象,或者说,这个通信通道,以便它可用,或者可以通过这个地址访问。而“监听”操作使套接字对象监听这个地址的传入连接。换句话说,“监听”操作使套接字等待传入连接。
现在,当客户端实际尝试通过我们指定的套接字地址连接到服务器时,为了与客户端建立连接,套接字对象需要接受此传入连接。因此,当我们接受传入连接时,客户端和服务器就相互连接了,它们可以开始向这个已建立的连接读取或写入消息。
当我们收到客户端的HTTP请求,分析它,并将HTTP响应发送给客户端后,我们就可以关闭连接,结束本次通信。
7.4实现服务器 - 第一部分
7.4.1创建套接字对象
让我们首先为服务器创建套接字对象。为了简洁起见,我将在一个单独的 Zig 模块中创建这个套接字对象。我将其命名为config.zig。
std.posix.socket()在 Zig 中,我们可以使用Zig 标准库中的函数创建 TCP 套接字。正如我之前在第 7.3 节中提到的,我们创建的每个套接字对象都代表一个通信通道,我们需要将此通道绑定到特定地址。“地址”定义为 IP 地址,或者更具体地说,是 IPv4 地址2。每个 IPv4 地址由两部分组成。第一个部分是主机,它是用点字符 ( .) 分隔的 4 个数字序列,用于标识所使用的机器。第二个部分是端口号,用于标识特定的门,或者主机中要使用的特定端口。
这 4 个数字序列(即主机)标识了套接字所在的机器(即计算机本身)。每台计算机通常内部都有多个“门”,因为这允许计算机同时接收和处理多个连接。它只为每个连接使用一个“门”。因此,端口号本质上是一个数字,用于标识计算机中负责接收连接的特定“门”。也就是说,它标识了套接字将用于接收传入连接的计算机中的“门”。
为了简单起见,我将在此示例中使用标识当前计算机的 IP 地址。这意味着,我们的套接字对象将驻留在我们当前用于编写此 Zig 源代码的同一台计算机上(也称为“localhost”)。
按照惯例,标识“localhost”(即我们当前正在使用的计算机)的 IP 地址是 IP 127.0.0.1。因此,这就是我们将在服务器中使用的 IP 地址。我可以在 Zig 中使用一个包含 4 个整数的数组来声明它,如下所示:
const localhost = [4]u8{ 127, 0, 0, 1 };
_ = localhost;
现在,我们需要决定使用哪个端口号。按照惯例,有些端口号是保留的,这意味着我们不能将它们用于自己的目的,例如端口 22(通常用于 SSH 连接)。对于 TCP 连接(此处为示例),端口号是一个 16 位无符号整数(u16以 Zig 格式输入),范围从 0 到 65535 (维基百科 2024)。因此,我们可以从 0 到 65535 中选择一个数字作为端口号。在本书的示例中,我将使用端口号 3490(只是一个随机数)。
现在我们掌握了这两个信息,终于可以使用std.posix.socket()函数创建套接字对象了。首先,我们使用主机名和端口号,Address通过std.net.Address.initIp4()函数创建一个对象,如下例所示。然后,我在socket()函数内部使用这个地址对象来创建套接字对象。
下面定义的结构体Socket概括了此过程背后的所有逻辑。在这个结构体中,我们有两个数据成员:1)地址对象;2)流对象,我们将使用该对象在建立的任何连接中读取和写入消息。
请注意,在此结构的构造函数方法中,当我们创建套接字对象时,我们使用该IPROTO.TCP属性作为输入来告诉函数为 TCP 连接创建套接字。
const std = @import("std");
const builtin = @import("builtin");
const net = @import("std").net;
pub const Socket = struct {
_address: std.net.Address,
_stream: std.net.Stream,
pub fn init() !Socket {
const host = [4]u8{ 127, 0, 0, 1 };
const port = 3490;
const addr = net.Address.initIp4(host, port);
const socket = try std.posix.socket(
addr.any.family,
std.posix.SOCK.STREAM,
std.posix.IPPROTO.TCP
);
const stream = net.Stream{ .handle = socket };
return Socket{ ._address = addr, ._stream = stream };
}
};
7.4.2监听和接收连接
记住,我们将在7.4.1 节Socket中构建的结构声明存储在名为 的 Zig 模块中。这就是为什么在下面的示例中,我将这个模块作为对象导入到我们的主模块 ( ) 中,以访问该结构。config.zig``main.zig``SocketConf``Socket
创建完套接字对象后,我们现在可以专注于让该套接字对象监听并接收新的连接。具体操作如下:调用套接字对象内部listen()的方法Address,然后对accept()结果调用该方法。
listen()该对象的方法会Address生成一个服务器对象,该对象将保持打开状态并无限期运行,等待接收传入的连接。因此,如果您尝试通过调用编译器run中的命令来运行下面的代码示例zig,您会注意到程序会无限期地运行,没有明确的结束。
发生这种情况是因为程序正在等待某些事情发生。它正在等待某人尝试连接到http://127.0.0.1:3490服务器正在运行并监听传入连接的地址 ( )。这就是该listen()方法的作用,它使套接字处于活动状态,等待某人连接。
另一方面,该accept()方法是当有人尝试连接到套接字时建立连接的函数。这意味着该accept()方法会返回一个新的连接对象。您可以使用此连接对象从客户端读取或写入消息。目前,我们不会使用此连接对象执行任何操作。但我们将在下一节中使用它。
const std = @import("std");
const SocketConf = @import("config.zig");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const socket = try SocketConf.Socket.init();
try stdout.print("Server Addr: {any}\n", .{socket._address});
var server = try socket._address.listen(.{});
const connection = try server.accept();
_ = connection;
}
此代码示例只允许一个连接。换句话说,服务器将等待一个传入连接,一旦服务器处理完它建立的第一个连接,程序就会结束,服务器也会停止运行。
这在现实世界中并不常见。大多数编写此类 HTTP 服务器的人通常会将该accept()方法放在一个while(无限)循环中,如果使用 创建一个连接accept(),就会创建一个新的执行线程来处理这个新连接和客户端。也就是说,现实世界中的 HTTP 服务器示例通常依赖于并行计算来工作。
通过这种设计,服务器只需接受连接,而处理客户端、接收 HTTP 请求和发送 HTTP 响应的整个过程都在后台的单独执行线程中完成。
因此,一旦服务器接受连接并创建单独的线程,服务器就会回到之前的操作,即无限期地等待新的连接接受。考虑到这一点,上面展示的代码示例是一个仅服务于单个客户端的服务器。因为程序在连接接受后立即终止。
7.4.3读取客户端的消息
现在我们已经建立了连接,也就是通过accept()函数创建的连接对象,我们可以用这个连接对象读取客户端发送给服务器的任何消息。当然,我们也可以用它来将消息发回给客户端。
基本思路是,如果我们向这个连接对象写入任何数据,那么我们就是在向客户端发送数据;如果我们读取这个连接对象中的数据,那么我们就是在读取客户端通过这个连接对象发送给我们的任何数据。所以,记住这个逻辑就行了。“读取”表示从客户端读取消息,“写入”表示向客户端发送消息。
还记得7.2 节中提到过,我们需要做的第一件事就是读取客户端发送给服务器的 HTTP 请求。因为这是建立连接后发生的第一条消息,因此,也是我们需要处理的第一件事。
因此,我将在这个小项目中创建一个新的 Zig 模块,命名为 ,request.zig以便将所有与 HTTP 请求相关的函数集中在一起。然后,我将创建一个名为 的新函数read_request(),它将使用我们的连接对象读取客户端发送的消息,即 HTTP 请求。
const std = @import("std");
const Connection = std.net.Server.Connection;
pub fn read_request(conn: Connection,
buffer: []u8) !void {
const reader = conn.stream.reader();
_ = try reader.read(buffer);
}
此函数接受一个充当缓冲区的切片对象作为参数。该read_request()函数读取发送到连接对象的消息,并将该消息保存到我们作为输入提供的缓冲区对象中。
请注意,我使用我们创建的连接对象来读取来自客户端的消息。我首先访问reader连接对象内部的对象。然后,我调用read()该reader对象的方法,有效地读取客户端发送的数据并将其保存到我们之前创建的缓冲区对象中。我丢弃了该read()方法的返回值,并将其赋值给下划线字符 ( _),因为这个返回值目前对我们没什么用。
7.5查看程序的当前状态
我想现在是时候看看我们的程序目前运行情况了。好吗?所以,我要做的第一件事是更新main.zig我们小型 Zig 项目中的模块,以便main()函数调用read_request()我们刚刚创建的新函数。我还会在函数末尾添加一个打印语句main(),这样你就能看到我们刚刚加载到缓冲区对象中的 HTTP 请求是什么样子的。
另外,我在函数中创建了缓冲区对象main(),该对象将负责存储客户端发送的消息,并且我还使用for循环将此缓冲区对象的所有字段初始化为零。这一点很重要,以确保此对象中没有未初始化的内存。因为未初始化的内存可能会导致程序中出现未定义的行为。
由于该read_request()函数应该将缓冲区对象作为切片对象([]u8)接收作为输入,因此我使用语法array[0..array.len]来访问该buffer对象的切片。
const std = @import("std");
const SocketConf = @import("config.zig");
const Request = @import("request.zig");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const socket = try SocketConf.Socket.init();
try stdout.print("Server Addr: {any}\n", .{socket._address});
var server = try socket._address.listen(.{});
const connection = try server.accept();
var buffer: [1000]u8 = undefined;
for (0..buffer.len) |i| {
buffer[i] = 0;
}
_ = try Request.read_request(
connection, buffer[0..buffer.len]
);
try stdout.print("{s}\n", .{buffer});
}
现在,我将使用编译器run的命令来执行这个程序zig。但请记住,正如我们之前提到的,一旦我执行这个程序,它就会无限期地挂起,因为它正在等待客户端尝试连接到服务器。
更具体地说,程序会在调用该accept()函数的那一行暂停。一旦客户端尝试连接服务器,程序就会“恢复暂停”,accept()最终执行该函数来创建我们需要的连接对象,然后程序的剩余部分将继续运行。
您可以在图 7.1中看到。消息Server Addr: 127.0.0.1:3490已打印到控制台,程序现在正在等待传入连接。
图7.1:程序运行截图
我们终于可以尝试连接到该服务器了,有几种方法可以做到这一点。例如,我们可以使用以下 Python 脚本:
import requests
requests.get("http://127.0.0.1:3490")
或者,我们也可以打开任何我们喜欢的 Web 浏览器,然后输入 URL localhost:3490。OBS:localhost与 IP 相同127.0.0.1。当您按下 Enter 键,Web 浏览器转到此地址时,首先,浏览器可能会打印一条消息,提示“此页面无法正常工作”,然后,它可能会更改为一条新消息,提示“无法访问该网站”。
您在 Web 浏览器中看到这些“错误消息”,是因为它没有收到服务器的响应。换句话说,当 Web 浏览器连接到我们的服务器时,它确实通过已建立的连接发送了 HTTP 请求。然后,Web 浏览器期望收到 HTTP 响应,但却没有收到服务器的响应(我们尚未实现 HTTP 响应逻辑)。
但这没关系。我们已经实现了目前想要的结果,即连接到服务器,并查看 Web 浏览器(或 Python 脚本)向服务器发送的 HTTP 请求。
如果您在执行程序后返回到之前打开的控制台,您将看到程序已完成执行,并且控制台中打印了一条新消息,这是 Web 浏览器向服务器发送的实际 HTTP 请求消息。您可以在图 7.2中看到此消息。
图 7.2:Web 浏览器发送的 HTTP 请求的屏幕截图
7.6了解 Zig 中的枚举
在 Zig 中,枚举结构可以通过enum关键字使用。枚举(“enumeration” 的缩写)是一种表示一组常量值的特殊结构。因此,如果您有一个变量可以假设一组简短且已知的值,则可能需要将此变量与枚举结构关联,以确保此变量仅假设该集合中的值。
枚举的一个经典示例是原色。如果出于某种原因,你的程序需要表示一种原色,你可以创建一个表示其中一种颜色的枚举。在下面的例子中,我们创建了一个枚举PrimaryColorRGB,它表示 RGB 颜色系统中的一种原色。通过使用此枚举,我可以保证对象acolor将包含以下三个值之一:RED、GREEN或BLUE。
const PrimaryColorRGB = enum {
RED, GREEN, BLUE
};
const acolor = PrimaryColorRGB.RED;
_ = acolor;
如果出于某种原因,我的代码尝试将acolor一个不在该集合中的值保存到 中,我会收到一条错误消息,警告我枚举中不存在诸如“MAGENTA”之类的值PrimaryColorRGB。这样我就可以轻松地修复我的错误。
const acolor = PrimaryColorRGB.MAGENTA;
e1.zig:5:36: error: enum 'PrimaryColorRGB' has
no member named 'MAGENTA':
const acolor = PrimaryColorRGB.MAGENTA;
^~~~~~~
在底层,Zig 中的枚举的工作方式与 C 语言中的枚举相同。每个枚举值本质上都表示为一个整数。集合中的第一个值表示为零,然后第二个值表示为一,……等等。
下一节我们将学习的一件事是枚举中可以包含方法。等等……什么?这太神奇了!是的,Zig 中的枚举类似于结构体,它们内部可以包含私有方法和公共方法。
7.7实现服务器 - 第 2 部分
现在,在本节中,我将重点介绍如何解析从客户端收到的 HTTP 请求。但是,为了有效地解析 HTTP 请求消息,我们首先需要了解其结构。总而言之,HTTP 请求是一条文本消息,它分为三个不同的部分(或部分):
- 顶级标头指示 HTTP 请求的方法、URI 和消息中使用的 HTTP 版本。
- HTTP 标头列表。
- HTTP 请求的主体。
7.7.1顶级标题
HTTP 请求的第一行文本总是包含有关该请求的三个最重要的信息。这三个关键属性在请求的第一行中用一个空格分隔。第一行信息是请求中使用的 HTTP 方法;第二行是此 HTTP 请求的目标 URI;第三行是此 HTTP 请求中使用的 HTTP 协议版本。
在下面的代码片段中,您可以找到 HTTP 请求中第一行的示例。首先,我们有此请求的 HTTP 方法(GET)。许多程序员将 URI 组件(/users/list)称为 HTTP 请求要发送到的“API 端点”。在这个特定请求的上下文中,由于它是一个 GET 请求,您也可以说 URI 组件是我们要访问的资源的路径,或者,是我们想要从服务器检索的文档(或文件)的路径。
GET /users/list HTTP/1.1
另外,请注意,此 HTTP 请求使用的是 HTTP 协议 1.1 版本,这是 Web 上使用的最流行的协议版本。
7.7.2 HTTP 标头列表
大多数 HTTP 请求还包含一段 HTTP 标头,其中包含与该特定请求关联的属性或键值对的列表。此部分始终位于请求的“顶级标头”之后。
本章的目标是构建一个简单的 HTTP 服务器,为了简单起见,我们将忽略 HTTP 请求的这一部分。但大多数现有的 HTTP 服务器都会解析并使用这些 HTTP 标头来更改服务器响应客户端请求的方式。
例如,我们在现实世界中遇到的许多请求都带有一个名为 的 HTTP 标头Accept。在此标头中,我们可以找到一个MIME 类型3的列表。此列表指示客户端可以读取、解析或解释的文件格式。换句话说,您也可以将此标头解释为客户端向服务器发出以下信息:“嘿!看,我只能读取 HTML 文档,所以请给我发送一个 HTML 格式的文档。”
如果 HTTP 服务器能够读取并使用此Accept标头,那么它就能识别出发送给客户端的文档的最佳文件格式。HTTP 服务器可能拥有同一份文档的多种格式,例如 JSON、XML、HTML 和 PDF,但客户端只能理解 HTML 格式的文档。这就是此标头的作用Accept。
7.7.3正文
正文位于 HTTP 标头列表之后,是 HTTP 请求的可选部分,这意味着并非所有 HTTP 请求都会包含正文。例如,使用 GET 方法的 HTTP 请求通常不包含正文。
因为 GET 请求用于请求数据,而不是将其发送到服务器。因此,主体部分与 POST 方法更相关,后者是一种涉及将数据发送到服务器进行处理和存储的方法。
由于我们将在此项目中仅支持 GET 方法,这意味着我们也不需要关心请求的主体。
7.7.4创建 HTTP 方法枚举
每个 HTTP 请求都带有一个显式的方法。HTTP 请求中使用的方法由以下单词之一标识:
- 得到;
- 邮政;
- 选项;
- 修补;
- 删除;
- 以及其他一些方法。
每种 HTTP 方法都用于特定类型的任务。例如,POST 方法通常用于将一些数据发送到目标。换句话说,它用于将一些数据发送到 HTTP 服务器,以便服务器处理和存储这些数据。
再举一个例子,GET 方法通常用于从服务器获取内容。换句话说,每当我们希望服务器返回一些内容时,我们都会使用此方法。返回的内容可以是任何类型的内容,可以是网页、文档文件,也可以是 JSON 格式的数据。
当客户端发送 POST HTTP 请求时,服务器发送的 HTTP 响应通常只有一个目的,那就是告知客户端服务器是否成功处理并存储了数据。相反,当服务器收到 GET HTTP 请求时,它会在 HTTP 响应中发送客户端请求的内容。这表明,与 HTTP 请求相关的方法会极大地改变整个过程中各方的动态和角色。
由于 HTTP 请求的 HTTP 方法由这组非常小且特定的单词标识,因此创建一个枚举结构来表示 HTTP 方法将会很有趣。这样,我们可以轻松检查从客户端收到的 HTTP 请求是否是我们当前在小型 HTTP 服务器项目中支持的 HTTP 方法。
下面的结构Method代表了这个枚举。请注意,目前,此枚举仅包含 GET HTTP 方法。因为就本章而言,我只想实现 GET HTTP 方法。这就是为什么我没有在此枚举中包含其他 HTTP 方法的原因。
pub const Method = enum {
GET
};
现在,我认为我们应该为这个枚举结构添加两个方法。一个方法是is_supported(),它是一个返回布尔值的函数,指示我们的 HTTP 服务器是否支持输入的 HTTP 方法。另一个方法是init(),它是一个构造函数,它接受一个字符串作为输入,并尝试将其转换为一个Method值。
但是为了构建这些函数,我将使用 Zig 标准库中的一项功能StaticStringMap()。此函数允许我们创建一个从字符串到枚举值的简单映射。换句话说,我们可以使用此映射结构将字符串映射到相应的枚举值。在某种程度上,标准库中的这个特定结构的工作原理几乎类似于“哈希表”结构,并且它针对较小的单词集或较小的键集进行了优化,这就是我们这里的情况。我们将在第 11.2 节中详细讨论 Zig 中的哈希表。
要使用这个“静态字符串映射”结构,必须从std.static_string_mapZig 标准库的模块中导入它。为了使代码更简洁、更容易输入,我将使用一个更短的名称 ( Map) 来导入此函数。
导入后Map(),我们可以将此函数应用于将在结果映射中使用的枚举结构。在本例中,它是我们在上一个代码示例中声明的枚举结构。然后,我使用映射(即我们将要使用的键值对列表)Method调用该方法。initComptime()
您可以在下面的示例中看到,我使用多个匿名结构体字面量编写了这个映射。在第一个(或“顶层”)结构体字面量中,我们有一个结构体字面量的列表(或序列)。此列表中的每个结构体字面量代表一个单独的键值对。每个键值对中的第一个元素(或键)应始终为字符串值。而第二个元素应为Map()函数内部使用的枚举结构中的值。
const Map = std.static_string_map.StaticStringMap;
const MethodMap = Map(Method).initComptime(.{
.{ "GET", Method.GET },
});
因此,该MethodMap对象本质上是std::mapC++ 中的对象,或者Python 中的对象。您可以使用map 对象中的方法dict检索(或获取)与特定键对应的枚举值。此方法返回一个可选值,因此该方法可能导致空值。get()``get()
我们可以利用这一点来检测我们的 HTTP 服务器是否支持某个特定的 HTTP 方法。因为,如果该get()方法返回 null,则意味着它没有找到我们在对象内部提供的方法MethodMap,因此,我们的 HTTP 服务器不支持该方法。
下面的方法init()接受一个字符串值作为输入,然后简单地将该字符串值传递给get()我们MethodMap对象的方法。结果,我们应该得到与该输入字符串对应的枚举值。
请注意,在下面的示例中,该init()方法要么返回错误(如果?方法返回unreacheable,则可能发生这种情况,有关更多详细信息,请参阅6.4.3 节Method),要么返回一个对象作为结果。由于GET当前是枚举结构中的唯一值Method,这意味着该init()方法很可能会返回该值Method.GET作为结果。
还要注意,在该方法中,我们使用了该方法is_supported()从对象返回的可选值。 if 语句会解开此方法返回的可选值,如果该可选值非空,则返回 。否则,它直接返回。get()``MethodMap``true``false
pub const Method = enum {
GET,
pub fn init(text: []const u8) !Method {
return MethodMap.get(text).?;
}
pub fn is_supported(m: []const u8) bool {
const method = MethodMap.get(m);
if (method) |_| {
return true;
}
return false;
}
};
7.7.5编写解析请求函数
现在我们创建了代表 HTTP 方法的枚举,我们应该开始编写负责实际解析 HTTP 请求的函数。
我们能做的第一件事是编写一个结构体来表示 HTTP 请求。以Request下面这个结构体为例,它包含了 HTTP 请求中“顶级”头部(即第一行)的三个基本信息。
const Request = struct {
method: Method,
version: []const u8,
uri: []const u8,
pub fn init(method: Method,
uri: []const u8,
version: []const u8) Request {
return Request{
.method = method,
.uri = uri,
.version = version,
};
}
};
该parse_request()函数应该接收一个字符串作为输入。此输入字符串包含完整的 HTTP 请求消息,解析函数应该读取并理解该消息的各个部分。
现在,请记住,就本章的目的而言,我们只关心此消息的第一行,其中包含“顶级标头”,或者有关 HTTP 请求的三个基本属性,即使用的 HTTP 方法、URI 和 HTTP 版本。
indexOfScalar()请注意,我使用了中的函数parse_request()。这个来自 Zig 标准库的函数返回我们提供的标量值在字符串中出现的第一个索引。在本例中,我查看的是换行符 ( \n) 的第一次出现。因为再次强调,我们只关心 HTTP 请求消息中的第一行。这一行包含了我们要解析的三个信息(HTTP 版本、HTTP 方法和 URI)。
因此,我们使用此indexOfScalar()函数将解析过程限制在消息的第一行。另外值得一提的是,该indexOfScalar()函数返回一个可选值。因此,我使用orelse关键字来提供替代值,以防函数返回的值为空。
由于这三个属性都由一个简单的空格分隔,我们可以使用splitScalar()Zig 标准库中的函数,通过查找出现简单空格的每个位置,将输入字符串拆分成多个部分。换句话说,这个splitScalar()函数相当于split()Python 中的方法,或者std::getline()C++ 中的函数,或者strtok()C 中的函数。
使用此splitScalar()函数时,您将获得一个迭代器作为结果。此迭代器具有一个next()方法,您可以使用该方法将迭代器推进到下一个位置,或者推进到分割字符串的下一部分。请注意,当您使用 时next(),该方法不仅会推进迭代器,还会返回分割字符串当前部分的切片作为结果。
现在,如果您想要获取拆分字符串当前部分的切片,但不将迭代器推进到下一个位置,则可以使用peek()方法。next()和peek()方法都返回一个可选值,因此我使用?方法来解包这些可选值。
pub fn parse_request(text: []u8) Request {
const line_index = std.mem.indexOfScalar(
u8, text, '\n'
) orelse text.len;
var iterator = std.mem.splitScalar(
u8, text[0..line_index], ' '
);
const method = try Method.init(iterator.next().?);
const uri = iterator.next().?;
const version = iterator.next().?;
const request = Request.init(method, uri, version);
return request;
}
正如我在第 1.8 节中所述,Zig 中的字符串只是语言中的字节数组。因此,您将在 Zig 标准库中找到许多可直接在此模块中使用字符串的优秀实用函数。我们已经在1.8.5 节mem中描述了其中一些有用的实用函数。
7.7.6使用解析请求函数
现在我们编写了负责解析 HTTP 请求的函数,我们可以在程序的函数parse_request()中添加函数调用。main()
之后,最好再测试一下程序的状态。我用编译器run的命令再次执行这个程序zig,然后,我用浏览器通过 URL 再次连接到服务器localhost:3490,最后,将Request对象的最终结果打印到控制台上。
快速观察一下,由于我在打印语句中使用了格式说明符,因此结构体的any数据成员version和被打印为原始整数值。在 Zig 中,将字符串数据打印为整数值很常见,请记住,这些整数值只是构成相关字符串的字节的十进制表示。uri``Request
在下面的结果中,十进制值序列 72、84、84、80、47、49、46、49 和 13 是构成文本“HTTP/1.1”的字节。整数 47 是字符 的十进制值/,它代表了此请求中的 URI。
const std = @import("std");
const SocketConf = @import("config.zig");
const Request = @import("request.zig");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const socket = try SocketConf.Socket.init();
var server = try socket._address.listen(.{});
const connection = try server.accept();
var buffer: [1000]u8 = undefined;
for (0..buffer.len) |i| {
buffer[i] = 0;
}
try Request.read_request(
connection, buffer[0..buffer.len]
);
const request = Request.parse_request(
buffer[0..buffer.len]
);
try stdout.print("{any}\n", .{request});
}
request.Request{
.method = request.Method.GET,
.version = {72, 84, 84, 80, 47, 49, 46, 49, 13},
.uri = {47}
}
7.7.7向客户端发送 HTTP 响应
在最后一部分,我们将编写负责从服务器向客户端发送 HTTP 响应的逻辑。为了简单起见,本项目中的服务器将只发送一个包含文本“Hello world”的简单网页。
首先,我在项目中创建一个名为 的新 Zig 模块response.zig。在此模块中,我将仅声明两个函数。每个函数对应于 HTTP 响应中的特定状态代码。send_200()函数将向客户端发送状态代码为 200(表示“成功”)的 HTTP 响应。 函数将send_404()发送状态代码为 404(表示“未找到”)的响应。
这绝对不是处理 HTTP 响应最符合人体工程学且最合适的方法,但它适用于我们这里的情况。毕竟,本书只是在构建一些小项目,因此,我们编写的源代码不需要完美。它只要能正常工作就行!
const std = @import("std");
const Connection = std.net.Server.Connection;
pub fn send_200(conn: Connection) !void {
const message = (
"HTTP/1.1 200 OK\nContent-Length: 48"
++ "\nContent-Type: text/html\n"
++ "Connection: Closed\n\n<html><body>"
++ "<h1>Hello, World!</h1></body></html>"
);
_ = try conn.stream.write(message);
}
pub fn send_404(conn: Connection) !void {
const message = (
"HTTP/1.1 404 Not Found\nContent-Length: 50"
++ "\nContent-Type: text/html\n"
++ "Connection: Closed\n\n<html><body>"
++ "<h1>File not found!</h1></body></html>"
);
_ = try conn.stream.write(message);
}
需要注意的是,这两个函数都接收连接对象作为输入,并使用该write()方法将 HTTP 响应消息直接写入此通信通道。这样,连接的另一端(即客户端)就会收到该消息。
大多数实际的 HTTP 服务器都会有一个单独的函数(或单独的结构体)来有效地处理响应。它获取已解析的 HTTP 请求作为输入,然后尝试逐位构建 HTTP 响应,最后通过连接发送。
我们还将使用一个专门的结构体来表示 HTTP 响应,以及许多用于构建响应对象各个部分或组件的方法。Response以 JavaScript 运行时 Bun 创建的结构体为例。您可以在其 GitHub 项目的response.zig模块4中找到此结构体。
7.8最终结果
现在,我们可以再次更新我们的main()函数,以合并模块中的新函数response.zig。首先,我需要将此模块导入到我们的main.zig模块中,然后,我将函数调用添加到send_200()和send_404()。
请注意,我使用了 if 语句来决定调用哪个“响应函数”,特别是基于 HTTP 请求中的 URI。如果用户请求的内容(或文档)不存在于我们的服务器中,我们应该返回 404 状态码。但由于我们只有一个简单的 HTTP 服务器,没有实际的文档需要发送,因此我们只需检查 URI 是否为根路径 ( /) 即可决定调用哪个函数。
另外,请注意,我正在使用 Zig 标准库中的函数std.mem.eql()来检查字符串 from 是否uri等于字符串。我们已经在1.8.5 节"/"中描述了这个函数,所以如果您还不熟悉这个函数,请回到该节。
const std = @import("std");
const SocketConf = @import("config.zig");
const Request = @import("request.zig");
const Response = @import("response.zig");
const Method = Request.Method;
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const socket = try SocketConf.Socket.init();
try stdout.print("Server Addr: {any}\n", .{socket._address});
var server = try socket._address.listen(.{});
const connection = try server.accept();
var buffer: [1000]u8 = undefined;
for (0..buffer.len) |i| {
buffer[i] = 0;
}
try Request.read_request(connection, buffer[0..buffer.len]);
const request = Request.parse_request(
buffer[0..buffer.len]
);
if (request.method == Method.GET) {
if (std.mem.eql(u8, request.uri, "/")) {
try Response.send_200(connection);
} else {
try Response.send_404(connection);
}
}
}
现在我们已经调整了函数,现在可以执行程序,看看这些最后修改的效果了。首先,我使用编译器的命令main()再次执行程序。程序会挂起,等待客户端连接。run``zig
然后,我打开 Web 浏览器,尝试使用 URL 再次连接到服务器localhost:3490。这一次,浏览器不会显示任何错误消息,而是会打印出“Hello World”消息。因为这一次,服务器成功地向 Web 浏览器发送了 HTTP 响应,如图7.3 所示。
图 7.3:HTTP 响应中发送的 Hello World 消息
-
https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview。↩︎
-
它也可以是 IPv6 地址。但通常我们使用 IPv4 地址。↩︎
-
https://github.com/oven-sh/bun/blob/main/src/bun.js/webcore/response.zig。↩︎
8.单元测试
在本章中,我将深入探讨如何在 Zig 中进行单元测试。我们将讨论 Zig 中的测试工作流程,以及来自编译器test的命令zig。
8.1test区块介绍
在 Zig 中,单元测试写在test声明中,或者,我更喜欢称之为test块中。每个test块都使用关键字 编写test。您可以选择使用字符串文字来编写标签,该标签负责标识您正在此特定块内编写的特定单元测试组test。
在下面的示例中,我们测试两个对象(a和b)的和是否等于 4。Zigexpect()标准库中的函数接收逻辑测试作为输入。如果此逻辑测试的结果为true,则测试通过。但如果结果为false,则测试失败。
你可以在块内编写任何你想要的 Zig 代码test。这些代码的一部分可能是设置测试环境所需的命令,或者只是初始化单元测试中需要用到的一些对象。
const std = @import("std");
const expect = std.testing.expect;
test "testing simple sum" {
const a: u8 = 2;
const b: u8 = 2;
try expect((a + b) == 4);
}
1/1 file81c21dbf264e.test.testing simple sum...OKA
All 1 tests passed.
您可以test在同一个 Zig 模块上编写多个块。此外,您可以将test块与源代码混合使用,不会出现任何问题或后果。如果您将test块与常规源代码混合使用,则当您从编译器执行我们在1.2.4 节中介绍的build、build-exe或命令build-obj时,这些块将被编译器自动忽略。build-lib``zigtest
换句话说,zig编译器仅在您要求时才构建并执行单元测试。默认情况下,编译器始终忽略testZig 模块中编写的块。编译器通常仅检查这些块中是否存在语法错误test。
如果您查看 Zig 标准库1中大多数文件的源代码,您会发现这些test块是与库的正常源代码一起编写的。例如,您可以在array_list模块2中看到这一点。因此,Zig 开发人员决定采用的标准是将他们的单元测试与他们正在测试的功能的源代码放在一起。
每个程序员对此可能有不同的看法。有些人可能更喜欢将单元测试与应用程序的实际源代码分开。如果是这种情况,您只需tests在项目中创建一个单独的文件夹,然后开始编写仅包含单元测试的 Zig 模块(例如,就像在 Python 项目中通常使用的那样pytest),一切都会正常工作。归根结底,这取决于您的偏好。
8.2如何运行测试
如果zig编译器默认忽略任何test块,那么如何编译和运行单元测试呢?答案是编译器test的命令zig。通过运行该zig test命令,编译器将找到testZig 模块中每个块的实例,并且它将编译并运行您编写的单元测试。
zig test simple_sum.zig
1/1 simple_sum.test.testing simple sum... OK
All 1 tests passed.
8.3测试内存分配
Zig 的优势之一是它提供了一些很棒的工具,可以帮助我们程序员避免(同时也能检测)内存问题,例如内存泄漏和双重释放。defer关键字在这方面尤其有用。
在开发源代码时,程序员有责任确保您的代码不会产生此类问题。但是,您也可以在 Zig 中使用一种特殊类型的分配器对象,它能够自动为您检测此类问题。这就是该std.testing.allocator对象。此分配器对象提供了一些基本的内存安全检测功能,能够检测内存泄漏。
正如我们在3.1.5 节中所述,要在堆上分配内存,需要使用分配器对象。使用这些对象在堆上分配内存的函数应该接收一个分配器对象作为其输入之一。使用这些分配器对象分配的堆上所有内存,也必须使用同一个分配器对象进行释放。
因此,如果您想测试函数执行的内存分配,并确保这些分配没有问题,您可以简单地为这些函数编写单元测试,其中将std.testing.allocator对象作为这些函数的输入。
请看下面的示例,我定义了一个明显会导致内存泄漏的函数。因为我们分配了内存,但同时却没有在任何时候释放这块分配的内存。因此,当函数返回时,我们会失去对buffer包含这块分配内存的对象的引用,因此,我们无法再释放这块内存。
请注意,test我在代码块中使用了 来执行此函数std.testing.allocator。分配器对象能够深入我们的程序,并检测内存泄漏。结果,此分配器对象返回“内存泄漏”的错误消息,以及显示内存泄漏确切位置的堆栈跟踪。
const std = @import("std");
const Allocator = std.mem.Allocator;
fn some_memory_leak(allocator: Allocator) !void {
const buffer = try allocator.alloc(u32, 10);
_ = buffer;
// Return without freeing the
// allocated memory
}
test "memory leak" {
const allocator = std.testing.allocator;
try some_memory_leak(allocator);
}
Test [1/1] leak_memory.test.memory leak...
[gpa] (err): memory address 0x7c1fddf39000 leaked:
./ZigExamples/debugging/leak_memory.zig:4:39: 0x10395f2
const buffer = try allocator.alloc(u32, 10);
^
./ZigExamples/debugging/leak_memory.zig:12:25: 0x10398ea
try some_memory_leak(allocator);
... more stack trace
8.4测试错误
一种常见的单元测试风格是查找函数中的特定错误。换句话说,你编写一个单元测试,尝试断言特定函数调用是否返回任何错误,或返回特定类型的错误。
在 C++ 中,你通常会使用测试框架3中的函数REQUIRE_THROWS()或CHECK_THROWS()来编写这种风格的单元测试。对于 Python 项目,你可能会使用4中的函数。而在 Rust 中,你可能会结合使用。Catch2raises()``pytestassert_eq!()``Err()
但在 Zig 中,我们使用模块expectError()中的函数std.testing。使用此函数,您可以测试特定的函数调用是否返回您期望的确切错误类型。要使用此函数,首先编写try expectError()。然后,在第一个参数中,提供您期望从函数调用中得到的错误类型。然后,在第二个参数中,编写您期望失败的函数调用。
下面的代码示例演示了 Zig 中此类单元测试。请注意,在函数内部,alloc_error()我们为对象分配了 100 个字节的内存,或者说是一个包含 100 个元素的数组ibuffer。但是,在test块中,我们使用的FixedBufferAllocator()分配器对象空间限制为 10 个字节,因为buffer我们提供给分配器对象的对象只有 10 个字节的空间。
这就是为什么alloc_error()函数在这种情况下会引发OutOfMemory错误。因为该函数试图分配的空间超过了分配器对象允许的空间。所以,本质上,我们正在测试一种特定类型的错误,即OutOfMemory。如果alloc_error()函数返回任何其他类型的错误,那么该expectError()函数将导致整个测试失败。
const std = @import("std");
const Allocator = std.mem.Allocator;
const expectError = std.testing.expectError;
fn alloc_error(allocator: Allocator) !void {
var ibuffer = try allocator.alloc(u8, 100);
defer allocator.free(ibuffer);
ibuffer[0] = 2;
}
test "testing error" {
var buffer: [10]u8 = undefined;
var fba = std.heap.FixedBufferAllocator.init(&buffer);
const allocator = fba.allocator();
try expectError(error.OutOfMemory, alloc_error(allocator));
}
1/1 file81c24fea00d1.test.testing error...OKAll 1
tests passed.
8.5测试简单相等性
在 Zig 中,有一些不同的方法可以测试相等性。您已经看到,我们可以expect()与逻辑运算符一起使用==来重现相等性测试。但我们还有一些其他的辅助函数您应该了解,尤其是expectEqual()、expectEqualSlices()和expectEqualStrings()。
expectEqual()顾名思义,该函数是一个经典的相等性测试函数。它接收两个对象作为输入。第一个对象是你期望第二个对象中的值。而第二个对象是你拥有的对象,或者说是你的应用程序生成的对象。因此,expectEqual()你实际上是在测试这两个对象中存储的值是否相等。
您可以在下面的示例中看到,执行的测试expectEqual()失败了。因为对象v1和v2包含不同的值。
const std = @import("std");
test "values are equal?" {
const v1 = 15;
const v2 = 18;
try std.testing.expectEqual(v1, v2);
}
1/1 ve.test.values are equal?...
expected 15, found 18
FAIL (TestExpectedEqual)
ve.zig:5:5: test.values are equal? (test)
try std.testing.expectEqual(v1, v2);
^
0 passed; 0 skipped; 1 failed.
虽然该expectEqual()函数很有用,但它不适用于数组。要测试两个数组是否相等,应该使用expectEqualSlices()函数。该函数有三个参数。首先,提供要比较的两个数组中包含的数据类型。第二个和第三个参数对应于要比较的数组对象。
在下面的示例中,我们使用此函数测试两个数组对象(array1和array2)是否相等。由于它们确实相等,因此单元测试顺利通过,没有任何错误。
const std = @import("std");
test "arrays are equal?" {
const array1 = [3]u32{1, 2, 3};
const array2 = [3]u32{1, 2, 3};
try std.testing.expectEqualSlices(
u32, &array1, &array2
);
}
1/1 file81c25513148.test.arrays are equal?...OKAll
l 1 tests passed.
最后,您可能还想使用expectEqualStrings()函数。顾名思义,您可以使用此函数来测试两个字符串是否相等。只需将要比较的两个字符串对象作为函数的输入即可。
如果函数发现两个字符串之间存在任何差异,那么函数将引发错误,并且打印一条错误消息,显示所提供的两个字符串对象之间的确切差异,如下例所示:
const std = @import("std");
test "strings are equal?" {
const str1 = "hello, world!";
const str2 = "Hello, world!";
try std.testing.expectEqualStrings(
str1, str2
);
}
1/1 t.test.strings are equal?...
====== expected this output: =========
hello, world!␃
======== instead found this: =========
Hello, world!␃
======================================
First difference occurs on line 1:
expected:
hello, world!
^ ('\x68')
found:
Hello, world!
^ ('\x48')
-
https://github.com/ziglang/zig/blob/master/lib/std/array_list.zig ↩︎
-
https://docs.pytest.org/en/7.1.x/reference/reference.html#pytest-raises ↩︎
9 构建系统
在本章中,我们将讨论构建系统,以及如何在 Zig 中构建整个项目。Zig 的一个关键优势是它包含一个嵌入在语言本身中的构建系统。这非常棒,因为这样你就不必依赖与编译器分离的外部系统来构建代码了。
您可以在Zig 官方网站上题为“构建系统”的文章1中找到对 Zig 构建系统的详细描述。我们还有Felix 撰写的一系列精彩文章2。因此,本章将是您参考和依赖的额外资源。
构建代码是 Zig 最擅长的事情之一。在 C/C++ 甚至 Rust 中,有一件事特别困难,那就是将源代码交叉编译到多个目标(例如,多个计算机架构和操作系统),而 Zigzig编译器被认为是目前最适合这项特定任务的软件之一。
9.1源代码是如何构建的?
我们已经在1.2.1 节中讨论过使用低级语言构建源代码所面临的挑战。正如我们在那一节中所描述的,程序员发明了构建系统 (Build Systems) 来克服使用低级语言构建源代码过程中的这些挑战。
低级语言使用编译器将源代码编译(或构建)成二进制指令。在 C 和 C++ 中,我们通常使用诸如gcc、g++或 之类的编译器clang将 C 和 C++ 源代码编译成这些指令。每种语言都有自己的编译器,Zig 也不例外。
在 Zig 中,我们有zig编译器将 Zig 源代码编译成计算机可以执行的二进制指令。在 Zig 中,编译(或构建)过程涉及以下组件:
- 包含您的源代码的 Zig 模块;
- 库文件(动态库或静态库);
- 编译器标志可根据您的需要定制构建过程。
这些是在 Zig 中构建源代码所需的连接内容。在 C 和 C++ 中,你会有一个额外的组件,即你正在使用的库的头文件。但是 Zig 中没有头文件,所以只有在将 Zig 源代码与 C 库链接时才需要关心它们。如果不是这种情况,你可以不用管它。
您的构建过程通常组织在构建脚本中。在 Zig 中,我们通常将此构建脚本写入项目根目录中的 Zig 模块中,名为build.zig。您编写此构建脚本,然后,当您运行它时,您的项目将被构建为二进制文件,您可以使用这些文件并将其分发给用户。
此构建脚本通常围绕_目标对象_进行组织。目标就是要构建的东西,或者换句话说,就是你希望zig编译器为你构建的东西。“目标”这个概念存在于大多数构建系统中,尤其是在 CMake 3中。
您可以在 Zig 中构建四种类型的目标对象,分别是:
- 可执行文件(例如
.exeWindows 上的文件)。 - 共享库(例如
.soLinux 中的文件或.dllWindows 上的文件)。 - 静态库(例如
.aLinux 中的文件或.libWindows 上的文件)。 - 仅执行单元测试的可执行文件(或“单元测试可执行文件”)。
我们将在第 9.3 节详细讨论这些目标对象。
9.2函数build()
Zig 中的构建脚本始终包含声明的公共(和顶级)build()函数。它类似于我们在1.2.3 节main()中讨论过的项目主 Zig 模块中的函数。但是,此函数不是创建代码的入口点,而是构建过程的入口点。build()
此build()函数应接受指向对象的指针Build作为输入,并使用这个“构建对象”执行构建项目所需的步骤。此函数的返回类型始终为void,并且此Build结构体直接来自 Zig 标准库(std.Build)。因此,您只需将 Zig 标准库导入build.zig模块即可访问此结构体。
仅作为一个非常简单的例子,这里您可以看到从 Zig 模块构建可执行文件所需的源代码hello.zig。
const std = @import("std");
pub fn build(b: *std.Build) void {
const exe = b.addExecutable(.{
.name = "hello",
.root_source_file = b.path("hello.zig"),
.target = b.host,
});
b.installArtifact(exe);
}
您可以在此构建脚本中定义和使用其他函数和对象。您还可以像在项目中的任何其他模块中一样导入其他 Zig 模块。此构建脚本的唯一实际要求是定义一个公共的顶级build()函数,该函数接受指向结构体的指针Build作为输入。
9.3目标对象
正如我们在前几节中所述,构建脚本围绕目标对象构建。每个目标对象通常都是您希望从构建过程中获取的二进制文件(或输出)。您可以在构建脚本中列出多个目标对象,以便构建过程一次性为您生成多个二进制文件。
例如,也许您是一位跨平台应用程序的开发者,由于该应用程序是跨平台的,您可能需要向最终用户发布针对该应用程序支持的每个操作系统的二进制文件。因此,您可以在构建脚本中为要发布软件的每个操作系统(Windows、Linux 等)定义不同的目标对象。这将使编译zig器能够一次性将您的项目构建到多个目标操作系统。Zig Build System 官方文档中有一个很棒的代码示例4演示了这一策略。
Build目标对象由我们在第 9.2 节中介绍的结构体的以下方法创建:
addExecutable()创建一个可执行文件;addSharedLibrary()创建共享库文件;addStaticLibrary()创建静态库文件;addTest()创建执行单元测试的可执行文件。
这些函数是来自Build结构体的方法,这些方法作为函数的输入build()。它们都会创建一个Compile对象作为输出,该对象表示zig编译器要编译的目标对象。所有这些函数都接受类似的结构体字面量作为输入。该结构体字面量定义了关于您正在构建的目标对象的三个基本规范:name、target和root_source_file。
我们已经在上一个示例中看到了这三个选项的用法,其中我们使用了addExecutable()方法来创建一个可执行的目标对象。此示例如下所示。请注意结构体path()中 方法的使用Build,它在选项中定义了一个路径root_source_file。
const exe = b.addExecutable(.{
.name = "hello",
.root_source_file = b.path("hello.zig"),
.target = b.host,
});
该name选项指定要赋予此目标对象定义的二进制文件的名称。因此,在本例中,我们将构建一个名为 的可执行文件hello。通常将此name选项设置为项目名称。
此外,该target选项指定了此二进制文件的目标计算机体系结构(或目标操作系统)。例如,如果您希望此目标对象在使用特定x86_64体系结构的 Windows 计算机上运行,则可以将此target选项设置为x86_64-windows-gnu。这将使zig编译器将项目编译为在 Windows 计算机上运行。您可以通过在终端中运行该命令来x86_64查看编译器支持的完整体系结构和操作系统列表。zig``zig targets
现在,如果您要构建项目以在当前用于运行此构建脚本的机器上运行,则可以将此target选项设置为对象host的方法Build,就像我们在上面的示例中所做的那样。此host方法标识当前运行zig编译器的机器。
最后,该root_source_file选项指定项目的根 Zig 模块。该 Zig 模块包含应用程序的入口点(即main()函数),或者库的主要 API。这也意味着,构成项目的所有 Zig 模块都会自动从此“根源文件”中的 import 语句中发现。zig编译器可以通过 import 语句检测 Zig 模块何时依赖于其他模块,从而发现项目中使用的完整 Zig 模块映射。
这很方便,而且与其他构建系统不同。例如,在 CMake 中,您必须明确列出要包含在构建过程中的所有源文件的路径。这可能是 C 和 C++ 编译器“缺乏条件编译”的症状。由于它们缺乏此功能,您必须明确选择要将哪些源文件发送到 C/C++ 编译器,因为并非所有 C/C++ 代码都可移植或受所有操作系统支持,因此会导致 C/C++ 编译器出现编译错误。
现在,关于构建过程的一个重要细节是,您必须使用结构的方法明确安装在构建脚本中创建的目标对象。installArtifact()``Build
build每次通过调用编译器命令来启动项目的构建过程时,都会在项目的根目录中创建zig一个名为 的新目录zig-out。此新目录包含构建过程的输出,即从源代码构建的二进制文件。
该installArtifact()方法的作用是将您定义的构建目标对象安装(或复制)到此zig-out目录。这意味着,如果您没有安装在构建脚本中定义的目标对象,那么这些目标对象在构建过程结束时基本上会被丢弃。
例如,您可能正在构建一个使用第三方库的项目,而该库是与项目一起构建的。因此,在构建项目时,您首先需要构建第三方库,然后将其链接到项目的源代码。因此,在这种情况下,我们在构建过程中会生成两个二进制文件(项目的可执行文件和第三方库)。但只有一个文件值得关注,即我们项目的可执行文件。我们可以丢弃第三方库的二进制文件,只需不将其安装到此zig-out目录中即可。
这个installArtifact()方法很简单。只需记住将它应用于要保存到zig-out目录的每个目标对象即可,如下例所示:
const exe = b.addExecutable(.{
.name = "hello",
.root_source_file = b.path("hello.zig"),
.target = b.host,
});
b.installArtifact(exe);
9.4设置构建模式
我们已经讨论了创建新目标对象时设置的三个基本选项。但还有第四个选项可用于设置此目标对象的构建模式,即选项optimize。之所以这样称呼此选项,是因为 Zig 中的构建模式更多地被视为“优化与安全”问题。因此,优化在这里起着重要作用。别担心,我很快会回到这个问题上。
在 Zig 中,我们有四种构建模式(如下所示)。每一种构建模式都具有不同的优势和特点。正如我们在第 5.2.1 节中所述,当您没有明确选择构建模式时,zig编译器默认使用构建模式。Debug
Debug,在构建过程的输出(即目标对象定义的二进制文件)中产生并包含调试信息的模式;ReleaseSmall,尝试生成较小二进制文件的模式;ReleaseFast,尝试优化代码的模式,以便尽可能快地生成二进制文件;ReleaseSafe,通过在可能的情况下采取保护措施,尝试使您的代码尽可能安全。
因此,在构建项目时,您可以将目标对象的构建模式设置为ReleaseFast例如,这将指示zig编译器在代码中应用重要的优化。这会创建一个二进制文件,该文件在大多数情况下运行速度更快,因为它包含代码的更优化版本。然而,结果往往会导致代码中丢失一些安全特性。因为一些安全检查从最终的二进制文件中移除,这虽然会使代码运行速度更快,但安全性却有所降低。
这个选择取决于你当前的优先级。如果你正在构建加密或银行系统,你可能更倾向于优先考虑代码的安全性,因此,你会选择ReleaseSafe构建模式,这种模式运行速度稍慢,但更安全,因为它在构建过程中生成的二进制文件中包含了所有可能的运行时安全检查。另一方面,如果你正在编写游戏,你可能更倾向于优先考虑性能而不是安全性,使用ReleaseFast构建模式,这样你的用户就可以在游戏中体验到更快的帧率。
在下面的示例中,我们创建了与之前示例相同的目标对象。但这次,我们将此目标对象的构建模式指定为ReleaseSafemode。
const exe = b.addExecutable(.{
.name = "hello",
.root_source_file = b.path("hello.zig"),
.target = b.host,
.optimize = .ReleaseSafe
});
b.installArtifact(exe);
9.5设置构建版本
每次在构建脚本中构建目标对象时,都可以按照语义版本控制框架为该特定构建分配一个版本号。您可以访问语义版本控制网站5SemanticVersion了解有关语义版本控制的更多信息。无论如何,在 Zig 中,您可以通过向选项提供一个结构体来指定构建的版本,version如下例所示:
const exe = b.addExecutable(.{
.name = "hello",
.root_source_file = b.path("hello.zig"),
.target = b.host,
.version = .{
.major = 2, .minor = 9, .patch = 7
}
});
b.installArtifact(exe);
9.6在构建脚本中检测操作系统
在构建系统中,根据构建过程中所针对的操作系统 (OS) 使用不同的选项、包含不同的模块或链接不同的库是很常见的。
os.tag在 Zig 中,您可以通过查看 Zig 库中的模块内部来检测构建过程的目标操作系统builtin。在下面的示例中,当构建过程的目标是 Windows 系统时,我们使用 if 语句来运行一些任意代码。
const builtin = @import("builtin");
if (builtin.target.os.tag == .windows) {
// Code that runs only when the target of
// the compilation process is Windows.
}
9.7在构建过程中添加运行步骤
Rust 的一个巧妙之处在于,你可以使用cargo runRust 编译器中的一个命令 ( ) 来编译和运行源代码。我们在1.2.5 节run中看到了如何在 Zig 中执行类似的工作,即通过编译器的命令构建和运行 Zig 源代码zig。
但是,我们如何才能同时构建并运行构建脚本中目标对象指定的二进制文件呢?答案是,在构建脚本中包含一个“运行工件”。运行工件是通过结构体addRunArtifact()中的方法创建的Build。我们只需将描述我们要执行的二进制文件的目标对象作为输入提供给此函数即可。结果,此函数会创建一个能够执行此二进制文件的运行工件。
在下面的示例中,我们定义了一个名为的可执行二进制文件hello,并且我们使用此addRunArtifact()方法来创建将执行该可执行文件的运行工件hello。
const exe = b.addExecutable(.{
.name = "hello",
.root_source_file = b.path("src/hello.zig"),
.target = b.host
});
b.installArtifact(exe);
const run_arti = b.addRunArtifact(exe);
现在我们已经创建了这个运行构件,我们需要将其包含在构建过程中。为此,我们在构建脚本中声明一个新步骤,通过结构体step()的方法调用此构件Build。
我们可以给这个步骤起任何名字,但为了方便理解,我将其命名为“运行”。此外,我还为这个步骤提供了一个简短的描述(“运行项目”)。
const run_step = b.step(
"run", "Run the project"
);
现在我们已经声明了这个“运行步骤”,我们需要告诉 Zig,这个“运行步骤”依赖于运行构件。换句话说,运行构件始终依赖于某个“步骤”才能有效执行。通过创建此依赖关系,我们最终确定了从构建脚本构建和运行可执行文件所需的命令。
我们可以使用运行步骤中的方法在运行步骤和运行工件之间建立依赖关系dependsOn()。因此,我们首先创建运行步骤,然后使用dependsOn()运行步骤中的方法将其与运行工件链接起来。
run_step.dependOn(&run_arti.step);
我们在本节中逐一编写的这个特定构建脚本的完整源代码都可以在build_and_run.zig模块中找到。您可以访问本书的官方仓库 6来查看此模块。
当你在构建脚本中声明一个新步骤时,该步骤将通过编译器build中的命令可用zig。你实际上可以通过zig build --help在终端中运行来查看此步骤,如下例所示,我们可以看到在构建脚本中声明的这个新“运行”步骤出现在输出中。
zig build --help
Steps:
...
run Run the project
...
build现在,我们需要做的就是调用我们在构建脚本中创建的“运行”步骤。我们使用编译器命令后指定的步骤名称来调用它zig。这将使编译器构建我们的可执行文件并同时执行它。
zig build run
9.8在项目中构建单元测试
我们已经在第 8 章中详细讨论了如何在 Zig 中编写单元测试,并且还讨论了如何通过编译器test的命令执行这些单元测试zig。但是,正如我们run在上一节中对命令所做的那样,我们可能还希望在构建脚本中包含一些命令,以便在项目中构建和执行单元测试。
因此,我们将再次讨论如何在 Zig 的构建脚本中使用编译器的特定内置命令zig(在本例中为test命令)。这就是“测试目标对象”发挥作用的地方。如第 9.3 节addTest()所述,我们可以使用结构体的方法创建测试目标对象Build。我们需要做的第一件事是在构建脚本中声明一个测试目标对象。
const test_exe = b.addTest(.{
.name = "unit_tests",
.root_source_file = b.path("src/main.zig"),
.target = b.host,
});
b.installArtifact(test_exe);
测试目标对象本质上会选择test项目中所有 Zig 模块中的所有块,并仅构建项目中这些块中存在的源代码。因此,此目标对象会创建一个可执行文件,其中仅包含项目中所有这些块(即单元测试)test中存在的源代码。test
完美!现在我们已经声明了这个测试目标对象,当我们使用命令触发构建脚本时,编译器unit_tests会构建一个名为 的可执行文件。构建过程完成后,我们可以在终端中直接执行这个可执行文件。zig``build``unit_tests
但是,如果您还记得上一节,我们已经了解了如何在构建脚本中创建运行步骤,以执行由构建脚本构建的可执行文件。
因此,我们可以简单地在构建脚本中添加一个运行步骤,以便通过zig编译器中的单个命令运行这些单元测试,从而简化我们的工作。在下面的示例中,我们演示了在构建脚本中注册一个名为“tests”的新构建步骤来运行这些单元测试的命令。
const run_arti = b.addRunArtifact(test_exe);
const run_step = b.step("tests", "Run unit tests");
run_step.dependOn(&run_arti.step);
现在我们已经注册了这个新的构建步骤,我们可以通过在终端中调用以下命令来触发它。你也可以在本书官方仓库的build_tests.zig模块中查看此特定构建脚本的完整源代码7。
zig build tests
9.9使用用户提供的选项定制构建过程
有时,您需要创建一个可由项目用户自定义的构建脚本。您可以通过在构建脚本中创建用户提供的选项来实现。我们使用结构体option()中的方法来创建用户提供的选项Build。
通过这种方法,我们创建了一个“构建选项”,可以build.zig通过命令行传递给脚本。用户可以在编译器build的命令中设置此选项zig。换句话说,我们创建的每个构建选项都将成为一个新的命令行参数,可以通过build编译器的命令访问。
这些“用户提供的选项”通过在命令行中使用前缀来设置-D。例如,如果我们声明一个名为 的选项use_zlib,它接收一个布尔值,指示是否应该将源代码链接到zlib,我们可以在命令行中使用 来设置此选项的值-Duse_zlib。下面的代码示例演示了这个想法:
const std = @import("std");
pub fn build(b: *std.Build) void {
const use_zlib = b.option(
bool,
"use_zlib",
"Should link to zlib?"
) orelse false;
const exe = b.addExecutable(.{
.name = "hello",
.root_source_file = b.path("example.zig"),
.target = b.host,
});
if (use_zlib) {
exe.linkSystemLibrary("zlib");
}
b.installArtifact(exe);
}
zig build -Duse_zlib=false
9.10链接到外部库
每个构建过程的一个重要部分是链接阶段。此阶段负责将代表代码的多个目标文件组合成一个可执行文件。如果您在代码中使用了外部库,它还会将此可执行文件链接到外部库。
在 Zig 中,我们有两个“库”的概念:1)系统库;2)本地库。系统库是指系统中已安装的库。而本地库是指属于当前项目的库;它存在于项目目录中,并且与项目源代码一起构建。
两者之间的基本区别在于,系统库据称已经构建并安装在您的系统中,您只需将源代码链接到该库即可开始使用它。我们通过使用对象linkSystemLibrary()的方法来实现这一点Compile。此方法接受字符串形式的库名称作为输入。请记住,在9.3 节中,对象Compile是您在构建脚本中声明的目标对象。
当你将特定的目标文件与系统库链接时,zig编译器会pkg-config查找系统中该库的二进制文件和头文件的位置。找到这些文件后,zig编译器中的链接器会将你的目标文件与该库的文件链接起来,生成一个单独的二进制文件。
在下面的示例中,我们正在创建一个名为的可执行文件image_filter,并且我们使用方法将此可执行文件链接到 C 标准库linkLibC(),但我们也将此可执行文件链接到libpng当前安装在我的系统中的 C 库。
const std = @import("std");
pub fn build(b: *std.Build) void {
const exe = b.addExecutable(.{
.name = "image_filter",
.root_source_file = b.path("src/main.zig"),
.target = target,
.optimize = optimize,
});
exe.linkLibC();
exe.linkSystemLibrary("png");
b.installArtifact(exe);
}
如果您在项目中链接了 C 库,通常最好也将您的代码链接到 C 标准库。因为这个 C 库很可能在某些时候会用到 C 标准库的某些功能。C++ 库也是如此。因此,如果您要链接 C++ 库,最好使用该linkLibCpp()方法将您的项目链接到 C++ 标准库。
在订单方面,当您想要链接到本地库时,您应该使用对象linkLibrary()的方法Compile。此方法需要接收另一个Compile对象作为输入。也就是说,构建脚本中定义的另一个目标对象,使用addStaticLibrary()或addSharedLibrary()方法定义要构建的库。
正如我们之前所讨论的,本地库是项目本地的库,它会与项目一起构建。因此,您需要在构建脚本中创建一个目标对象来构建此本地库。然后,将项目中所需的目标对象与标识此本地库的目标对象链接起来。
看一下从libxev库8的构建脚本中提取的这个示例。您可以看到,在这个代码片段中,我们从模块中声明了一个共享库文件c_api.zig。然后,在构建脚本的后面,我们声明了一个名为 的可执行文件"dynamic-binding-test",该文件链接到我们之前在脚本中定义的共享库。
const optimize = b.standardOptimizeOption(.{});
const target = b.standardTargetOptions(.{});
const dynamic_lib = b.addSharedLibrary(.{
.name = dynamic_lib_name,
.root_source_file = b.path("src/c_api.zig"),
.target = target,
.optimize = optimize,
});
b.installArtifact(dynamic_lib);
// ... more lines in the script
const dynamic_binding_test = b.addExecutable(.{
.name = "dynamic-binding-test",
.target = target,
.optimize = optimize,
});
dynamic_binding_test.linkLibrary(dynamic_lib);
9.11构建 C 代码
该zig编译器内置了一个 C 编译器。换句话说,您可以使用该编译器来构建 C 项目。您可以通过编译器的命令zig来调用该 C 编译器。cc``zig
举个例子,我们来使用著名的FreeType 库9。FreeType 是世界上使用最广泛的软件之一。它是一个用 C 语言编写的库,旨在生成高质量的字体。但它也在业界被广泛使用,用于在计算机屏幕上原生渲染文本和字体。
在本节中,我们将逐步编写一个构建脚本,该脚本能够从源代码构建 FreeType 项目。您可以在 GitHub 的freetype-zig仓库10中找到此构建脚本的源代码。
从官方网站11下载 FreeType 源代码后,就可以开始编写build.zig模块了。我们首先定义目标对象,该对象定义了我们要编译的二进制文件。
addStaticLibrary()作为示例,我将使用创建目标对象的方法将项目构建为静态库文件。此外,由于 FreeType 是一个 C 库,我还将libc通过该linkLibC()方法链接该库,以确保在编译过程中涵盖所有对 C 标准库的使用。
const target = b.standardTargetOptions(.{});
const opti = b.standardOptimizeOption(.{});
const lib = b.addStaticLibrary(.{
.name = "freetype",
.optimize = opti,
.target = target,
});
lib.linkLibC();
9.11.1创建 C 编译器标志
编译器标志也被许多程序员称为“编译器选项”,在 GCC 官方文档中也被称为“命令选项”。也可以将它们称为 C 编译器的“命令行参数”。通常,我们使用编译器标志来打开(或关闭)编译器的某些功能,或者调整编译过程以满足项目需求。
在用 Zig 编写的构建脚本中,我们通常在一个简单的数组中列出编译过程中要使用的 C 编译器标志,如下例所示。
const c_flags = [_][]const u8{
"-Wall",
"-Wextra",
"-Werror",
};
理论上,没有什么可以阻止您使用此数组向编译过程添加“包含路径”(带有-I标志)或“库路径”(带有标志)。但是 Zig 中有正式的方法可以在编译过程中添加这些类型的路径。这两部分都将在第 9.11.5 节和第 9.11.4 节-L中讨论。
addCSourceFile()无论如何,在 Zig 中,我们使用和方法将 C 标志与要编译的 C 文件一起添加到构建过程中addCSourceFiles()。在上面的示例中,我们刚刚声明了要使用的 C 标志。但我们还没有将它们添加到构建过程中。为此,我们还需要列出要编译的 C 文件。
9.11.2列出你的 C 文件
包含“跨平台”源代码的 C 文件列在c_source_files下面的对象中。这些 C 文件默认包含在 FreeType 库支持的每个平台上。由于 FreeType 库中的 C 文件数量庞大,为了简洁起见,我在下面的代码示例中省略了其余文件。
const c_source_files = [_][]const u8{
"src/autofit/autofit.c",
"src/base/ftbase.c",
// ... and many other C files.
};
现在,除了“跨平台”源代码之外,FreeType 项目中还有一些平台特定的 C 文件。这意味着,它们包含只能在特定平台上编译的源代码,因此,它们只会包含在这些特定目标平台上的构建过程中。列出这些 C 文件的对象在下面的代码示例中公开。
const windows_c_source_files = [_][]const u8{
"builds/windows/ftdebug.c",
"builds/windows/ftsystem.c"
};
const linux_c_source_files = [_][]const u8{
"src/base/ftsystem.c",
"src/base/ftdebug.c"
};
现在我们已经声明了想要包含的文件和要使用的 C 编译器标志,我们可以使用addCSourceFile()和addCSourceFiles()方法将它们添加到描述 FreeType 库的目标对象中。
这两个函数都是Compile对象(即目标对象)的方法。 该addCSourceFile()方法能够将单个 C 文件添加到目标对象,而 则addCSourceFiles()用于在单个命令中添加多个 C 文件。addCSourceFile()当您需要在项目中的特定 C 文件上使用不同的编译器标志时,您可能更喜欢使用 。但是,如果您可以在所有 C 文件中使用相同的编译器标志,那么您可能会找到addCSourceFiles()更好的选择。
请注意,我们使用了addCSourceFiles()以下示例中的方法,来添加 C 文件和 C 编译器标志。另请注意,我们使用了9.6 节os.tag中介绍的方法来添加平台特定的 C 文件。
const builtin = @import("builtin");
lib.addCSourceFiles(
&c_source_files, &c_flags
);
switch (builtin.target.os.tag) {
.windows => {
lib.addCSourceFiles(
&windows_c_source_files,
&c_flags
);
},
.linux => {
lib.addCSourceFiles(
&linux_c_source_files,
&c_flags
);
},
else => {},
}
9.11.3定义 C 宏
-DC 宏是 C 编程语言的重要组成部分,通常通过C 编译器的标志来定义。在 Zig 中,您可以使用定义defineCMacro()正在构建的二进制文件的目标对象中的方法来定义要在构建过程中使用的 C 宏。
在下面的示例中,我们使用lib前面几节中定义的对象来定义 FreeType 项目在编译过程中使用的一些 C 宏。这些 C 宏指定 FreeType 是否应该包含来自不同外部库的功能。
lib.defineCMacro("FT_DISABLE_ZLIB", "TRUE");
lib.defineCMacro("FT_DISABLE_PNG", "TRUE");
lib.defineCMacro("FT_DISABLE_HARFBUZZ", "TRUE");
lib.defineCMacro("FT_DISABLE_BZIP2", "TRUE");
lib.defineCMacro("FT_DISABLE_BROTLI", "TRUE");
lib.defineCMacro("FT2_BUILD_LIBRARY", "TRUE");
9.11.4添加库路径
库路径是计算机中 C 编译器查找(或搜索)库文件以链接到源代码的路径。换句话说,当您在 C 源代码中使用某个库,并要求 C 编译器将源代码链接到该库时,C 编译器会在“库路径”集合中列出的路径中搜索该库的二进制文件。
这些路径是平台相关的,默认情况下,C 编译器会先查看计算机中一组预定义的位置。但您可以向此列表添加更多路径(或更多位置)。例如,您可能在计算机上非常规位置安装了某个库,您可以通过将此路径添加到预定义路径列表中,让 C 编译器“看到”这个“非常规位置”。
在 Zig 中,您可以使用addLibraryPath()目标对象中的方法向此集合添加更多路径。首先,定义一个LazyPath包含要添加的路径的对象,然后将该对象作为addLibraryPath()方法的输入,如下例所示:
const lib_path: std.Build.LazyPath = .{
.cwd_relative = "/usr/local/lib/"
};
lib.addLibraryPath(lib_path);
9.11.5添加包含路径
预处理器搜索路径是 C 社区的一个流行概念,但许多 C 程序员也将其称为“包含路径”,因为此“搜索路径”中的路径与#includeC 文件中找到的语句相关。
包含路径类似于库路径。它们是计算机中一组预定义的位置,C 编译器会在编译过程中查找文件。但包含路径不是查找库文件,而是编译器查找 C 源代码中包含的头文件的位置。这就是为什么许多 C 程序员更喜欢将这些路径称为“预处理器搜索路径”。因为头文件是在编译过程的预处理器阶段处理的。
因此,每个通过 a 语句包含在 C 源代码中的头文件#include都需要在某个地方找到,并且 C 编译器会在“包含路径”集合中列出的路径中搜索该头文件。包含路径通过 标志添加到编译过程中-I。
addIncludePath()在 Zig 中,您可以使用目标对象中的方法向这组预定义的路径中添加新路径。此方法也接受LazyPath对象作为输入。
const inc_path: std.Build.LazyPath = .{
.path = "./include"
};
lib.addIncludePath(inc_path);
-
https://ziglang.org/learn/build-system/#user-provided-options ↩︎
-
https://cmake.org/cmake/help/latest/manual/cmake-buildsystem.7.html ↩︎
-
https://github.com/pedropark99/zig-book/blob/main/ZigExamples/build_system/build_and_run.zig ↩︎
-
https://github.com/pedropark99/zig-book/blob/main/ZigExamples/build_system/build_tests.zig ↩︎
10 错误处理和联合
在本章中,我想讨论如何在 Zig 中进行错误处理。我们已经简要了解了 Zig 中处理错误的可用策略之一,即1.2.3 节try中介绍的关键字。但是我们还没有了解其他方法,例如关键字。在本章中,我还想讨论如何在 Zig 中创建联合类型。catch
10.1了解有关 Zig 中错误的更多信息
在了解如何处理错误之前,我们需要进一步了解 Zig 中的错误。错误实际上是 Zig 中的一个值(Zig Software Foundation 2024a)。换句话说,当 Zig 程序内部发生错误时,这意味着 Zig 代码库中的某个地方正在生成错误值。错误值类似于您在 Zig 代码中创建的任何整数值。您可以获取错误值并将其作为输入传递给函数,也可以将其强制转换为不同类型的错误值。
这与 C++ 和 Python 中的异常有一些相似之处。因为在 C++ 和 Python 中,当代码try块内部发生异常时,你可以使用catch代码块(在 C++ 中)或except代码块(在 Python 中)来捕获代码块中产生的异常try,并将其作为输入传递给函数。
然而,Zig 中的错误值处理方式与异常截然不同。首先,您不能忽略 Zig 代码中的错误值。这意味着,如果错误值出现在源代码中的某个位置,则必须以某种方式显式处理该错误值。这也意味着您不能像处理普通值和对象那样,通过将错误值赋给下划线来丢弃它们。
以下面的源代码为例。这里我们尝试打开一个我电脑中不存在的文件,结果函数FileNotFound返回了一个明显的错误值openFile()。但由于我将这个函数的结果赋值给了一个下划线,所以我最终尝试丢弃这个错误值。
编译zig器检测到这个错误,并引发一个编译错误,告诉我我正在尝试丢弃一个错误值。它还添加了一条注释消息,建议使用try、catch或 if 语句来显式处理此错误值。这条注释强调了在 Zig 中必须显式处理每个可能的错误值。
const dir = std.fs.cwd();
_ = dir.openFile("doesnt_exist.txt", .{});
t.zig:8:17: error: error set is discarded
t.zig:8:17: note: consider using 'try', 'catch', or 'if'
10.1.1从函数返回错误
正如我们在1.2.3 节中所述,当一个函数可能返回错误值时,该函数的!返回类型标注中通常会包含一个感叹号 ( )。感叹号的存在表明该函数可能返回错误值,并且zig编译器会强制你始终显式处理该函数返回错误值的情况。
看一下print_name()下面的函数。此函数可能在函数调用中返回错误stdout.print(),因此其返回类型(!void)中包含感叹号。
fn print_name() !void {
const stdout = std.getStdOut().writer();
try stdout.print("My name is Pedro!", .{});
}
在上面的例子中,我们使用感叹号来告诉zig编译器这个函数可能会返回错误。但是这个函数究竟返回了什么错误呢?目前,我们还没有指定具体的错误值。目前,我们只知道可能会返回一些错误值(无论它是什么)。
但实际上,您可以(如果您愿意)清楚地指定此函数可能返回哪些确切的错误值。Zig 标准库中有很多这样的例子。fill()以模块中的这个函数http.Client为例。此函数返回 或 类型的错误ReadError值void。
pub fn fill(conn: *Connection) ReadError!void {
// The body of this function ...
}
指定函数预期返回的确切错误值的想法很有意思。因为它们会自动成为函数的某种文档,而且这允许zig编译器对代码执行一些额外的检查。因为编译器可以检查函数内部是否生成了其他类型的错误值,并且这些错误值没有被包含在返回类型注释中。
无论如何,你可以将函数可能返回的错误类型列在感叹号左侧,而有效值则放在感叹号右侧。因此语法格式如下:
<error-value>!<valid-value>
10.1.2错误集
_但是,当我们有一个可能返回不同类型错误的函数时该怎么办呢?当您有这样一个函数时,您可以通过 Zig 中我们称之为错误集_的结构列出可以从该函数返回的所有不同类型的错误。
错误集是联合类型的一种特例。它是一个包含错误值的联合体。并非所有编程语言都提供“联合对象”的概念。但总而言之,联合只是一组数据类型。联合用于允许一个对象拥有多种数据类型。例如, 和 的联合x表示y一个z对象可以是 类型x、 类型y或 类型z。
我们将在10.3 节中更深入地讨论联合。但是,您可以通过error在一对花括号前写入关键字来编写错误集,然后在这对花括号内列出可以从函数返回的错误值。
以resolvePath()下面的函数为例,该函数来自introspect.zigZig 标准库的模块。我们可以从其返回类型注释中看到,该函数返回以下两种结果:1)一个有效的u8值切片([]u8);或 2)错误集中列出的三种不同类型的错误值之一(OutOfMemory、Unexpected等)。这是一个错误集的使用示例。
pub fn resolvePath(
ally: mem.Allocator,
p: []const u8,
) error{
OutOfMemory,
CurrentWorkingDirectoryUnlinked,
Unexpected,
}![]u8 {
// The body of the function ...
}
这是注释 Zig 函数返回值的有效方法。但是,如果您浏览组成 Zig 标准库的模块,您会注意到,在大多数情况下,程序员更喜欢为该错误集赋予一个描述性名称,然后在返回类型注释中使用该错误集的名称(或“标签”),而不是直接使用错误集。
ReadError我们可以在之前展示的函数错误集中看到这一点fill(),该错误集是在模块中定义的http.Client。没错,我之前展示的错误集ReadError好像只是一个标准的单一错误值,但实际上,它是在http.Client模块中定义的错误集,因此,它实际上代表了函数内部可能发生的一组不同错误值fill()。
看一下ReadError下面重现的定义。注意,我们将所有这些不同的错误值分组到一个对象中,然后将这个对象用于函数的返回类型注释。就像fill()我们之前展示的函数,或者readvDirect()来自同一模块的函数(如下所示)。
pub const ReadError = error{
TlsFailure,
TlsAlert,
ConnectionTimedOut,
ConnectionResetByPeer,
UnexpectedReadFailure,
EndOfStream,
};
// Some lines of code
pub fn readvDirect(
conn: *Connection,
buffers: []std.posix.iovec
) ReadError!usize {
// The body of the function ...
}
因此,错误集只是将一组可能的错误值分组为单个对象或单个错误值类型的一种便捷方法。
10.1.3转换错误值
假设有两个不同的错误集,分别为A和B。如果错误集A是错误集的超集B,那么你可以将中的错误值强制转换B为的错误值A。
误差集只是一组误差值。因此,如果误差集A包含误差集 中的所有误差值B,则A成为 的超集B。也可以说误差集B是误差集 的子集A。
下面的例子演示了这个想法。因为A包含来自的所有值B,A所以是的超集B。用数学符号来说,我们会说一个⊃B。因此,我们可以将错误值作为函数B的输入cast(),并将此输入隐式转换为相同的错误值,但来自A集合。
const std = @import("std");
const A = error{
ConnectionTimeoutError,
DatabaseNotFound,
OutOfMemory,
InvalidToken,
};
const B = error {
OutOfMemory,
};
fn cast(err: B) A {
return err;
}
test "coerce error value" {
const error_value = cast(B.OutOfMemory);
try std.testing.expect(
error_value == A.OutOfMemory
);
}
1/1 file826379a872a1.test.coerce error value...OKA
All 1 tests passed.
10.2如何处理错误
现在我们已经了解了 Zig 中的错误,让我们讨论一下处理这些错误的可用策略,这些策略包括:
try关键词;catch关键词;- if 语句;
errdefer关键词;
10.2.1什么try意思?
正如我在前面几节中所描述的,当我们说一个表达式可能返回错误时,我们基本上指的是具有以下格式的返回类型的表达式!T。!表示此表达式返回错误值或类型的值T。
在1.2.3 节中,我介绍了该try关键字以及它的用法。但我没有讨论这个关键字对你的代码到底有什么作用,或者换句话说,我还没有解释它try在你的代码中意味着什么。
本质上,当你try在表达式中使用关键字时,你是在告诉zig编译器:“嘿!帮我执行这个表达式,如果这个表达式返回错误,请返回这个错误并停止程序的执行。但如果这个表达式返回一个有效值,那么就返回这个值,然后继续执行。”
换句话说,该try关键字本质上是一种在发生错误时进入恐慌模式并停止程序执行的策略。使用该try关键字,你是在告诉zig编译器,如果特定表达式发生错误,停止程序执行是最合理的策略。
10.2.2关键字catch
好的,现在我们正确理解了它try的含义,现在开始讨论catch。这里的一个重要细节是,您可以使用try或catch来处理错误,但不能将和一起使用try``catch。换句话说,try和catch在 Zig 语言中是完全不同的独立策略。
这种情况并不常见,与其他语言的情况不同。大多数采用_try catch_模式的编程语言(例如 C++、R、Python、JavaScript 等)通常将这两个关键字一起使用来构成完整的逻辑,以正确处理错误。无论如何,Zig 在_try catch_模式中尝试了一种不同的方法。
所以,我们已经了解了 的try含义,并且我们也知道try和catch应该单独使用,彼此分开。但是catch在 Zig 中究竟做什么呢?使用catch,我们可以构建一个逻辑块来处理错误值,以防它在当前表达式中发生。
请看下面的代码示例。我们再次回到之前的示例,当时我们尝试打开一个电脑中不存在的文件。但这次,我catch实际实现了一个逻辑来处理错误,而不是直接停止执行。
更具体地说,在这个例子中,我使用一个记录器对象在返回错误并停止程序执行之前将一些日志记录到系统中。例如,这可能是某个复杂系统代码库的某个部分,我无法完全控制它,我希望在程序崩溃之前记录这些日志,以便稍后进行调试(例如,我可能无法编译完整的程序,也无法用调试器正确地调试它。因此,记录这些日志可能是克服这一障碍的有效策略)。
const dir = std.fs.cwd();
const file = dir.openFile(
"doesnt_exist.txt", .{}
) catch |err| {
logger.record_context();
logger.log_error(err);
return err;
};
因此,我们catch创建一个表达式块来处理错误。我可以像上例一样,从这个表达式块返回错误值,这将使程序进入恐慌模式并停止执行。但我也可以从这个代码块返回一个有效值,并将其存储在file对象中。
请注意,我们不是像 那样将关键字写在可能返回错误的表达式之前,而是try写catch在表达式之后。我们可以打开竖线对 ( |),它捕获表达式返回的错误值,并将该错误值catch作为名为 的对象在代码块范围内可用err。换句话说,因为我|err|在代码中编写了 ,所以我可以使用 对象来访问表达式返回的错误值err。
虽然这是 最常见的用法catch,但您也可以使用此关键字以“默认值”的方式处理错误。也就是说,如果表达式返回错误,则使用默认值。否则,我们将使用表达式返回的有效值。
Zig 官方语言参考提供了一个很好的例子来说明这种“默认值”策略catch。此示例如下所示。请注意,我们正在尝试从名为的字符串对象中解析一些无符号整数str。换句话说,此函数正在尝试将 类型的对象[]const u8(即字符数组、字符串等)转换为 类型的对象u64。
但是函数执行的解析过程parseU64()可能会失败,从而导致运行时错误。catch本例中使用的关键字提供了一个备用值 (13),以便在函数引发错误时使用parseU64()。因此,下面的表达式本质上意味着:“嘿!请帮u64我将这个字符串解析为 ,并将结果存储到 对象 中number。但是,如果发生错误,则改用 值13。”
const number = parseU64(str, 10) catch 13;
因此,在此过程结束时,对象number将包含u64从输入字符串成功解析的整数str,或者,如果在解析过程中发生错误,它将包含关键字提供的u64值作为“默认”值或“替代”值。13``catch
10.2.3使用 if 语句
现在,您还可以使用 if 语句来处理 Zig 代码中的错误。在下面的示例中,我重现了前面的示例,我们尝试使用名为 的函数从输入字符串中解析整数值parseU64()。
我们在“if”语句中执行表达式。如果此表达式返回错误值,则不会执行 if 语句的“if 分支”(或“true 分支”)。但是,如果此表达式返回有效值,则该值将被解包到number对象中。
这意味着,如果parseU64()表达式返回一个有效值,则该值在该“if 分支”(即“true 分支”)的范围内通过我们在管道字符对(|)内列出的对象(即对象)变为可用number。
如果发生错误,我们可以使用 if 语句的“else 分支”(或“false 分支”)来处理错误。在下面的示例中,我们else在 if 语句中使用 将错误值(由 返回的parseU64())解包到err对象中,并处理错误。
if (parseU64(str, 10)) |number| {
// do something with `number` here
} else |err| {
// handle the error value.
}
现在,如果您正在执行的表达式返回不同类型的错误值,并且您想要对每种类型的错误值采取不同的操作,则try和catch关键字以及 if 语句策略就会受到限制。
对于这种情况,该语言的官方文档建议将 switch 语句与 if 语句一起使用(Zig Software Foundation 2024b)。其基本思想是,使用 if 语句执行表达式,并使用“else 分支”将错误值传递给 switch 语句,在 switch 语句中,您可以为 if 语句中执行的表达式可能返回的每种错误值类型定义不同的操作。
下面的例子演示了这个想法。我们首先尝试将一组任务添加(或注册)到队列中。如果这个“注册过程”顺利完成,我们就会尝试将这些任务分配给系统的各个工作线程。但是,如果这个“注册过程”返回错误值,我们就会在“else分支”中使用switch语句来处理每个可能的错误值。
if (add_tasks_to_queue(&queue, tasks)) |_| {
distribute_tasks(&queue);
} else |err| switch (err) {
error.InvalidTaskName => {
// do something
},
error.TimeoutTooBig => {
// do something
},
error.QueueNotFound => {
// do something
},
// and all the other error options ...
}
10.2.4关键字errdefer
C 程序中常见的一种模式是在程序执行过程中发生错误时清理资源。换句话说,处理错误的一种常见方法是在退出程序之前执行“清理操作”。这可以保证运行时错误不会导致程序泄漏系统资源。
关键字errdefer是在恶劣情况下执行此类“清理操作”的工具。此关键字通常用于在程序因生成错误值而停止执行之前清理(或释放)已分配的资源。
其基本思想是为关键字提供一个表达式errdefer。然后,errdefer当且仅当在当前作用域执行期间发生错误时,才执行此表达式。在下面的示例中,我们使用分配器对象(已在3.3 节中介绍过)来创建一个新User对象。如果我们成功创建并注册了这个新用户,则此create_user()函数将返回这个新User对象作为其返回值。
errdefer但是,如果由于某种原因,该行之后的某个表达式(例如,在表达式中)生成了错误值,则在函数返回错误值之前以及程序进入恐慌模式并停止当前执行之前,注册db.add(user)的表达式就会得到执行。errdefer
fn create_user(db: Database, allocator: Allocator) !User {
const user = try allocator.create(User);
errdefer allocator.destroy(user);
// Register new user in the Database.
_ = try db.register_user(user);
return user;
}
通过使用errdefer来销毁user刚刚创建的对象,我们可以保证user在程序停止执行之前释放为该对象分配的内存。因为如果表达式try db.add(user)返回错误值,程序就会停止执行,并且我们会失去所有引用以及对为该user对象分配的内存的控制。因此,如果我们user在程序停止之前没有释放与该对象关联的内存,那么我们就无法再释放这部分内存。我们只是失去了做正确事情的机会。这就是为什么errdefer在这种情况下 至关重要。
为了清楚地说明defer和之间的区别errdefer(我在2.1.3 节和2.1.4 节中描述过),可能值得进一步讨论一下。你可能仍然会问:“errdefer既然可以用defer,为什么还要用?”
尽管和 关键字相似,errdefer但它们之间的关键区别defer在于何时执行提供的表达式。defer关键字始终在当前作用域的末尾执行提供的表达式,无论代码如何退出此作用域。相反,errdefer仅当当前作用域中发生错误时才执行提供的表达式。
如果您在当前作用域中分配的资源稍后在代码中(在其他作用域中)被释放,这一点就变得非常重要。create_user()函数就是一个例子。如果您仔细思考这个函数,您会注意到它返回的是user对象作为结果。
换句话说,如果函数成功返回,则为该user对象分配的内存不会在create_user()函数内部释放。因此,如果此函数内部没有发生错误,则该user对象将从函数中返回,并且很可能由该create_user()函数之后运行的代码负责释放该user对象的内存。
但是如果函数内部发生错误怎么办create_user()?然后会发生什么?这意味着你的代码执行将在此create_user()函数中停止,因此,此create_user()函数之后运行的代码将无法运行,并且,user在程序停止之前,对象的内存将无法释放。
这是完美的场景errdefer。我们使用这个关键字来保证我们的程序将释放为对象分配的内存user,即使create_user()函数内部发生错误。
如果你在同一作用域内为某个对象分配并释放一些内存,那么你只需要使用即可defer,也就是说,errdefer在这种情况下,这些内存对你来说毫无用处。但是,如果你在作用域 A 中分配了一些内存,但之后才释放,例如在作用域 B 中,那么errdefer在特殊情况下,这些内存对于避免内存泄漏就非常有用。
10.3 Zig 中的联合类型
联合类型定义了对象可以属于的一组类型。它就像一个选项列表。每个选项都是对象可以采用的类型。因此,Zig 中的联合与 C 语言中的联合具有相同的含义,或者说,具有相同的作用。它们的用途相同。您也可以说,Zig 中的联合产生的效果与Python 1中的联合typing.Union类似。
例如,您可能正在创建一个 API,用于将数据发送到托管在某个私有云基础设施上的数据湖。假设您在代码库中创建了不同的结构体,用于存储所需的必要信息,以便连接到各个主流数据湖服务(Amazon S3、Azure Blob 等)。
现在,假设您还有一个名为 的函数send_event(),它接收一个事件作为输入,以及一个目标数据湖,并将输入事件发送到目标数据湖参数中指定的数据湖。但这个目标数据湖可以是三大主流数据湖服务(Amazon S3、Azure Blob 等)中的任何一个。这时,联合就可以帮助您了。
LakeTarget下面定义的联合允许 的lake_target参数为 类型、 类型或 类型send_event()的对象。此联合允许函数接收这三种类型中任意一种的对象作为参数的输入。AzureBlob``AmazonS3``GoogleGCP``send_event()``lake_target
请记住,这三种类型(AmazonS3、GoogleGCP和AzureBlob)都是我们在源代码中定义的独立结构体。因此,乍一看,它们在源代码中是独立的数据类型。但是, 是一个union关键字,将它们统一为一个名为 的数据类型LakeTarget。
const LakeTarget = union {
azure: AzureBlob,
amazon: AmazonS3,
google: GoogleGCP,
};
fn send_event(
event: Event,
lake_target: LakeTarget
) bool {
// body of the function ...
}
联合体定义由一系列数据成员组成。每个数据成员都属于一种特定的数据类型。在上面的例子中,LakeTarget联合体有三个数据成员(azure、amazon、google)。实例化一个使用联合体类型的对象时,在本次实例中只能使用其中一个数据成员。
您也可以将其理解为:联合类型中一次只能激活一个数据成员,其他数据成员保持停用状态且不可访问。例如,如果您创建了一个LakeTarget使用azure数据成员的对象,则您将无法再使用或访问数据成员google或amazon。这就像这些其他数据成员在该类型中根本不存在一样LakeTarget。
您可以在下面的示例中看到此逻辑。请注意,我们首先使用azure数据成员实例化联合对象。因此,此target对象仅包含azure其内部的数据成员。只有此数据成员在此对象中处于活动状态。这就是为什么此代码示例中的最后一行无效的原因。因为我们尝试实例化google当前对此target对象处于非活动状态的数据成员,因此程序进入恐慌模式,并通过响亮的错误消息警告我们此错误。
var target = LakeTarget {
.azure = AzureBlob.init()
};
// Only the `azure` data member exist inside
// the `target` object, and, as a result, this
// line below is invalid:
target.google = GoogleGCP.init();
thread 2177312 panic: access of union field 'google' while
field 'azure' is active:
target.google = GoogleGCP.init();
^
因此,实例化联合对象时,必须选择联合类型中列出的数据类型之一(或数据成员之一)。在上面的示例中,我选择使用azure数据成员,结果所有其他数据成员都自动停用,实例化对象后您将无法再使用它们。
您可以通过完全重新定义整个枚举对象来激活另一个数据成员。在下面的示例中,我最初使用了该azure数据成员。但随后,我重新定义了该target对象,以便使用一个LakeTarget使用该google数据成员的新对象。
var target = LakeTarget {
.azure = AzureBlob.init()
};
target = LakeTarget {
.google = GoogleGCP.init()
};
关于联合类型,有一个奇怪的事实:首先,你不能在 switch 语句中使用它们(这在2.1.2 节中介绍过)。换句话说,如果你有一个类型的对象LakeTarget,你不能将它作为 switch 语句的输入。
但是如果你真的需要这样做呢?如果你真的需要为 switch 语句提供一个“联合对象”怎么办?这个问题的答案依赖于 Zig 中的另一种特殊类型,即带_标签的联合_。要创建带标签的联合,你所要做的就是在联合声明中添加一个枚举类型。
作为 Zig 中带标签联合的示例,请参考Registry下面公开的类型。此类型来自Zig 存储库中的grammar.zig模块2。(enum)此联合类型列出了不同类型的注册表。但请注意,关键字后面使用了union。这就是使此联合类型成为带标签联合的原因。由于是带标签联合,因此此类型的对象Registry可以用作 switch 语句的输入。这就是您要做的全部。只需将其添加(enum)到union声明中,即可在 switch 语句中使用它。
pub const Registry = union(enum) {
core: CoreRegistry,
extension: ExtensionRegistry,
};
-
https://docs.python.org/3/library/typing.html#typing.Union ↩︎
-
https://github.com/ziglang/zig/blob/30b4a87db711c368853b3eff8e214ab681810ef9/tools/spirv/grammar.zig。↩︎
11 数据结构
在本章中,我想介绍 Zig 标准库中最常见的数据结构,尤其ArrayList是 和HashMap。这些是通用数据结构,可用于存储和控制应用程序生成的任何类型的数据。
11.1动态数组
在高级语言中,数组通常是动态的。它们的大小在必要时可以轻松增长,您无需为此担心。相比之下,低级语言中的数组通常默认是静态的。C、C++、Rust 以及 Zig 都是如此。静态数组在1.6 节中介绍过,但在本节中,我们将讨论 Zig 中的动态数组。
动态数组就是在程序运行时可以增长的数组。大多数低级语言在其标准库中都实现了动态数组。C++ 有std::vector,Rust 有Vec,Zig 也有std.ArrayList。
该std.ArrayList结构体为您提供了一个连续且可增长的数组。它像任何其他动态数组一样工作,它会分配一块连续的内存,当这块内存空间不足时,ArrayList它会分配另一个连续且更大的内存块,将元素复制到这个新位置,并擦除(或释放)前一块内存。
11.1.1容量与长度
当我们谈论动态数组时,我们通常会提到两个相似的概念,它们对于动态数组的底层工作原理至关重要。这两个概念是_容量_和_长度_。在某些情况下,尤其是在 C++ 中,长度_也称为_大小。
虽然它们看起来很相似,但在动态数组的上下文中,这些概念代表着不同的东西。_容量_是指动态数组当前可以容纳的项目(或元素)的数量,而无需分配更多内存。
相反,长度_指的是数组中当前正在使用的元素数量,或者换句话说,你已为该数组中分配了值的元素数量。每个动态数组都围绕一块已分配的内存运行,这块内存代表一个总容量为n元素。然而,只有其中一部分n元素大部分时间都在使用。这部分n是数组的_长度。因此,每次向数组添加新值时,其_长度_都会加1。
这意味着动态数组通常需要额外的空间,或者说是当前为空但等待使用的额外空间。这个“额外空间”本质上是_容量_和_长度_之间的差值。_容量_表示数组在无需重新分配或扩展的情况下可以容纳的元素总数,而_长度_表示当前有多少容量用于保存/存储值。
图 11.1直观地展示了这个想法。注意,一开始,数组的容量大于数组的长度。因此,动态数组虽然有额外的空间,但目前是空的,可以接收要存储的值。
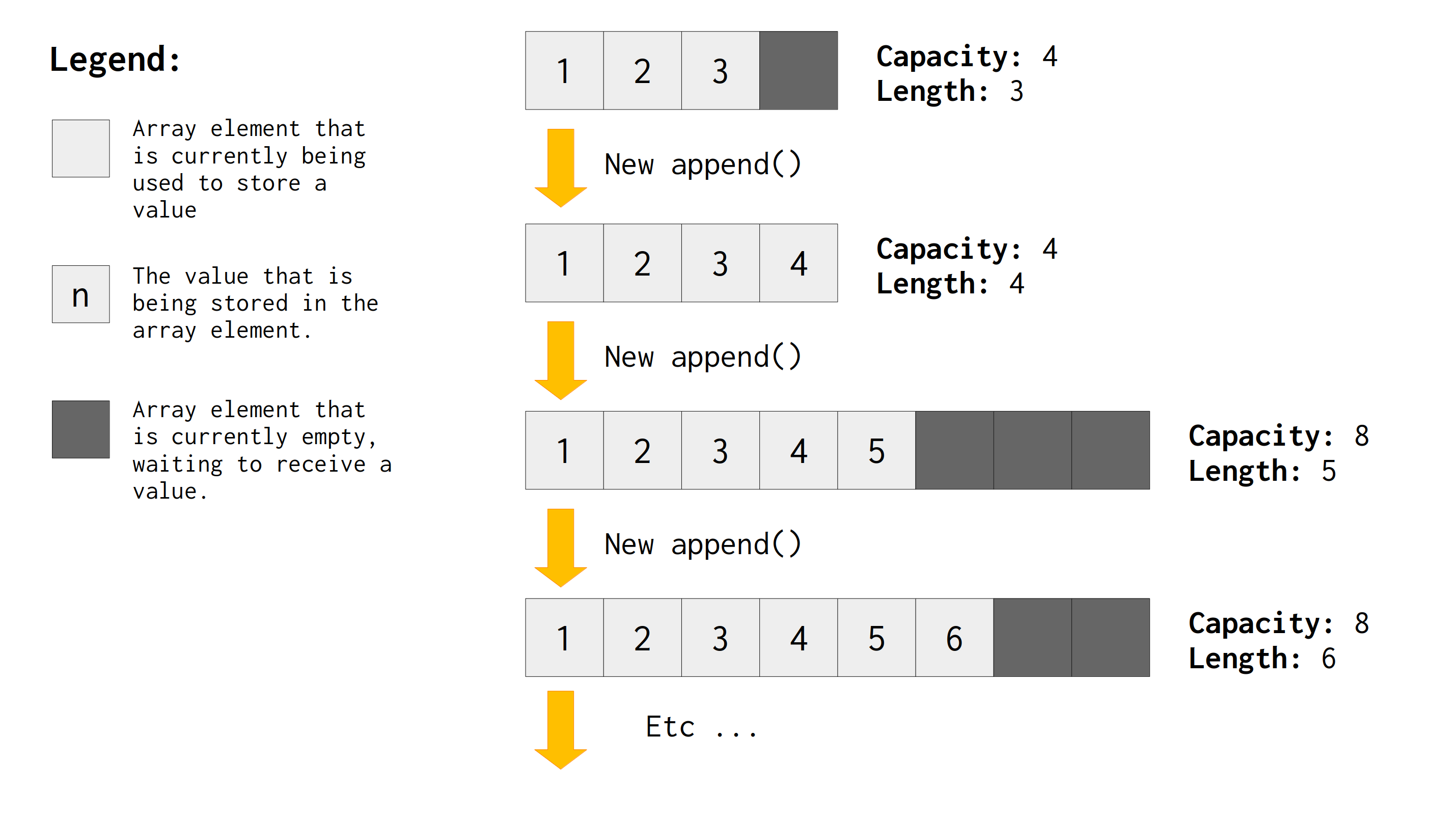
图 11.1:动态数组的容量和长度之间的差异
在图 11.1中我们还可以看到,当_长度_和_容量_相等时,意味着数组没有剩余空间。我们已经达到了容量上限,因此,如果我们想在这个数组中存储更多值,就需要扩展它。我们需要获得一个更大的空间,以容纳比当前更多的值。
动态数组的工作原理是,当长度_等于数组的_容量_时,扩展底层数组。它基本上会分配一个比前一个更大的新的连续内存块,然后将当前存储的所有值复制到这个新位置(即新的内存块),最后释放前一个内存块。在此过程结束时,新的底层数组具有更大的_容量,因此_长度_再次小于数组的_容量。_
这就是动态数组的循环。注意,在整个循环过程中,容量_始终等于或大于数组的_长度ArrayList。如果你有一个对象(假设你将其命名为),你可以通过访问该对象的属性buffer来检查数组的当前容量,同时该属性可以获取数组的当前_长度_。capacity``ArrayList``items.len
// Check capacity
buffer.capacity;
// Check length
buffer.items.len;
11.1.2创建ArrayList对象
要使用ArrayList,您必须为其提供一个分配器对象。请记住,Zig 没有默认的内存分配器。正如我在第 3.3 节中所述,所有内存分配都必须由您定义并可控制的分配器对象完成。在本例中,我将使用通用分配器,但您可以使用任何其他您喜欢的分配器。
初始化ArrayList对象时,必须提供数组元素的数据类型。换句话说,这定义了此数组(或容器)将存储的数据类型。因此,如果我指定了u8类型,那么我将创建一个动态u8值数组。但是,如果我提供一个自己定义的结构体,例如2.3 节User中的结构体,那么将创建一个动态值数组。在下面的示例中,我们使用表达式创建了一个动态值数组。User``ArrayList(u8)``u8
提供数组元素的数据类型后,您可以ArrayList使用init()或initCapacity()方法初始化对象。前一种方法仅接收分配器对象作为输入,而后一种方法同时接收分配器对象和容量数字作为输入。使用后一种方法,您不仅可以初始化结构体,还可以设置分配数组的起始容量。
使用此initCapacity()方法是初始化动态数组的首选方法。因为重新分配,或者换句话说,扩展数组容量的过程始终是一项高成本操作。您应该尽可能避免在数组中进行重新分配。如果您在开始时就知道数组需要占用多少空间,则应始终使用此方法initCapacity()来创建动态数组。
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var buffer = try std.ArrayList(u8)
.initCapacity(allocator, 100);
defer buffer.deinit();
在上面的例子中,buffer对象最初是一个包含 100 个元素的数组。如果此buffer对象在程序运行时需要创建更多空间来容纳更多元素,其ArrayList内部机制将自动执行必要的操作。另请注意,在当前作用域结束时,deinit()用于销毁对象的方法会释放为此对象中存储的动态数组分配的所有内存。buffer``buffer
11.1.3向数组添加新元素
现在我们已经创建了动态数组,可以开始使用它了。您可以使用append()方法向此数组附加(也称为“添加”)新值。此方法的工作方式append()与 Python 列表中的方法或C++emplace_back()中的方法相同std::vector。您向此方法提供一个值,该方法会将此值附加到数组中。
您还可以使用此appendSlice()方法一次附加多个值。您需要向此方法提供一个切片(切片已在1.6 节中描述),该方法会将此切片中存在的所有值添加到您的动态数组中。
try buffer.append('H');
try buffer.append('e');
try buffer.append('l');
try buffer.append('l');
try buffer.append('o');
try buffer.appendSlice(" World!");
11.1.4从数组中删除元素
你可以使用该pop()方法“弹出”或移除数组中的最后一个元素。值得注意的是,此方法不会改变数组的容量。它只是删除或擦除数组中存储的最后一个值。
此外,此方法还会返回被删除的值。也就是说,您可以使用此方法获取数组中的最后一个值,也可以将其从数组中删除。这是一种“获取并删除值”类型的方法。
const exclamation_mark = buffer.pop();
现在,如果您想从数组的特定位置删除特定元素,可以使用对象orderedRemove()中的方法ArrayList。使用此方法,您可以提供一个索引作为输入,然后该方法将删除数组中此索引处的值。每次执行操作时,您都可以有效地减少数组的_长度_orderedRemove()。
在下面的示例中,我们首先创建一个ArrayList对象,并用数字填充它。然后,我们orderedRemove()连续两次使用 删除数组中索引 3 处的值。
另外,请注意,我们将 的结果赋值orderedRemove()给了下划线字符。因此,我们丢弃了此方法的结果值。该orderedRemove()方法将以与 类似的方式返回被删除的值pop()。
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var buffer = try std.ArrayList(u8)
.initCapacity(allocator, 100);
defer buffer.deinit();
for (0..10) |i| {
const index: u8 = @intCast(i);
try buffer.append(index);
}
std.debug.print(
"{any}\n", .{buffer.items}
);
_ = buffer.orderedRemove(3);
_ = buffer.orderedRemove(3);
std.debug.print("{any}\n", .{buffer.items});
std.debug.print("{any}\n", .{buffer.items.len});
{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }
{ 0, 1, 2, 5, 6, 7, 8, 9 }
8
它的一个关键特性orderedRemove()是保留数组中值的顺序。因此,它会删除你要求移除的值,但同时确保数组中剩余值的顺序与之前保持一致。
现在,如果您不关心值的顺序,例如,您可能想将动态数组视为一组值,就像std::unordered_setC++ 中的结构体一样,swapRemove()那么您可以使用 方法。此方法的工作原理与 方法类似orderedRemove()。您为此方法指定一个索引,然后它会删除数组中位于此索引处的值。但此方法不会保留数组中剩余值的原始顺序。因此,swapRemove()通常比 更快orderedRemove()。
11.1.5在特定索引处插入元素
当您需要在数组中间插入值,而不是仅将它们附加到数组末尾时,您需要使用insert()和insertSlice()方法,而不是append()和appendSlice()方法。
这两个方法的工作原理与 C++ 类非常相似insert()。insert_range()你std::vector为这些方法提供一个索引,它们会将你提供的值插入到数组中该索引处。
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var buffer = try std.ArrayList(u8)
.initCapacity(allocator, 10);
defer buffer.deinit();
try buffer.appendSlice("My Pedro");
try buffer.insert(4, '3');
try buffer.insertSlice(2, " name");
for (buffer.items) |char| {
try stdout.print("{c}", .{char});
}
My name P3edro
11.1.6结论
如果您觉得缺少其他方法,我建议您阅读1结构的官方文档ArrayListAligned,其中描述了可通过对象使用的大多数方法。ArrayList
您会注意到此页面中还有许多其他方法我没有在这里描述,我建议您探索这些方法,并了解它们的工作原理。
11.2映射或哈希表
一些专业人士用不同的术语来理解这种数据结构,例如“map”、“hashmap”或“关联数组”。但最常用的术语是_哈希表 (hashtable)_。每种编程语言的标准库中通常都有哈希表的实现。Python 有dict(),C++ 有std::map和std::unordered_map,Rust 有HashMap,JavaScript 有Object()和Map(),等等。
11.2.1什么是哈希表?
哈希表是一种基于键值对的数据结构。你向该结构提供一个键和一个值,然后哈希表会将输入值存储在一个可以通过你提供的输入键识别的位置。它通过使用底层数组和哈希函数来实现这一点。这两个组件对于哈希表的工作原理至关重要。
哈希表的底层包含一个数组。这个数组用于存储值,其元素通常被称为_buckets_。因此,你提供给哈希表的值存储在 buckets 中,你可以通过索引访问每个 buckets。
当你为哈希表提供一个键时,它会将该键传递给哈希函数。哈希函数使用某种哈希算法将该键转换为索引。该索引实际上是一个数组索引,它是哈希表底层数组中的一个位置。这就是键在哈希表结构中标识特定位置(或地点)的方式。
因此,您需要向哈希表提供一个键,该键标识哈希表中的特定位置。然后,哈希表会获取您提供的输入值,并将该值存储在由该输入键标识的位置。您可以说,该键映射到哈希表中存储的值。您可以使用标识值存储位置的键来查找该值。图 11.2直观地展示了这个过程。

图 11.2:哈希表示意图。来源:维基百科,自由的百科全书。
上一段描述的操作通常称为_插入_操作,因为你正在将新值插入哈希表中。但是哈希表中还有其他类型的操作,例如_删除_和_查找_。删除操作是自描述的,它是指从哈希表中删除(或移除)一个值。而查找操作是指通过使用标识该值存储位置的键来查找存储在哈希表中的值。
有时,哈希表的底层数组不是直接存储值,而是指针数组,也就是说,数组的 buckets 存储指向值的指针,或者也可能是一个链表数组。这些情况在允许重复键的哈希表中很常见,或者换句话说,在能够有效处理哈希函数可能产生的“冲突”的哈希表中很常见。
重复键,或者我所说的“冲突”,是指两个不同的键指向哈希表底层数组中的同一位置(即同一索引)。这种情况的发生取决于哈希表中使用的哈希函数的特性。一些哈希表的实现会主动处理冲突,这意味着它们会以某种方式处理这种情况。例如,哈希表可能会将所有存储桶转换为链表。因为使用链表,您可以将多个值存储到一个存储桶中。
处理哈希表中的冲突有多种技术,本书不会详细介绍,因为这不是我们的主要讨论范围。不过,你可以在维基百科的哈希表页面(维基百科 2024)上找到一些最常见技术的详细描述。
11.2.2 Zig 中的哈希表
Zig 标准库提供了哈希表的不同实现。每种实现都有其优缺点,我们将在后面讨论,所有这些实现都可以通过该std.hash_map模块获得。
该HashMap结构体是一个通用的哈希表,它具有非常快的操作(查找、插入、删除),并且内存占用低,负载因子也很高。您可以创建一个上下文对象并将其提供给HashMap构造函数。此上下文对象允许您定制哈希表本身的行为,因为您可以通过此上下文对象提供哈希函数的实现供哈希表使用。
但现在我们先不用担心这个 context 对象,因为它是专门给“哈希表领域的专家”用的。既然我们很可能不是这个领域的专家,我们就用最简单的方法来创建哈希表。那就是使用AutoHashMap()函数。
此AutoHashMap()函数本质上是一个“使用默认设置创建哈希表对象”类型的函数。它会自动选择一个上下文对象,从而为您选择一个哈希函数实现。此函数接收两种数据类型作为输入:第一个输入是此哈希表将使用的键的数据类型,第二个输入是将存储在哈希表中的数据的数据类型,即要存储的值的数据类型。
在下面的示例中,我们u32在该函数的第一个参数和u16第二个参数中提供了数据类型。这意味着我们将使用u32值作为此哈希表中的键,而u16值是将要存储到此哈希表中的实际值。在此过程结束时,该hash_table对象包含一个HashMap使用默认设置和上下文的对象。
const std = @import("std");
const AutoHashMap = std.hash_map.AutoHashMap;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var hash_table = AutoHashMap(u32, u16).init(allocator);
defer hash_table.deinit();
try hash_table.put(54321, 89);
try hash_table.put(50050, 55);
try hash_table.put(57709, 41);
std.debug.print(
"N of values stored: {d}\n",
.{hash_table.count()}
);
std.debug.print(
"Value at key 50050: {d}\n",
.{hash_table.get(50050).?}
);
if (hash_table.remove(57709)) {
std.debug.print(
"Value at key 57709 successfully removed!\n",
.{}
);
}
std.debug.print(
"N of values stored: {d}\n",
.{hash_table.count()}
);
}
N of values stored: 3
Value at key 50050: 55
Value at key 57709 successfully removed!
N of values stored: 2
您可以使用该方法向哈希表中添加/放入新值put()。第一个参数是要使用的键,第二个参数是要存储在哈希表中的实际值。在下面的示例中,我们首先使用键 54321 添加值 89,然后使用键 50050 添加值 55,依此类推。
注意,我们之前使用了 方法count()来查看哈希表中当前存储了多少个值。之后,我们还使用get()方法来访问(或查看)键 500050 所标识位置处存储的值。该get()方法的输出是一个可选值。这就是为什么我们?在最后使用 方法来获取实际值。
还要注意,我们可以使用此方法从哈希表中移除(或删除)值remove()。你提供标识要删除的值的键,然后该方法将删除该值并返回一个true值作为输出。这个true值实际上告诉我们该方法已成功删除该值。
但是这个删除操作可能并不总是成功。例如,你可能为这个方法提供了错误的键。我的意思是,你可能(有意或无意地)提供了一个指向空存储桶(即存储桶中还没有值)的键。在这种情况下,该remove()方法会返回一个false值。
11.2.3遍历哈希表
遍历当前存储在哈希表中的键和值是非常常见的需求。在 Zig 中,您可以使用迭代器对象来实现这一点,该对象可以遍历哈希表对象的元素。
这个迭代器对象的工作方式与 C++ 和 Rust 等语言中的其他迭代器对象类似。它本质上是一个指向容器中某个值的指针对象,并且拥有一个next()可用于浏览(或迭代)容器中值的方法。
iterator()您可以使用哈希表对象的方法创建这样的迭代器对象。此方法返回一个迭代器对象,您可以将该next()方法与 while 循环结合使用,从而遍历哈希表的元素。该next()方法返回一个可选Entry值,因此,您必须解开此可选值的包装才能获取实际Entry值,从而可以访问键以及由该键标识的值。
有了这个值,你就可以通过使用该属性并取消引用其中的指针Entry来访问当前条目的键;而通过该属性访问由该键标识的值,该属性也是一个需要取消引用的指针。以下代码示例演示了这些元素的用法:key_ptr``value_ptr
const std = @import("std");
const AutoHashMap = std.hash_map.AutoHashMap;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var hash_table = AutoHashMap(u32, u16).init(allocator);
defer hash_table.deinit();
try hash_table.put(54321, 89);
try hash_table.put(50050, 55);
try hash_table.put(57709, 41);
var it = hash_table.iterator();
while (it.next()) |kv| {
// Access the current key
std.debug.print("Key: {d} | ", .{kv.key_ptr.*});
// Access the current value
std.debug.print("Value: {d}\n", .{kv.value_ptr.*});
}
}
Key: 54321 | Value: 89
Key: 50050 | Value: 55
Key: 57709 | Value: 41
如果你想要专门迭代哈希表的值或键,可以创建一个键迭代器或值迭代器对象。它们也是迭代器对象,并且拥有与next()迭代哈希表相同的方法。
键迭代器由哈希表对象的方法创建keyIterator(),而值迭代器则由该方法创建valueIterator()。您只需从next()方法中解包值,并直接引用它即可访问要迭代的键或值。以下代码示例演示了键迭代器的用法,但您可以将相同的逻辑复制到值迭代器中。
var kit = hash_table.keyIterator();
while (kit.next()) |key| {
std.debug.print("Key: {d}\n", .{key.*});
}
Key: 54321
Key: 50050
Key: 57709
11.2.4ArrayHashMap哈希表
如果您需要不断地遍历哈希表的元素,您可能需要ArrayHashMap针对您的具体情况使用结构体,而不是使用通常的通用HashMap结构体。
该ArrayHashMap结构体会创建一个迭代速度更快的哈希表。这就是为什么这种特定类型的哈希表可能对你很有价值。ArrayHashMap哈希表的其他一些属性包括:
- 插入顺序被保留,即,在遍历此哈希表时找到的值的顺序实际上是这些值插入哈希表的顺序。
- 键值对按顺序一个接一个地存储。
您可以使用一个辅助函数来创建ArrayHashMap对象,该函数会自动为您选择一个哈希函数实现。该函数的工作原理与我们在11.2.2 节AutoArrayHashMap()中介绍的函数非常相似。AutoHashMap()
你为这个函数提供了两种数据类型:一个是将用于哈希表的键的数据类型,另一个是将存储在哈希表中的值的数据类型。
对象ArrayHashMap本质上拥有与结构体完全相同的方法HashMap。因此,您可以使用该方法向哈希表中插入新值put(),也可以使用该方法从哈希表中查找(或获取)值get()。但是,该remove()方法在这种特定类型的哈希表中不可用。
要从哈希表中删除值,可以使用与对象ArrayList(即动态数组)中相同的方法。我在11.1.4 节中介绍了这些方法,即swapRemove()和orderedRemove()方法。这些方法在这里的含义相同,或者说,它们的作用与它们在对象中相同ArrayList。
这意味着,当swapRemove()你从哈希表中删除值时,你不会保留值插入到结构中的顺序。而orderedRemove()可以保留这些值的插入顺序。
但是,与我在11.1.4 节中描述的一样,这里的方法不是将索引作为swapRemove()或 的输入,而是像对象中的方法一样,将键作为输入。如果您想提供索引而不是键作为输入,则应该使用和方法。orderedRemove()ArrayHashMap``remove()``HashMap``swapRemoveAt()``orderedRemoveAt()
var hash_table = AutoArrayHashMap(u32, u16)
.init(allocator);
defer hash_table.deinit();
11.2.5StringHashMap哈希表
你会注意到,在上一节中我介绍的另外两种类型的哈希表中,它们的键都不接受切片数据类型。这意味着你不能在这些类型的哈希表中使用切片值来表示键。
最明显的后果是,你不能在这些哈希表中使用字符串作为键。但在哈希表中使用字符串作为键是非常常见的。
以这段非常简单的 Javascript 代码片段为例。我们创建一个名为 的简单哈希表对象people。然后,我们向此哈希表添加一个新条目,该条目由字符串 标识'Pedro'。在本例中,此字符串是键,而包含年龄、身高和城市等不同个人信息的对象是要存储在哈希表中的值。
var people = new Object();
people['Pedro'] = {
'age': 25,
'height': 1.67,
'city': 'Belo Horizonte'
};
这种使用字符串作为键的模式在各种情况下都很常见。因此,Zig 标准库为此提供了一种特定类型的哈希表,该哈希表是通过该StringHashMap()函数创建的。该函数创建一个使用字符串作为键的哈希表。该函数的唯一输入是将存储在此哈希表中的值的数据类型。
在下面的例子中,我创建了一个哈希表来存储不同人的年龄。哈希表中的每个键都由每个人的姓名表示,而哈希表中存储的值则是该键所标识的人的年龄。
这就是为什么我将u8数据类型(即年龄值所使用的数据类型)作为此StringHashMap()函数的输入。结果,它创建一个使用字符串值作为键并在其中存储值的哈希表。请注意,函数返回的对象的方法u8中提供了一个分配器对象。init()``StringHashMap()
const std = @import("std");
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var ages = std.StringHashMap(u8).init(allocator);
defer ages.deinit();
try ages.put("Pedro", 25);
try ages.put("Matheus", 21);
try ages.put("Abgail", 42);
var it = ages.iterator();
while (it.next()) |kv| {
std.debug.print("Key: {s} | ", .{kv.key_ptr.*});
std.debug.print("Age: {d}\n", .{kv.value_ptr.*});
}
}
Key: Pedro | Age: 25
Key: Abgail | Age: 42
Key: Matheus | Age: 21
11.2.6StringArrayHashMap哈希表
StringHashMapZig 标准库还提供了一种哈希表,它兼具了和的优缺点ArrayHashMap。也就是说,它既使用字符串作为键,又兼具 的优点ArrayHashMap。换句话说,你可以拥有一个哈希表,它可以快速迭代,保留插入顺序,并且使用字符串作为键。
你可以使用函数创建此类哈希表StringArrayHashMap()。该函数接受一个数据类型作为输入,该数据类型是将要存储在此哈希表中的值的数据类型,其样式与11.2.5 节中介绍的函数相同。
您可以使用我们在11.2.5 节put()中讨论过的相同方法向此哈希表中插入新值。您也可以使用相同的方法从哈希表中获取值。与其兄弟类似,要从这种特定类型的哈希表中删除值,我们也可以使用和方法,其效果与我在11.2.4 节中描述的相同。get()``ArrayHashMap``orderedRemove()``swapRemove()
如果我们采用第 11.2.5 节中展示的代码示例,我们可以用以下命令实现完全相同的结果StringArrayHashMap():
var ages = std.StringArrayHashMap(u8).init(allocator);
11.3链表
Zig 标准库提供了单链表和双链表的实现。链表是一种线性数据结构,看起来像一条链,或者一根绳子。这种数据结构的主要优点是插入和删除操作通常非常快。但是,缺点是,迭代这种数据结构通常不如迭代数组快。
链表的理念是构建一个由一系列通过指针相互连接的节点组成的结构。这意味着链表在内存中通常不是连续的,因为每个节点可能位于内存中的任何位置。它们不需要彼此靠近。
在图 11.3中,我们可以看到一个单链表的示意图。我们从第一个节点(通常称为“链表的头”)开始。然后,从这个第一个节点开始,沿着每个节点的指针指向的位置,找到结构中的其余节点。
每个节点包含两个内容:一个是存储在当前节点的值,另一个是指向链表下一个节点的指针。如果该指针为空,则表示我们已到达链表的末尾。
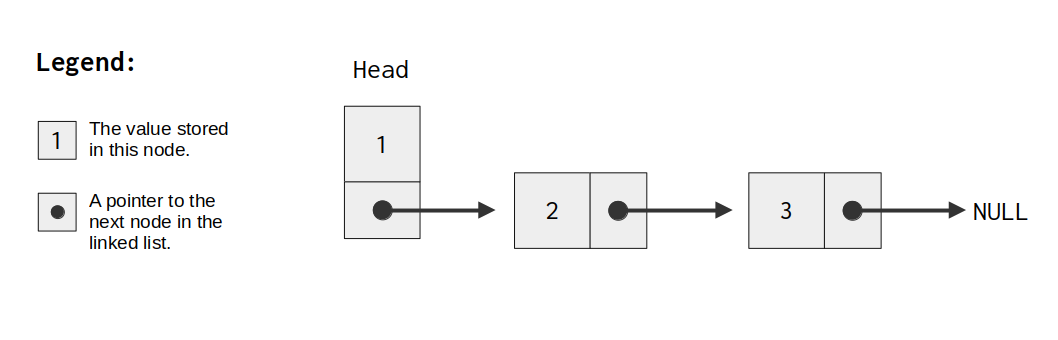
图 11.3:单链表的图表。
在图 11.4中,我们可以看到一个双向链表的示意图。现在唯一真正改变的是,链表中的每个节点都有一个指向前一个节点的指针和一个指向下一个节点的指针。因此,双向链表中的每个节点都有两个指针。它们通常被称为节点的prev(表示“上一个”)指针和(表示“下一个”)指针。next
在单链表的例子中,每个节点只有一个指针,并且这个指针始终指向序列中的下一个节点。这意味着单链表通常只有一个next指针。
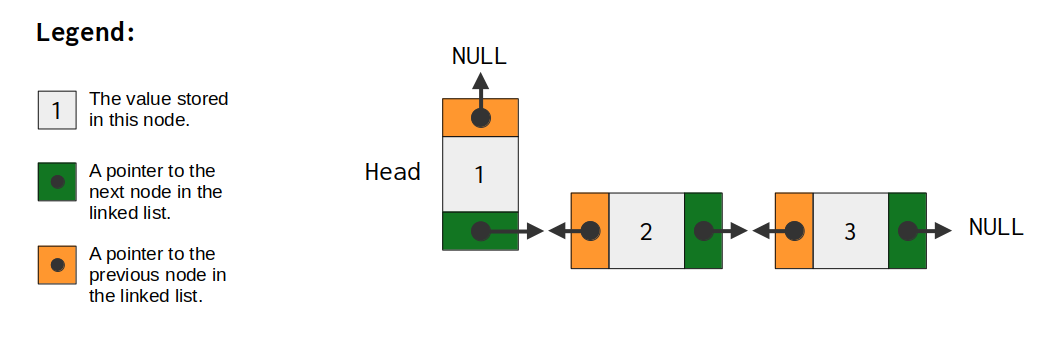
图 11.4:双向链表的图表。
在 Zig 中,链表可通过函数SinglyLinkedList()和使用,分别表示“单链表”和“双链表”。这些函数实际上是通用函数,我们将在12.2.1 节DoublyLinkedList()中详细讨论。
现在,只需理解,为了创建链表对象,我们首先要为这些函数提供一个数据类型。该数据类型定义了链表中每个节点将存储的数据类型。在下面的示例中,我们将创建一个单链表u32。因此,链表中的每个节点都将存储一个u32值。
SinglyLinkedList()和函数都DoublyLinkedList()返回一个类型,即一个结构体定义。因此,该对象Lu32实际上是一个结构体定义。它定义了“单链表”类型u32。
现在我们有了结构体的定义,我们需要实例化一个Lu32对象。在 Zig 中,我们通常使用init()方法实例化结构体对象。但在本例中,我们直接struct在表达式中使用空字面量来实例化结构体Lu32{}。
prepend()在这个例子中,我们首先创建多个节点对象,创建完成后,我们使用和方法插入并连接这些节点来构建链表insertAfter()。注意,prepend()方法是链表对象中的方法,而insertAfter()是节点对象中的方法。
本质上,该prepend()方法会在链表的开头插入一个节点。换句话说,你提供给此方法的节点将成为链表的新“头节点”。它将成为链表的第一个节点(参见图 11.3)。
另一方面,该insertAfter()方法主要用于将两个节点连接在一起。当你向此方法传入一个节点时,它会创建一个指向该输入节点的指针,并将该指针存储在next调用该方法的当前节点的属性中。
因为双向链表的每个节点都有 anext和 a属性(如图 11.4prev所示),所以从对象创建的节点对象同时具有 an (for ) 和 an (for ) 方法可用。DoublyLinkedList``insertBefore()``prev``insertAfter()``next
因此,如果我们使用了双向链表,我们可以用该insertBefore()方法将指向输入节点的指针存储在prev属性中。这会将输入节点设置为“上一个节点”,即当前节点之前的节点。相反,该insertAfter()方法将指向输入节点的指针存储在next当前节点的属性中,结果,输入节点成为当前节点的“下一个节点”。
由于我们在此示例中使用单链表,因此我们只能insertAfter()在从我们的类型创建的节点对象中使用该方法Lu32。
const std = @import("std");
const SinglyLinkedList = std.SinglyLinkedList;
const Lu32 = SinglyLinkedList(u32);
pub fn main() !void {
var list = Lu32{};
var one = Lu32.Node{ .data = 1 };
var two = Lu32.Node{ .data = 2 };
var three = Lu32.Node{ .data = 3 };
var four = Lu32.Node{ .data = 4 };
var five = Lu32.Node{ .data = 5 };
list.prepend(&two); // {2}
two.insertAfter(&five); // {2, 5}
list.prepend(&one); // {1, 2, 5}
two.insertAfter(&three); // {1, 2, 3, 5}
three.insertAfter(&four); // {1, 2, 3, 4, 5}
}
链表对象还提供了其他方法,具体取决于该对象是单链表还是双链表,这些方法可能对您非常有用。您可以在以下要点中找到这些方法的摘要:
remove()从链接列表中删除特定节点。- 如果是单链表,
len()则计算链表中有多少个节点。 - 如果是双向链表,检查
len属性以查看链表中有多少个节点。 - 如果是单链表,
popFirst()则从链表中删除第一个节点(即“头”)。 - 如果是双向链表,
pop()则popFirst()分别从链表中删除最后一个节点和第一个节点。 - 如果是双向链表,
append()则将新节点添加到链表的末尾(即的逆prepend())。
11.4多数组结构
Zig 引入了一种名为 的新数据结构。它是我们在第 11.1 节MultiArrayList()中介绍的动态数组的不同版本。此结构与我们从第 11.1 节中了解的的区别在于,它会为您作为输入提供的结构体的每个字段创建一个单独的动态数组。ArrayList()MultiArrayList()
请考虑以下代码示例。我们创建一个名为 的新自定义结构体Person。此结构体包含三个不同的数据成员,或者说三个不同的字段。因此,当我们将此Person数据类型作为 的输入时MultiArrayList(),这将创建一个名为 的“包含三个不同数组的结构体” PersonArray。换句话说,这PersonArray是一个包含三个内部动态数组的结构体。结构体定义中的每个字段对应一个数组Person。
const std = @import("std");
const Person = struct {
name: []const u8,
age: u8,
height: f32,
};
const PersonArray = std.MultiArrayList(Person);
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var people = PersonArray{};
defer people.deinit(allocator);
try people.append(allocator, .{
.name = "Auguste", .age = 15, .height = 1.54
});
try people.append(allocator, .{
.name = "Elena", .age = 26, .height = 1.65
});
try people.append(allocator, .{
.name = "Michael", .age = 64, .height = 1.87
});
}
换句话说,该MultiArrayList()函数不是创建一个“persons”数组,而是创建一个“数组结构体”。该结构体的每个数据成员都是一个不同的数组,用于存储特定字段的值,这些Person值来自被添加(或追加)到这个“数组结构体”的值。一个重要的细节是,每个存储在内部的独立数组PersonArray都是动态数组。这意味着这些数组可以根据需要自动增加容量,以容纳更多值。
下面的图 11.5展示了我们在上一个代码示例中创建的结构体的示意图。请注意,我们添加到对象的PersonArray三个值中,其数据成员的值分散在对象的三个不同的内部数组中。Person``PersonArray``PersonArray

图 11.5:结构图PersonArray。
您可以轻松地分别访问每个数组,并迭代每个数组的值。为此,您需要items()从PersonArray对象中调用该方法,并将要迭代的字段名称作为此方法的输入。.age例如,如果您要迭代数组,则需要items(.age)从PersonArray对象中调用,如下例所示:
for (people.items(.age)) |*age| {
try stdout.print("Age: {d}\n", .{age.*});
}
Age: 15
Age: 26
Age: 64
在上面的例子中,我们正在迭代数组的值,或者,迭代包含从添加到多数组结构的值的数据成员的值的对象.age的内部数组。PersonArray``age``Person
items()在此示例中,我们直接从对象调用该方法PersonArray。但是,大多数情况下,建议items()从“切片对象”调用此方法,该对象可以通过该slice()方法创建。这样做的原因是,items()使用切片对象可以提高多次调用的性能。
因此,如果您打算只访问“多数组结构体”中的一个内部数组,那么items()直接从多数组对象调用即可。但是,如果您需要访问“多数组结构体”中的多个内部数组,则可能需要items()多次调用,在这种情况下,最好items()通过切片对象调用。以下示例演示了此类对象的用法:
var slice = people.slice();
for (slice.items(.age)) |*age| {
age.* += 10;
}
for (slice.items(.name), slice.items(.age)) |*n,*a| {
try stdout.print(
"Name: {s}, Age: {d}\n", .{n.*, a.*}
);
}
Name: Auguste, Age: 25
Name: Elena, Age: 36
Name: Michael, Age: 74
11.5结论
还有许多其他数据结构我没有在这里介绍。但您可以在官方 Zig 标准库文档页面上查看它们。实际上,当您进入文档2的主页时,此页面中首先呈现给您的是 Zig 标准库中可用的类型和数据结构的列表。此列表中有一些非常具体的数据结构,例如BoundedArraystruct 3,但也有一些更通用的结构,例如PriorityQueuestruct 4。
-
https://ziglang.org/documentation/master/std/#std.array_list.ArrayListAligned ↩︎
-
https://ziglang.org/documentation/master/std/#std.bounded_array.BoundedArray ↩︎
-
https://ziglang.org/documentation/master/std/#std.priority_queue.PriorityQueue。↩︎
12 项目 3 - 构建堆栈数据结构
在本章中,我们将实现一个堆栈数据结构,作为本书的下一个小项目。用任何语言实现基本数据结构在计算机科学(CS)中都属于“幼儿园任务”(如果这个术语存在的话),因为我们通常在CS的第一个学期学习和实现它们。
但这实际上很好!因为这应该是一个非常简单的任务,我们不需要太多解释什么是堆栈,然后,我们可以专注于真正重要的事情,即学习如何在 Zig 语言中实现“泛型”的概念,以及 Zig 的一个关键特性,即计算时间,是如何工作的,并使用堆栈数据结构来动态演示这些概念。
但在开始构建堆栈数据结构之前,我们首先需要了解comptime关键字对代码的作用,之后,我们还需要了解泛型在 Zig 中的工作原理。
12.1comptime Zig 中的理解
Zig 的一个关键特性是comptime。这个关键字引入了一个全新的概念和范式,它与编译过程紧密相关。在第 3.1.1 节中,我们描述了“编译时与运行时”在 Zig 中的重要性和作用。在那一节中,我们了解到,应用于值/对象的规则会根据该值是在编译时已知还是仅在运行时已知而发生很大变化。
关键字comptime与这两个时间空间(编译时和运行时)密切相关。让我们快速回顾一下它们之间的区别。编译时是指zig编译器编译 Zig 源代码的时间段,而运行时是指执行 Zig 程序的时间段,即我们执行编译器生成的二进制文件的时间zig。
有三种方法可以应用comptime关键字,分别是:
- 应用于
comptime函数参数。 - 应用于
comptime物体。 - 应用于
comptime一组表达式。
12.1.1应用函数参数
comptime当你在函数参数上应用该关键字时,你是在告诉zig编译器,赋给该特定函数参数的值必须在编译时已知。我们在3.1.1 节详细解释了“编译时已知的值”的具体含义。所以,如果你对此有任何疑问,请参考该节。
现在让我们思考一下这个想法的后果。首先,我们对特定的函数参数施加了一个限制,或者说一个要求。如果程序员不小心尝试给这个函数参数赋一个编译时未知的值,编译器zig会注意到这个问题,并因此引发编译错误,提示无法编译你的程序。因为你给一个必须“编译时已知”的函数参数提供了一个“运行时已知”的值。
请看下面这个非常简单的例子,我们定义了一个twice()名为 的函数,它只是将输入值加倍num。注意,我们comptime在函数参数名称前使用了 关键字。这个关键字将函数参数标记num为“comptime 参数”。
这是一个函数参数,其值必须是编译时已知的。这就是为什么表达式twice(5678)是有效的,并且不会引发编译错误。因为该值5678是编译时已知的,所以这是该函数的预期行为。
fn twice(comptime num: u32) u32 {
return num * 2;
}
test "test comptime" {
_ = twice(5678);
}
1/1 filef044375a1f16.test.test comptime...OKAll 1
tests passed.
但是,如果我们提供一个函数在编译时不知道的数字,该怎么办?例如,你的程序可能会通过stdin系统通道接收来自用户的输入。来自用户的输入可能有很多种,并且在编译时无法预测。这些情况使得这个“来自用户的输入”成为一个只有运行时才知道的值。
在下面的例子中,这个“来自用户的输入”最初以字符串的形式接收,然后被解析并转换为整数值,并且此操作的结果存储在n对象内部。
由于“用户的输入”仅在运行时才可知,因此对象的值n也仅在运行时确定。因此,我们无法将此对象作为twice()函数的输入。zig编译器不允许这样做,因为我们将num参数标记为“comptime 参数”。因此,zig编译器会引发如下所示的编译时错误:
const std = @import("std");
fn twice(comptime num: u32) u32 {
return num * 2;
}
pub fn main() !void {
var buffer: [5]u8 = .{ 0, 0, 0, 0, 0 };
const stdout = std.io.getStdOut().writer();
const stdin = std.io.getStdIn().reader();
_ = try stdout.write("Please write a 4-digit integer number\n");
_ = try stdin.readUntilDelimiter(&buffer, '\n');
try stdout.print("Input: {s}", .{buffer});
const n: u32 = try std.fmt.parseInt(
u32, buffer[0 .. buffer.len - 1], 10
);
const twice_result = twice(n);
try stdout.print("Result: {d}\n", .{twice_result});
}
t.zig:12:16: error: unable to resolve comptime value
const twice_result = twice(n);
^
Comptime 参数经常用于返回某种泛型结构的函数。事实上,这是在 Zig 中创建泛型的本质(或基础)。我们将在第 12.2 节comptime中详细讨论泛型。
现在,让我们看一下Seguin ( 2024 )中的这段代码示例。您可以看到,此IntArray()函数有一个名为 的参数length。此参数标记为 comptime,并接收一个 类型的值usize作为输入。因此,赋予此参数的值必须是编译时已知的。我们还可以看到,此函数返回一个i64值数组作为输出。
fn IntArray(comptime length: usize) type {
return [length]i64;
}
现在,这个函数的关键部分是length参数。这个参数用于确定函数生成的数组的大小。让我们思考一下这样做的后果。如果数组的大小取决于赋给length参数的值,这意味着函数输出的数据类型取决于这个参数的值length。
仔细思考一下这句话。正如我在1.2.2 节中所述,Zig 是一种强类型语言,尤其是在函数声明方面。因此,每次用 Zig 编写函数时,我们都必须注释函数返回值的数据类型。但是,如果这种数据类型取决于赋予函数参数的值,我们该怎么做呢?
想一想。length例如,如果 等于 3,那么函数的返回类型就是[3]i64。但如果length等于 40,那么返回类型就变成了[40]i64。这时zig编译器就会感到困惑,并引发编译错误,如下所示:
嘿!你注释了这个函数应该返回一个
[3]i64值,但我得到的[40]i64却是一个值!这看起来不对劲!
那么该如何解决这个问题呢?我们该如何克服这个障碍呢?这时type关键字就派上用场了。这个type关键字的作用是告诉编译器,这个函数将返回某种数据类型,但它还不知道具体是什么数据类型。我们将在12.2 节zig中详细讨论这个问题。
12.1.2应用表达式
当你在表达式上应用该comptime关键字时,编译器保证会zig在编译时执行此表达式。如果由于某种原因,此表达式无法在编译时执行(例如,此表达式可能依赖于一个只有在运行时才知道的值),那么zig编译器将引发编译错误。
以 Zig 官方文档(Zig Software Foundation 2024)中的这个例子为例。我们fibonacci()在运行时和编译时都执行同一个函数。该函数默认在运行时执行,但由于我们comptime在第二个“try 表达式”中使用了关键字,因此该表达式在编译时执行。
这可能会让一些人感到困惑。没错!当我说这个表达式在编译时执行时,我的意思是这个表达式是在zig编译器编译 Zig 源代码时编译并执行的。
const expect = @import("std").testing.expect;
fn fibonacci(index: u32) u32 {
if (index < 2) return index;
return fibonacci(index - 1) + fibonacci(index - 2);
}
test "fibonacci" {
// test fibonacci at run-time
try expect(fibonacci(7) == 13);
// test fibonacci at compile-time
try comptime expect(fibonacci(7) == 13);
}
1/1 filef0447cb16f4d.test.fibonacci...OKAll 1 test
ts passed.
很多 Zig 源代码可能会在编译时执行,因为编译器可以计算出某些表达式的输出。尤其是当这些表达式仅依赖于编译时已知值时。我们在第 3.1.1 节zig中讨论过这个问题。
comptime但是当你在表达式上使用关键字时,就不再有“它可能在编译时执行”的说法了。使用comptime关键字,你命令zig编译器在编译时执行这个表达式。你强加了这条规则,保证了编译器总是会在编译时执行它。或者,至少,编译器会尝试执行它。如果编译器因为任何原因无法执行该表达式,编译器将引发编译错误。
12.1.3应用到块上
块在1.7 节中进行了描述。将comptime关键字应用于表达式块时,其效果与将此关键字应用于单个表达式基本相同。也就是说,编译器会在编译时执行整个表达式块zig。
在下面的例子中,我们将标有的块标记blk为 comptime 块,因此,该块内的表达式在编译时执行。
const expect = @import("std").testing.expect;
fn fibonacci(index: u32) u32 {
if (index < 2) return index;
return fibonacci(index - 1) + fibonacci(index - 2);
}
test "fibonacci in a block" {
const x = comptime blk: {
const n1 = 5;
const n2 = 2;
const n3 = n1 + n2;
try expect(fibonacci(n3) == 13);
break :blk n3;
};
_ = x;
}
1/1 filef044524d5e27.test.fibonacci in a block...O
OKAll 1 tests passed.
12.2泛型介绍
首先,什么是泛型?泛型的理念是允许一个类型(f64以及u8用户自定义类型,例如我们在2.3 节中定义的结构体)作为方法、类和接口(Geeks for Geeks 2024)u32的参数。换句话说,“泛型”是一个可以处理多种数据类型的类(或方法)。bool``User
例如,在 Java 中,泛型是通过运算符 创建的<>。使用此运算符,Java 类能够接收某种数据类型作为输入,因此该类可以根据此输入数据类型调整其功能。再例如,C++ 中的泛型是通过模板的概念来支持的。C++ 中的类模板就是泛型。
在 Zig 中,泛型是通过 实现的comptime。该comptime关键字允许我们在编译时收集数据类型,并将该数据类型作为输入传递给一段代码。
12.2.1泛型函数
以max()下面展示的函数作为第一个例子。这个函数本质上是一个“泛型函数”。在这个函数中,我们有一个名为 的 comptime 函数参数T。注意,这个T参数的数据类型是type。很奇怪吧?这个type关键字在 Zig 中是“所有类型之父”,或者说是“类型的类型”。
因为我们在参数中使用了 thistype关键字T,所以我们告诉zig编译器此T参数将接收某种数据类型作为输入。还要注意comptime此参数中关键字的用法。正如我在12.1 节中所述,每次在函数参数中使用 this 关键字时,都意味着此参数的值必须在编译时已知。这很合理,对吧?因为没有哪种数据类型在编译时是未知的。
想想看。你编写的任何数据类型在编译时都是已知的。尤其因为数据类型是编译器实际编译源代码的必要信息。考虑到这一点,将此参数标记为 comptime 参数是有意义的。
fn max(comptime T: type, a: T, b: T) T {
return if (a > b) a else b;
}
还要注意,参数的值T实际上用于定义函数中其他参数的数据类型,a以及b,以及函数的返回类型注释。也就是说,这些参数的数据类型(a和b),以及函数本身的返回数据类型,由赋予参数的输入值决定T。
因此,我们有一个可以处理不同数据类型的泛型函数。例如,我可以u8为该max()函数提供值,它会按预期工作。但如果我提供f64值,它也会按预期工作。如果没有泛型函数,我将不得不max()为每种想要使用的数据类型编写不同的函数。这个泛型函数为我们提供了一个非常有用的快捷方式。
const std = @import("std");
fn max(comptime T: type, a: T, b: T) T {
return if (a > b) a else b;
}
test "test max" {
const n1 = max(u8, 4, 10);
std.debug.print("Max n1: {d}\n", .{n1});
const n2 = max(f64, 89.24, 64.001);
std.debug.print("Max n2: {d}\n", .{n2});
}
Max n1: 10
Max n2: 89.24
12.2.2通用数据结构
Zig 标准库中所有数据结构(例如 ArrayList、HashMap等)本质上都是通用数据结构。这些数据结构之所以通用,是因为它们可以处理任何你想要的数据类型。你只需指定要存储在这个数据结构中的值的数据类型,它们就能按预期工作。
Zig 中的通用数据结构是如何从 Java 复制通用类,或从 C++ 复制类模板的。但你可能会问自己:如何在 Zig 中构建通用数据结构?
其基本思想是编写一个泛型函数,用于创建我们想要的特定类型的数据结构定义。换句话说,这个泛型函数就像一个“数据结构工厂”。泛型函数输出struct为特定数据类型定义该数据结构的定义。
要创建这样的函数,我们需要为该函数添加一个 comptime 参数,该参数接收一个数据类型作为输入。我们已经在上一节(12.2.1 节)学习了如何实现这一点。我认为演示如何创建通用数据结构的最佳方法是实际编写一个。本书的下一个小项目就在这里。这是一个非常小的项目,旨在编写一个通用堆栈数据结构。
12.3什么是堆栈?
堆栈数据结构是一种遵循 LIFO(后进先出)原则的结构。堆栈数据结构通常仅支持两种操作: 和push。pop操作push用于向堆栈中添加新值,而pop操作用于从堆栈中删除值。
当人们尝试解释堆栈数据结构的工作原理时,他们最常用的类比是一叠盘子。想象一下,你有一叠盘子,例如,你的桌子上有 10 个盘子。每个盘子代表当前存储在此堆栈中的一个值。
我们从一叠包含 10 个不同值(或 10 个不同的盘子)的堆栈开始。现在,假设你想向这个堆栈中添加一个新盘子(或一个新的值),这相当于一个push操作。你只需将新盘子放在堆栈顶部即可添加这个盘子(或这个值)。然后,堆栈中的盘子数量将增加到 11 个。
但是,如何从这个堆栈中移除盘子(或移除其中的物品)(也就是pop操作)呢?要做到这一点,我们必须移除堆栈顶部的盘子,这样,堆栈中又会有 10 个盘子。
这演示了后进先出(LIFO)的概念,因为栈中的第一个盘子,也就是栈底的盘子,总是最后一个被取出。想想看,为了从栈中取出这个特定的盘子,我们必须取出栈中的所有盘子。因此,栈中的每个操作,无论是插入还是删除,总是在栈顶进行。下图 12.1直观地展示了这一逻辑:

图 12.1:堆栈结构图。来源:维基百科,自由的百科全书。
12.4编写堆栈数据结构
我们将分两步编写堆栈数据结构。首先,我们将实现一个只能存储u32值的堆栈。然后,我们将扩展我们的实现,使其具有通用性,以便它能够处理我们想要的任何数据类型。
首先,我们需要确定如何在栈中存储值。栈结构背后的存储机制有多种实现方式。有些人喜欢使用双向链表,有些人喜欢使用动态数组等等。在本例中,我们将使用一个数组来存储栈中的值,也就是items我们结构体定义的数据成员Stack。
还要注意Stack,我们的结构体中还有另外三个数据成员:capacity、length和allocator。capacity成员包含存储堆栈中值的底层数组的容量。length包含当前存储在堆栈中的值的数量。allocator包含分配器对象,每当堆栈结构需要为正在存储的值分配更多空间时,它将使用该对象。
我们首先定义init()该结构体的一个方法,该方法负责实例化一个Stack对象。注意,在这个init()方法内部,我们首先根据参数指定的容量分配一个数组capacity。
const std = @import("std");
const Allocator = std.mem.Allocator;
const Stack = struct {
items: []u32,
capacity: usize,
length: usize,
allocator: Allocator,
pub fn init(allocator: Allocator, capacity: usize) !Stack {
var buf = try allocator.alloc(u32, capacity);
return .{
.items = buf[0..],
.capacity = capacity,
.length = 0,
.allocator = allocator,
};
}
};
12.4.1实施push操作
现在我们已经编写了创建新对象的基本逻辑Stack,接下来可以开始编写执行推送操作的逻辑了。记住,在堆栈数据结构中,推送操作是将新值添加到堆栈的操作。
那么,我们如何向Stack已有的对象添加新值呢?push()下面给出的函数可能是这个问题的答案。还记得我们在12.3 节中讨论过的内容吗?值总是被添加到栈顶。这意味着该push()函数必须始终在底层数组中找到当前表示栈顶位置的元素,然后将输入值添加到那里。
首先,这个函数中有一个 if 语句。这个 if 语句检查是否需要扩展底层数组来存储添加到堆栈的新值。换句话说,底层数组可能没有足够的容量来存储这个新值,在这种情况下,我们需要扩展数组以获得所需的容量。
因此,如果此 if 语句中的逻辑测试返回 true,则表示数组容量不足,我们需要先扩展它,然后再存储新值。因此,在此 if 语句中,我们执行必要的表达式来扩展底层数组。请注意,我们使用分配器对象分配了一个比当前数组大两倍的新数组(self.capacity * 2)。
之后,我们使用另一个名为 的内置函数@memcpy()。此内置函数相当于memcpy()C 标准库1中的函数。它用于将值从一个内存块复制到另一个内存块。换句话说,你可以使用此函数将值从一个数组复制到另一个数组。
我们使用这个@memcpy()内置函数将当前存储在堆栈对象底层数组 ( self.items) 中的值复制到我们分配的新的更大的数组 ( new_buf) 中。执行此函数后,new_buf包含当前 处的值的副本self.items。
现在我们已经在对象中获得了当前值的副本new_buf,现在可以释放当前分配在 处的内存了self.items。之后,我们只需要将新的更大的数组赋值给self.items。这是扩展数组所需的步骤序列。
pub fn push(self: *Stack, val: u32) !void {
if ((self.length + 1) > self.capacity) {
var new_buf = try self.allocator.alloc(
u32, self.capacity * 2
);
@memcpy(
new_buf[0..self.capacity], self.items
);
self.allocator.free(self.items);
self.items = new_buf;
self.capacity = self.capacity * 2;
}
self.items[self.length] = val;
self.length += 1;
}
在确保有足够的空间存储要添加到堆栈的新值之后,我们要做的就是将该值赋给堆栈的顶部元素,并将length属性的值加一。我们使用该length属性找到堆栈中的顶部元素。
12.4.2实施pop操作
现在我们可以实现栈对象的弹出操作了。这是一个更容易实现的操作,pop()下面的方法总结了所需的所有逻辑。
我们只需要在底层数组中找到当前代表栈顶的元素,并将该元素设置为“undefined”,以指示该元素为“空”。之后,我们还需要将length栈的属性减一。
如果堆栈的当前长度为零,则表示堆栈中当前没有存储任何值。因此,在这种情况下,我们可以直接返回,什么也不做。这就是此函数中的 if 语句所检查的内容。
pub fn pop(self: *Stack) void {
if (self.length == 0) return;
self.items[self.length - 1] = undefined;
self.length -= 1;
}
12.4.3实现deinit方法
我们实现了负责与堆栈数据结构相关的两个主要操作的方法,即pop()和push(),我们还实现了负责实例化新Stack对象的方法,即init()方法。
但现在,我们还需要实现负责销毁对象的方法Stack。在 Zig 中,此任务通常与名为 的方法相关联deinit()。Zig 中的大多数结构体对象都具有此类方法,它通常被称为“析构函数方法”。
理论上,要销毁Stack对象,我们只需确保使用存储在Stack对象内部的分配器对象释放为底层数组分配的内存。下面的方法就是这样deinit()做的。
pub fn deinit(self: *Stack) void {
self.allocator.free(self.items);
}
12.5使其通用
现在我们已经实现了堆栈数据结构的基本框架,接下来可以集中讨论如何使其具有泛型。如何使这个基本框架不仅能处理u32值,还能处理我们想要的任何其他数据类型?例如,我们可能需要创建一个堆栈对象来存储User值。如何实现这一点?答案在于使用泛型和comptime。
正如我在12.2.2 节中所述,其基本思想是编写一个返回结构体定义作为输出的泛型函数。理论上,我们不需要做太多工作就能将Stack结构体转换为泛型数据结构。我们只需要将堆栈的底层数组转换为泛型数组即可。
换句话说,这个底层数组需要像一条“变色龙”。它需要适应变化,并将其转换为我们想要的任何数据类型。例如,如果我们需要创建一个用于存储u8值的堆栈,那么这个底层数组就需要是一个u8数组(即[]u8)。但如果我们需要存储User值,那么这个数组就需要是一个User数组(即[]User)。等等。
我们可以使用泛型函数来实现这一点。因为泛型函数可以接收一种数据类型作为输入,并且我们可以将这种数据类型传递给Stack对象的结构体定义。因此,我们可以使用泛型函数创建一个Stack可以存储所需数据类型的对象。如果我们想要创建一个存储User值的堆栈结构,我们将数据类型传递给这个泛型函数,它会为我们创建一个描述可以在其中存储值的对象User的结构体定义。Stack``User
请看下面的代码示例。Stack为了简洁起见,我省略了结构体定义的某些部分。但是,如果Stack本例中没有暴露结构体的某个特定部分,那是因为这部分与上一个示例相比没有变化。它保持不变。
fn Stack(comptime T: type) type {
return struct {
items: []T,
capacity: usize,
length: usize,
allocator: Allocator,
const Self = @This();
pub fn init(allocator: Allocator,
capacity: usize) !Stack(T) {
var buf = try allocator.alloc(T, capacity);
return .{
.items = buf[0..],
.capacity = capacity,
.length = 0,
.allocator = allocator,
};
}
pub fn push(self: *Self, val: T) !void {
// Truncate the rest of the struct
};
}
请注意,我们在此示例中创建了一个名为 的函数Stack()。该函数接受一个类型作为输入,并将该类型传递给Stack对象的结构体定义。数据成员items现在是一个类型为 的数组T,该类型是我们提供给函数的输入数据类型。函数val中的函数参数push()现在也是一个类型为 的值T。
我们只需为该函数提供一个数据类型,它就会创建一个Stack对象的定义,该对象可以存储我们指定的数据类型的值。在下面的示例中,我们创建了一个Stack可以存储u8值的对象的定义。该定义存储在Stacku8对象中。这个Stacku8对象将成为我们的新结构体,我们将使用它来创建我们的Stack对象。
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
const Stacku8 = Stack(u8);
var stack = try Stacku8.init(allocator, 10);
defer stack.deinit();
try stack.push(1);
try stack.push(2);
try stack.push(3);
try stack.push(4);
try stack.push(5);
try stack.push(6);
std.debug.print("Stack len: {d}\n", .{stack.length});
std.debug.print("Stack capacity: {d}\n", .{stack.capacity});
stack.pop();
std.debug.print("Stack len: {d}\n", .{stack.length});
stack.pop();
std.debug.print("Stack len: {d}\n", .{stack.length});
std.debug.print(
"Stack state: {any}\n",
.{stack.items[0..stack.length]}
);
Stack len: 6
Stack capacity: 10
Stack len: 5
Stack len: 4
Stack state: { 1, 2, 3, 4, 0, 0, 0, 0, 0, 0 }
Zig 标准库(ArrayList、、等)中的每个通用数据结构HashMap都是SinlyLinkedList通过此逻辑实现的。它们使用通用函数来创建可以与您提供的输入数据类型一起使用的结构体定义。
12.6结论
本章讨论的堆栈结构的完整源代码可在本书的官方仓库中免费获取。只需查看仓库文件夹中提供的2版本(我们的堆栈版本)和 3 版本(通用版本) 。stack.zigu32generic_stack.zigZigExamples
-
https://www.tutorialspoint.com/c_standard_library/c_function_memcpy.htm ↩︎
-
https://github.com/pedropark99/zig-book/tree/main/ZigExamples/data-structs/stack.zig ↩︎
-
https://github.com/pedropark99/zig-book/tree/main/ZigExamples/data-structs/generic_stack.zig ↩︎
13 文件系统和输入/输出IO
在本章中,我们将讨论如何使用 Zig 标准库中可执行文件系统操作的跨平台结构体和函数。这些函数和结构体大部分来自该std.fs模块。
我们还将讨论 Zig 中的输入/输出(也称为 IO)操作。大多数此类操作都是使用std.io模块中的结构体和函数完成的,该模块定义了系统_标准通道_stdout(和stdin)的文件描述符,以及创建和使用 I/O 流的函数。
13.1输入/输出基础
如果你有高级语言的使用经验,你肯定曾经使用过这种语言的输入输出功能。换句话说,你肯定遇到过需要向用户发送输出,或者接收用户输入的情况。
例如,在 Python 中,我们可以使用内置函数接收用户的输入input()。但我们也可以使用内置函数向用户打印(或“显示”)一些输出print()。所以,如果你之前用 Python 编程过,你肯定用过这些函数。
但是你知道这些函数与你的操作系统 (OS) 之间是如何关联的吗?它们究竟是如何与操作系统的资源交互来接收或发送输入/输出的。本质上,这些来自高级语言的输入/输出函数只是对操作系统_标准输出_和_标准输入通道的抽象。_
这意味着我们通过操作系统接收输入或发送输出。操作系统在用户和程序之间架起了桥梁。程序无法直接访问用户。操作系统充当程序和用户之间交换的每条消息的中介。
操作系统的标准输出和标准输入通道通常分别称为操作系统_的_和_通道_。在某些情况下,它们也被称为stdout标准_输出设备_和_标准输入设备_。顾名思义,_标准输出_是输出流经的通道,而_标准输入_是输入流经的通道。stdin
此外,操作系统通常还会创建一个专门用于交换错误消息的通道,称为_标准错误_通道(或称为stderr通道)。错误和警告消息通常会发送到这个通道。这些消息通常会以类似红色或橙色的颜色显示在终端中。
通常,每个操作系统(例如 Windows、macOS、Linux 等)都会为计算机中运行的每个程序(或进程)创建一组专用且独立的_标准输出_、标准错误_和_标准输入stdin通道。这意味着您编写的每个程序都有一个专用的、stderr和 ,stdout它们与当前正在运行的其他程序和进程的 、stdin和stderr相互独立。stdout
这是操作系统的行为,而非你所使用的编程语言。因为正如我之前所说,编程语言(尤其是高级编程语言)中的输入和输出只是对当前操作系统的简单抽象stdin。stderr也就是说stdout,无论你使用哪种编程语言,操作系统都是程序中每个输入/输出操作的中介。
13.1.1写入器和读取器模式
在 Zig 中,有一个围绕输入/输出 (IO) 的模式。我(本书作者)不知道这种模式是否有正式名称。但在本书中,我将其称为“写入器和读取器模式”。本质上,Zig 中的每个 IO 操作都是通过 或GenericReader对象GenericWriter1进行的。
这两种数据类型来自std.ioZig 标准库的模块。顾名思义,aGenericReader是一个提供从“某物”(或“某处”)读取数据的工具的对象,而 a 则GenericWriter提供将数据写入此“某物”的工具。此“某物”可能是不同的东西:例如文件系统中的文件;或者,可能是系统2中的网络套接字;或者,可能是连续的数据流,例如系统中的标准输入设备,它可能不断从用户那里接收新数据;或者,再举一个例子,游戏中的实时聊天不断接收并显示来自游戏玩家的新消息。
因此,如果您想从某个地方读取数据,就需要使用GenericReader对象。但是,如果您需要将数据写入这个“东西”,那么就需要使用GenericWriter对象。这两个对象通常都是通过文件描述符对象创建的。更具体地说,是通过该文件描述符对象的writer()和reader()方法创建的。如果您不熟悉这种类型的对象,请跳到下一节。
每个GenericWriter对象都有类似的方法print(),允许你将格式化的字符串(例如,这个格式化的字符串类似于fPython 中的字符串,或者类似于printf()C 函数)写入/发送到你正在使用的“对象”(文件、套接字、流等)。它还有一个writeAll()方法,允许你将字符串或字节数组写入“对象”。
同样,每个GenericReader对象都有类似 的方法readAll(),它允许你从“对象”(文件、套接字、流等)读取数据,直到填满一个特定的数组(即“缓冲区”)对象。换句话说,如果你向 提供了一个包含 300 个u8值的数组对象readAll(),那么该方法会尝试从“对象”读取 300 个字节的数据,并将它们存储到你提供的数组对象中。
我们还有其他方法,例如readAtLeast()方法,它允许你指定要从“某个对象”中读取的具体字节数。更详细地说,如果你给出数字n作为此方法的输入,它将尝试至少读取n来自“某物”的数据字节数。“某物”可能少于n可供您读取的数据字节数,因此,不能保证您将获得精确的n字节作为结果。
另一个有用的方法是readUntilDelimiterOrEof()。在此方法中,您可以指定一个“分隔符”。其理念是,此函数将尝试从“某些内容”中读取尽可能多的字节数据,直到到达流的末尾,或者遇到您指定的“分隔符”。
如果您不确定“某物”究竟会有多少字节,您可能会发现该readAllAlloc()方法很有用。本质上,您为该方法提供了一个分配器对象,以便它可以根据需要分配更多空间。因此,该方法将尝试读取“某物”的所有字节,并且,如果在“读取过程”的某个时刻空间不足,它将使用分配器对象分配更多空间以继续读取字节。最终,该方法返回一个包含所有读取字节的数组对象的切片。
这只是对这些类型对象中存在的方法的简要描述。但我建议您阅读官方文档,包括3和4 。我还认为阅读 Zig 标准库中定义这些对象中存在的方法(即5和6 )的模块源代码是个好主意。GenericWriterGenericReaderReader.zigWriter.zig
13.1.2介绍文件描述符
“文件描述符”对象是任何操作系统 (OS) 中每个 IO 操作背后的核心组件。该对象是操作系统中特定输入/输出 (IO) 资源的标识符(维基百科 2024 )。它描述并标识了该特定资源。IO 资源可能是:
- 文件系统中现有的文件。
- 现有的网络套接字。
- 其他类型的溪流通道。
- 终端7中的管道(或简称“管道”)。
从上面列出的要点中,我们知道虽然存在“文件”一词,但“文件描述符”可能描述的不仅仅是一个文件。“文件描述符”的概念来自可移植操作系统接口 (POSIX) API,这是一组标准,用于指导世界各地的操作系统如何实现,以保持它们之间的兼容性。
文件描述符不仅标识用于接收或发送数据的输入/输出资源,还描述该资源的位置以及当前使用的 IO 模式。例如,该 IO 资源可能仅使用“读取”模式,这意味着该资源仅对“读取操作”开放,而“写入操作”则不被授权。这些 IO 模式本质上就是你mode从fopen()C 函数以及open()Python 内置函数传入参数的模式。
在 C 语言中,“文件描述符”是一个FILE指针,但在 Zig 中,文件描述符是一个File对象。此数据类型 ( File) 在 Zig 标准库的模块中进行了描述std.fs。我们通常不会File在 Zig 代码中直接创建对象。相反,我们通常在打开 IO 资源时得到这样的对象作为结果。换句话说,我们通常会要求操作系统为我们打开一个特定的 IO 资源,如果操作系统成功打开了这个 IO 资源,它通常会将这个特定 IO 资源的文件描述符返回给我们。
因此,通常使用 Zig 标准库中的函数和方法来获取一个File对象,这些函数和方法请求操作系统打开某些 IO 资源,例如openFile()在文件系统中打开文件的方法。我们在7.4.1 节net.Stream中创建的对象也是一种文件描述符对象。
13.1.3标准_输出_
您已经在本书中了解了如何访问并使用stdoutZig 中的 来向用户发送一些输出。为此,我们使用了模块getStdOut()中的函数std.io。此函数返回一个文件描述符,该描述符描述了当前操作系统的通道。通过这个文件描述符对象,我们可以从程序的stdout读取或写入数据。stdout
虽然我们可以读取记录到通道中的内容stdout,但通常我们只会向该通道写入(或“打印”)内容。原因与我们在第 7.4.3 节中讨论的内容非常相似,当时我们讨论了在我们的小型 HTTP Server 项目中,“读取”和“写入”连接对象的含义。
当我们向通道写入数据时,我们实际上是将数据发送到该通道的另一端。相反,当我们从该通道读取数据时,我们实际上是在读取通过该通道发送的数据。由于 是stdout一个将输出发送给用户的通道,因此这里的关键动词是发送。我们想要将某些内容发送给某人,因此,我们想要将某些内容写入某个通道。
这就是为什么当我们使用 时getStdOut(),大多数情况下,我们还会使用文件描述符writer()中的方法stdout,来访问一个写入器对象,以便将内容写入此stdout通道。更具体地说,此writer()方法返回一个GenericWriter对象。该对象的主要方法之一GenericWriter就是print()我们之前用来将格式化字符串写入(或“打印”)通道的方法stdout。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
try stdout.writeAll(
"This message was written into stdout.\n"
);
}
This message was written into stdout.
此GenericWriter对象与您通常从文件描述符对象中获取的任何其他通用写入器对象类似。因此,您在将文件写入文件系统时使用的通用写入器对象中的方法,在这里也可以从 的文件描述符对象中使用,stdout反之亦然。
13.1.4标准_输入_
您可以使用模块中的函数访问 Zig 中的_标准输入_(即) 。与其兄弟()一样,此函数也返回一个描述操作系统通道的文件描述符对象。stdin``getStdIn()``std.io``getStdOut()``stdin
因为我们需要接收用户的输入,所以这里的关键动词是receive,因此,我们通常希望从通道读取stdin数据,而不是将数据写入通道。因此,我们通常使用reader()返回的文件描述符对象的 方法getStdIn()来访问一个GenericReader可以用来从 读取数据的对象stdin。
在下面的示例中,我们创建了一个可容纳 20 个字符的小缓冲区。然后,我们尝试使用stdin方法从 读取数据readUntilDelimiterOrEof(),并将数据保存到buffer对象中。另请注意,我们一直从 读取数据,stdin直到遇到换行符 ( '\n')。
如果你执行这个程序,你会注意到它会停止执行,并开始无限期地等待用户的输入。换句话说,你需要在终端中输入你的名字,然后按 Enter 键将你的名字发送到stdin。将你的名字发送到 之后stdin,程序会读取此输入,并继续执行,将给定的名字打印到stdout。在下面的例子中,我在终端中输入了我的名字(Pedro),然后按了 Enter 键。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
const stdin = std.io.getStdIn().reader();
pub fn main() !void {
try stdout.writeAll("Type your name\n");
var buffer: [20]u8 = undefined;
@memset(buffer[0..], 0);
_ = try stdin.readUntilDelimiterOrEof(buffer[0..], '\n');
try stdout.print("Your name is: {s}\n", .{buffer});
}
Type your name
Your name is: Pedro
13.1.5标准_误差_
标准_错误_(又名)的工作原理与和stderr完全相同。您只需从模块中调用该函数,即可将文件描述符发送到。理想情况下,您应该只将错误或警告消息写入,因为这是此通道的用途。stdout``stdin``getStdErr()``std.io``stderr``stderr
13.2缓冲 IO
正如我们在13.1 节中所述,输入/输出 (IO) 操作直接由操作系统执行。操作系统负责管理您要用于 IO 操作的 IO 资源。因此,IO 操作很大程度上依赖于系统调用(即直接调用操作系统)。
需要明确的是,系统调用本身并没有什么特别的问题。我们在任何用低级编程语言编写的严肃代码库中都会经常使用它们。然而,系统调用的速度总是比许多不同类型的操作慢几个数量级。
偶尔使用系统调用完全没问题。但是,如果频繁使用这些系统调用,大多数情况下应用程序的性能损失都会很明显。因此,一个好的经验法则是,只在需要时使用系统调用,并且只在不频繁的情况下使用,以将执行的系统调用次数降至最低。
13.2.1理解缓冲 IO 的工作原理
缓冲 IO 是一种实现更高性能的策略。它用于减少 IO 操作的系统调用数量,从而实现更高的性能。在图 13.1和图 13.2中,您可以找到两张不同的图表,它们展示了在无缓冲 IO 环境和有缓冲 IO 环境中执行的读取操作之间的差异。
为了更好地理解这些图表,假设我们的文件系统中有一个包含著名的 Lorem ipsum 文本8 的文本文件。我们还假设图 13.1和图 13.2中的图表展示了我们从该文本文件中读取 Lorem ipsum 文本的读取操作。查看这些图表时,您首先会注意到,在无缓冲环境中,读取操作会导致许多系统调用。更准确地说,在图13.1 中,我们从文本文件读取的每个字节都会产生一个系统调用。另一方面,在图 13.2中,我们在最开始只有一个系统调用。
当我们使用缓冲 IO 系统时,在执行第一次读取操作时,操作系统不会直接向程序发送一个字节,而是先将文件中的一大块字节发送到一个缓冲区对象(即数组)。这块字节会被缓存/存储在这个缓冲区对象中。
因此,从现在开始,对于您执行的每个新的读取操作,都无需进行新的系统调用来向操作系统请求文件中的下一个字节,而是将该读取操作重定向到缓冲区对象,该缓冲区对象已缓存了下一个字节并准备就绪。
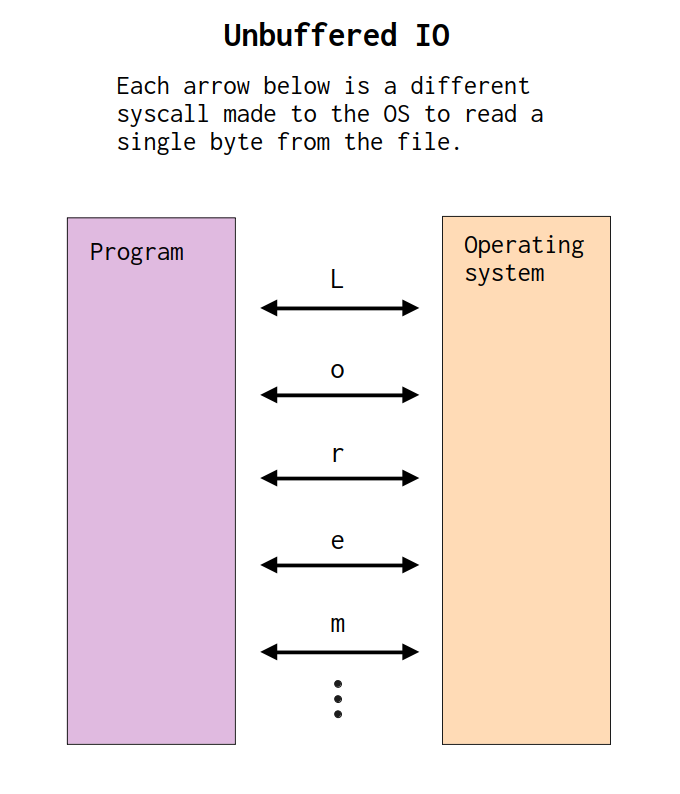
图 13.1:无缓冲 IO
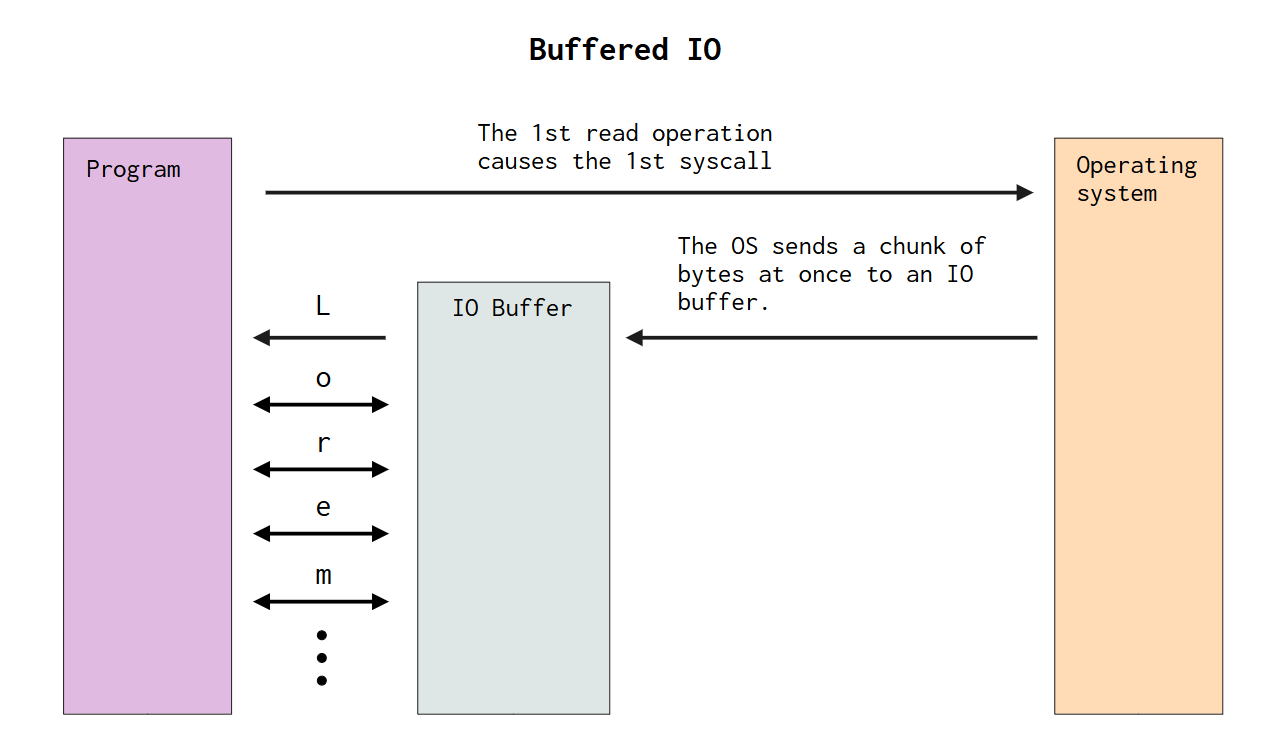
图 13.2:缓冲 IO
这是缓冲 IO 系统背后的基本逻辑。缓冲区对象的大小取决于多种因素。但它通常等于一整页内存(4096 字节)的大小。如果我们遵循这个逻辑,那么操作系统会读取文件的前 4096 个字节并将其缓存到缓冲区对象中。只要你的程序没有从缓冲区中消耗掉所有这 4096 个字节,就不会创建新的系统调用。
但是,一旦缓冲区中所有 4096 个字节都被用完,就意味着缓冲区中没有剩余字节了。在这种情况下,系统会发出一个新的系统调用,请求操作系统发送文件中接下来的 4096 个字节,这些字节再次被缓存到缓冲区对象中,然后循环再次开始。
13.2.2不同语言的缓冲 IO
在 C 语言中,通过FILE指针进行的 IO 操作默认是缓冲的,因此,至少在 C 语言中,你无需担心这个问题。但相比之下,Rust 和 Zig 中的 IO 操作不会缓冲,具体取决于你使用的标准库函数。
例如,在 Rust 中,缓冲 IO 是通过BufReader和BufWriter结构体实现的,而在 Zig 中,它通过BufferedReader和结构体实现。因此,你通过我在13.1.1 节中介绍的和对象BufferedWriter执行的任何 IO 操作都不会被缓冲,这意味着这些对象可能会根据具体情况创建大量系统调用。GenericWriter``GenericReader
13.2.3在Zig中使用缓冲IO
在 Zig 中使用缓冲 IO 实际上非常简单。您只需将GenericWriter对象传递给bufferedWriter()函数,或者将GenericReader对象传递给bufferedReader()函数即可。这些函数来自std.io模块,它们将为您构造BufferedWriter或对象。BufferedReader
创建这个新的BufferedWriter或BufferedReader对象后,您可以调用这个新对象的writer()或reader()方法来访问新的(和缓冲的)通用读取器或通用写入器。
让我们再次描述一下这个过程。每当你有一个文件描述符对象时,你首先通过调用该文件描述符对象的writer()或方法从中获取通用写入器或通用读取器对象。然后,你将这个通用写入器或通用读取器提供给或函数,该函数会创建一个新的或对象。接着,你调用这个缓冲写入器或缓冲读取器对象的或方法,这将使你能够访问缓冲的通用写入器或通用读取器对象。reader()``bufferedWriter()``bufferedReader()``BufferedWriter``BufferedReader``writer()``reader()
以这个程序为例。该程序演示了图 13.2中展示的过程。我们只是打开一个包含 Lorem ipsum 文本的文本文件,然后在 处创建一个缓冲 IO 读取器对象bufreader,并使用该bufreader对象将此文件的内容读入缓冲区对象,然后,我们将此缓冲区的内容打印到 处,以此结束程序stdout。
var file = try std.fs.cwd().openFile(
"ZigExamples/file-io/lorem.txt", .{}
);
defer file.close();
var buffered = std.io.bufferedReader(file.reader());
var bufreader = buffered.reader();
var buffer: [1000]u8 = undefined;
@memset(buffer[0..], 0);
_ = try bufreader.readUntilDelimiterOrEof(
buffer[0..], '\n'
);
try stdout.print("{s}\n", .{buffer});
Lorem ipsum dolor sit amet, consectetur
adipiscing elit. Sed tincidunt erat sed nulla ornare, nec
aliquet ex laoreet. Ut nec rhoncus nunc. Integer magna metus,
ultrices eleifend porttitor ut, finibus ut tortor. Maecenas
sapien justo, finibus tincidunt dictum ac, semper et lectus.
Vivamus molestie egestas orci ac viverra. Pellentesque nec
arcu facilisis, euismod eros eu, sodales nisl. Ut egestas
sagittis arcu, in accumsan sapien rhoncus sit amet. Aenean
neque lectus, imperdiet ac lobortis a, ullamcorper sed massa.
Nullam porttitor porttitor erat nec dapibus. Ut vel dui nec
nulla vulputate molestie eget non nunc. Ut commodo luctus ipsum,
in finibus libero feugiat eget. Etiam vel ante at urna tincidunt
posuere sit amet ut felis. Maecenas finibus suscipit tristique.
Donec viverra non sapien id suscipit.
尽管它是一个带缓冲的 IO 读取器,但该bufreader对象与其他对象类似GenericReader,并且具有完全相同的方法。因此,尽管这两种类型的对象执行截然不同的 IO 操作,但它们具有相同的接口,因此您(程序员)可以互换使用它们,而无需在源代码中进行任何更改。因此,带缓冲的 IO 读取器或带缓冲的 IO 写入器对象与其通用和非缓冲的兄弟(即我在13.1.1 节中介绍的通用读取器和通用写入器对象)具有相同的方法。
提示
一般来说,你应该始终使用缓冲 IO 读取器或缓冲 IO 写入器对象在 Zig 中执行 IO 操作。因为它们能为你的 IO 操作提供更好的性能。
13.3文件系统基础
既然我们已经讨论了 Zig 中输入/输出操作的基础知识,我们需要讨论文件系统的基础知识,这是任何操作系统的另一个核心部分。此外,文件系统与输入/输出相关,因为我们在计算机中存储和创建的文件被视为 IO 资源,正如我们在第 13.1.2 节中所述。
13.3.1当前工作目录(CWD)的概念
工作目录是您当前计算机上的根文件夹。换句话说,它是您的程序当前正在查看的文件夹。因此,每当您执行程序时,该程序始终会使用计算机上的特定文件夹。程序始终会在此文件夹中初始查找您需要的文件,并且程序也会在此文件夹中初始保存您要求它保存的所有文件。
工作目录由您在终端中调用程序的文件夹决定。换句话说,如果您在操作系统的终端中,并从该终端执行一个二进制文件(即程序),则终端指向的文件夹就是正在执行的程序的当前工作目录。
图 13.3中展示了我从终端执行程序的示例。我们正在执行zig编译器通过编译名为 的 Zig 模块输出的程序hello.zig。在这种情况下,CWD 指的是zig-book文件夹。换句话说,在hello.zig程序执行时,它会查看该zig-book文件夹,并且我们在该程序内部执行的任何文件操作都将以该zig-book文件夹为“起点”,或者说“中心点”。
图 13.3:从终端执行程序
即使我们根植于计算机的某个特定文件夹(在图 13.3中为文件zig-book夹),这并不意味着我们不能访问或写入计算机其他位置的资源。当前工作目录 (CWD) 机制只是定义了程序在查找所需文件时首先在何处查找。这并不妨碍您访问位于计算机其他位置的文件。但是,要访问当前工作目录以外的文件夹中的任何文件,您必须提供该文件或文件夹的路径。
13.3.2路径的概念
路径本质上是一个位置。它指向文件系统中的一个位置。我们使用路径来描述文件和文件夹在计算机中的位置。路径的一个重要特点是它们始终以字符串形式写入,即始终以文本值的形式提供。
您可以为任何操作系统中的任何程序提供两种类型的路径:相对路径或绝对路径。绝对路径是从文件系统根目录开始,一直到您要引用的文件名或特定文件夹的路径。这种路径称为绝对路径,因为它指向计算机上唯一的绝对位置。也就是说,您的计算机上没有其他现有位置与此路径相对应。它是一个唯一标识符。
在 Windows 中,绝对路径是以硬盘标识符开头的路径(例如 C:/Users/pedro)。另一方面,Linux 和 macOS 中的绝对路径是以正斜杠字符开头的路径(例如 )。请注意,路径由“段”组成。每个段通过斜杠字符(或)/usr/local/bin相互连接。在 Windows 上,通常使用反斜杠()连接路径段。而在 Linux 和 macOS 上,正斜杠()是用于连接路径段的字符。\``/``\``/
相对路径是从 CWD 开始的路径。换句话说,相对路径是“相对于 CWD”的。图 13.3hello.zig中用于访问文件的路径就是一个相对路径的示例。该路径如下所示。该路径从 CWD(在图 13.3的上下文中是文件夹)开始,然后进入文件夹,再进入文件。zig-book``ZigExamples``zig-basics``hello.zig
ZigExamples/zig-basics/hello_world.zig
13.3.3路径通配符
提供路径(尤其是相对路径)时,您可以选择使用_通配符_。路径中有两种常用的_通配符_,即“一个句点”(.)和“两个句点”(..)。换句话说,这两个特定字符在路径中使用时具有特殊含义,并且可以在任何操作系统(Mac、Windows、Linux 等)上使用。也就是说,它们是“跨平台的”。
“一个句点”表示当前目录的别名。这意味着相对路径"./Course/Data/covid.csv"和"Course/Data/covid.csv"是等效的。另一方面,“两个句点”指的是上一个目录。例如, 路径"Course/.."相当于 路径".",即当前工作目录。
因此,路径"Course/.."指的是文件夹之前的文件夹Course。再举一个例子,路径指的是文件夹之前的文件夹内的"src/writexml/../xml.cpp"文件,在本例中,文件夹就是文件夹。因此,此路径等同于。xml.cpp``writexml``src``"src/xml.cpp"
13.4 CWD 处理程序
在 Zig 中,文件系统操作通常通过目录处理程序对象进行。Zig 中的目录处理程序是一个 类型的对象Dir,该对象描述计算机文件系统中的特定文件夹。通常Dir通过调用std.fs.cwd()函数来创建对象。此函数返回一个Dir指向(或描述)当前工作目录 (CWD) 的对象。
通过此Dir对象,您可以创建新文件、修改文件或读取 CWD 中的现有文件。换句话说,Dir对象是 Zig 中执行多种文件系统操作的主要入口点。在下面的示例中,我们将创建此Dir对象并将其存储在该cwd对象中。虽然我们在此代码示例中没有使用此对象,但在接下来的示例中我们将大量使用它。
const cwd = std.fs.cwd();
_ = cwd;
13.5文件操作
13.5.1创建文件
我们使用createFile()该Dir对象中的方法创建新文件。只需提供要创建的文件名,此函数就会执行创建该文件所需的步骤。您还可以为此函数提供一个相对路径,它将按照此路径(相对于 CWD)创建文件。
此函数可能会返回错误,因此,您应该使用try、或第十章catch中介绍的任何其他方法来处理可能的错误。但如果一切顺利,此方法将返回一个文件描述符对象(即一个对象),您可以通过该对象使用我之前介绍的 IO 操作向文件添加内容。createFile()``File
以下面的代码示例为例。在本例中,我们创建了一个名为 的新文本文件foo.txt。如果函数createFile()执行成功,名为 的对象file将包含一个文件描述符对象,我们可以使用该对象向文件写入(或添加)新内容,就像本例中一样,使用缓冲写入器对象向文件写入一行新文本。
现在,简要说明一下,当我们在 C 语言中创建文件描述符对象时,通过使用像 这样的 C 函数fopen(),我们必须始终在程序结束时关闭该文件,或者,一旦我们完成对文件执行的所有操作后立即关闭该文件。在 Zig 中,这没有什么不同。因此,每次我们创建一个新文件时,该文件都会保持“打开”状态,等待执行某些操作。一旦我们完成操作,我们总是必须关闭此文件,以释放与其关联的资源。在 Zig 中,我们通过close()从文件描述符对象调用方法来执行此操作。
const cwd = std.fs.cwd();
const file = try cwd.createFile("foo.txt", .{});
// Don't forget to close the file at the end.
defer file.close();
// Do things with the file ...
var fw = file.writer();
_ = try fw.writeAll(
"Writing this line to the file\n"
);
因此,在这个例子中,我们不仅在文件系统中创建了一个文件,还使用 返回的文件描述符对象向该文件写入了一些数据createFile()。如果您尝试创建的文件已存在于文件系统中,则此createFile()调用将覆盖该文件的内容,或者换句话说,它将擦除现有文件的所有内容。
如果您不希望发生这种情况,即您不想覆盖现有文件的内容,但无论如何都想将数据写入该文件(即,您想将数据附加到该文件),则应该使用对象openFile()中的方法Dir。
另一个重要的方面是createFile(),此方法会创建一个默认不开放读取操作的文件。这意味着您无法读取此文件。您不被允许这样做。例如,您可能想在程序执行开始时向此文件中写入一些内容。然后,在程序的某个时刻,您可能需要读取您在此文件中写入的内容。如果您尝试从此文件中读取数据,则可能会出现NotOpenForReading错误。
但是如何克服这个障碍呢?如何创建一个可以读取的文件呢?你只需要read在 的第二个参数中将标志设置为 true即可createFile()。当将此标志设置为 true 时,该文件将以“读取权限”创建,因此,如下所示的程序将生效:
const cwd = std.fs.cwd();
const file = try cwd.createFile(
"foo.txt",
.{ .read = true }
);
defer file.close();
var fw = file.writer();
_ = try fw.writeAll("We are going to read this line\n");
var buffer: [300]u8 = undefined;
@memset(buffer[0..], 0);
try file.seekTo(0);
var fr = file.reader();
_ = try fr.readAll(buffer[0..]);
try stdout.print("{s}\n", .{buffer});
We are going to read this line
如果您不熟悉位置指示器,您可能无法识别该方法。如果是这样,请不要担心,我们将在13.6 节seekTo()中进一步讨论此方法。但本质上,此方法是将位置指示器移回文件开头,以便我们可以从头开始读取文件内容。
13.5.2打开文件并向其中附加数据
打开文件很简单。只需使用openFile()方法而不是createFile()。在第一个参数中,openFile()提供要打开的文件的路径。然后,在第二个参数中,提供标志(或选项),用于指示如何打开文件。
您可以通过访问9 的openFile()文档来查看完整的选项列表。但您最肯定会使用的主要标志是标志。此标志指定文件打开时将使用的 IO 模式。有三种 IO 模式,或者说,您可以为该标志提供三个值,它们是:OpenFlagsmode
read_only,仅允许对文件进行读取操作。所有写入操作均被阻止。write_only,仅允许对文件进行写入操作。所有读取操作均被阻止。read_write,允许对文件进行写入和读取操作。
这些模式类似于您提供给Python 内置函数10或C 函数11的参数mode的模式。在下面的代码示例中,我们使用某种模式打开文本文件,并在文件末尾附加一行新文本。我们利用这段时间来确保将文本附加到文件末尾。同样,第 13.6 节将更深入地介绍此类方法。open()mode``fopen()foo.txt``write_only``seekFromEnd()``seekFromEnd()
const cwd = std.fs.cwd();
const file = try cwd.openFile(
"foo.txt", .{ .mode = .write_only }
);
defer file.close();
try file.seekFromEnd(0);
var fw = file.writer();
_ = try fw.writeAll("Some random text to write\n");
13.5.3删除文件
有时,我们只需要删除/移除已有的文件。为此,我们使用该deleteFile()方法。您只需提供要删除的文件的路径,该方法就会尝试删除位于此路径的文件。
const cwd = std.fs.cwd();
try cwd.deleteFile("foo.txt");
13.5.4复制文件
要复制现有文件,我们使用该copyFile()方法。该方法中的第一个参数是要复制的文件的路径。第二个参数是一个Dir对象,即目录处理程序,更具体地说,是一个Dir指向计算机中要将文件复制到的文件夹的对象。第三个参数是文件的新路径,或者换句话说,是文件的新位置。第四个参数是复制操作中要使用的选项(或标志)。
您提供给此方法作为输入的对象Dir将用于将文件复制到新位置。您可以Dir在调用此copyFile()方法之前创建此对象。也许您计划将文件复制到计算机中完全不同的位置,因此可能需要为该位置创建一个目录处理程序。但是,如果您要将文件复制到 CWD 的子文件夹,那么您只需将 CWD 处理程序传递给此参数即可。
const cwd = std.fs.cwd();
try cwd.copyFile(
"foo.txt",
cwd,
"ZigExamples/file-io/foo.txt",
.{}
);
13.5.5阅读文档!
对象上还有一些其他有用的文件操作方法Dir,例如方法,但我建议您阅读类型12writeFile()的文档以探索其他可用的方法,因为我已经谈论了太多关于它们的内容。Dir
13.6位置指示器
位置指示器类似于一种游标,或者说是一种索引。这个“索引”标识了文件描述符对象当前正在查看的文件(或数据流)中的当前位置。创建文件描述符时,位置指示器从文件的开头(或数据流的开头)开始。当你读取或写入该文件描述符对象所描述的文件(或套接字、数据流等)时,最终会移动位置指示器。
换句话说,任何 IO 操作都有一个共同的副作用,那就是移动位置指示器。例如,假设我们有一个总共 300 字节的文件。如果你从文件中读取 100 字节,那么位置指示器就会向前移动 100 字节。如果你尝试向同一个文件中写入 50 字节,那么这 50 字节将从位置指示器指示的当前位置写入。由于位置指示器位于文件开头向前 100 字节的位置,因此这 50 字节将被写入文件中间。
这就是为什么我们在13.5.1 节seekTo()中给出的最后一个代码示例中使用了该方法。我们使用该方法将位置指示器移回文件开头,这样可以确保我们从文件开头写入想要写入的文本,而不是从文件中间写入。因为在写入操作之前,我们执行了读取操作,这意味着位置指示器在这次读取操作中被移动了。
可以使用文件描述符对象中的“seek”方法来更改(或修改)其位置指示器,这些方法是:seekTo()、seekFromEnd()和。这些方法具有与13seekBy() C 函数相同的效果,或者说相同的职责。fseek()
考虑到offset指的是您提供给这些“查找”方法的索引,下面的要点总结了每种方法的效果。简要说明一下,对于seekFromEnd()和seekBy(),offset提供的 可以是正索引,也可以是负索引。
seekTo()``offset将把位置指示器移动到距文件开头字节的位置。seekFromEnd()``offset将把位置指示器移动到距文件末尾字节的位置。seekBy()将把位置指示器移动到offset文件中距离当前位置 字节的位置。
13.7目录操作
13.7.1迭代目录中的文件
与文件系统相关的最经典任务之一是能够迭代目录中的现有文件。要迭代目录中的文件,我们需要创建一个迭代器对象。
您可以使用对象的或 方法iterate()生成这样的迭代器对象。这两个方法都返回一个迭代器对象作为输出,您可以使用方法来推进它。这两个方法的区别在于,返回一个非递归迭代器,而返回一个非递归迭代器。这意味着 返回的迭代器不仅会迭代当前目录中可用的文件,还会迭代当前目录中任何子目录中的文件。walk()``Dir``next()``iterate()``walk()``walk()
在下面的示例中,我们显示了存储在目录 内的文件的名称ZigExamples/file-io。请注意,我们必须通过 函数打开此目录。另请注意,我们在 的第二个参数中openDir()提供了 标志。此标志很重要,因为如果没有此标志,我们将无法遍历此目录中的文件。iterate``openDir()
const cwd = std.fs.cwd();
const dir = try cwd.openDir(
"ZigExamples/file-io/",
.{ .iterate = true }
);
var it = dir.iterate();
while (try it.next()) |entry| {
try stdout.print(
"File name: {s}\n",
.{entry.name}
);
}
File name: create_file_and_write_toit.zig
File name: create_file.zig
File name: lorem.txt
File name: iterate.zig
File name: delete_file.zig
File name: append_to_file.zig
File name: user_input.zig
File name: foo.txt
File name: create_file_and_read.zig
File name: buff_io.zig
File name: copy_file.zig
13.7.2创建新目录
在创建目录时,有两个比较重要的方法: 和makeDir()。makePath()这两个方法的区别在于makeDir()每次调用只能在当前目录中创建一个目录,而makePath()可以在同一次调用中递归创建子目录。
这就是此方法名为“make path”的原因。它将根据需要创建尽可能多的子目录,以创建您输入的路径。因此,如果您将路径"sub1/sub2/sub3"作为此方法的输入,它将在同一函数调用中创建三个不同的子目录,分别sub1为 、sub2和sub3。相反,如果您将这样的路径作为 的输入makeDir(),则可能会出现错误,因为此方法只能创建一个子目录。
const cwd = std.fs.cwd();
try cwd.makeDir("src");
try cwd.makePath("src/decoders/jpg/");
13.7.3删除目录
要删除目录,只需将要删除的目录路径作为对象输入到deleteDir()方法中Dir即可。在下面的示例中,我们将删除上src一个示例中刚刚创建的目录。
const cwd = std.fs.cwd();
try cwd.deleteDir("src");
13.8结论
在本章中,我描述了如何在 Zig 中执行最常见的文件系统和 IO 操作。但您可能会觉得本章缺少一些其他不太常见的操作,例如:如何重命名文件,如何打开目录,如何创建符号链接,或者如何使用它来测试计算机中是否存在特定路径。但对于所有这些不太常见的任务,我建议您阅读类型14access()的文档,因为您可以在那里找到对这些情况的很好的描述。Dir
-
以前,这些对象被称为
Reader和Writer对象。↩︎ -
我们在第 7.4.1 节中创建的套接字对象是网络套接字的示例。↩︎
-
https://ziglang.org/documentation/master/std/#std.io.GenericWriter。↩︎
-
https://ziglang.org/documentation/master/std/#std.io.GenericReader。↩︎
-
https://github.com/ziglang/zig/blob/master/lib/std/io/Reader.zig。↩︎
-
https://github.com/ziglang/zig/blob/master/lib/std/io/Writer.zig。↩︎
-
管道是一种进程间通信(或称进程间 IO)的机制。你也可以将管道理解为“一组通过系统标准输入/输出设备链接在一起的进程”。例如,在 Linux 中,通过在终端内使用“管道”字符 (
|)连接两个或多个终端命令来创建管道。↩︎ -
https://ziglang.org/documentation/master/std/#std.fs.File.OpenFlags ↩︎
-
https://docs.python.org/3/tutorial/inputoutput.html#reading-and-writing-files ↩︎
-
https://www.tutorialspoint.com/c_standard_library/c_function_fopen.htm ↩︎
14 Zig 与 C 的互操作性
在本章中,我们将讨论 Zig 与 C 语言的互操作性。我们已经在9.11 节讨论了如何使用zig编译器构建 C 代码。但我们还没有讨论如何在 Zig 中实际使用 C 代码。换句话说,我们还没有讨论如何从 Zig 调用和使用 C 代码。
这是本章的主题。此外,在本书的下一个小项目中,我们将使用一个 C 库。因此,我们将在下一个项目中将这里讨论的很多知识付诸实践。
14.1如何从Zig调用C代码
与 C 语言的互操作性并不是什么新鲜事。大多数高级编程语言都具有 FFI(外部函数接口),可用于调用 C 代码。例如,Python 有 Cython,R 有.Call(),JavaScript 有ccall(),等等。但 Zig 与 C 语言的集成更深层次,这不仅影响 C 代码的调用方式,还影响 C 代码的编译方式以及如何将其合并到 Zig 项目中。
总而言之,Zig 与 C 具有很好的互操作性。如果您想从 Zig 调用任何 C 代码,则必须执行以下步骤:
- 将 C 头文件导入到您的 Zig 代码中。
- 将您的 Zig 代码与 C 库链接。
14.1.1导入 C 头文件的策略
在Zig中使用C代码总是涉及执行上面提到的两个步骤。然而,当我们具体讨论上面列出的第一步时,目前有两种不同的方法来执行这第一步,它们是:
- 通过命令将C头文件翻译成Zig代码,
zig translate-c然后导入使用翻译后的Zig代码。 @cImport()通过内置函数将 C 头文件直接导入到您的 Zig 模块中。
如果您不熟悉translate-c,这是编译器内部的一个子命令zig,它以 C 文件作为输入,并输出这些 C 文件中 C 代码的 Zig 表示形式。换句话说,这个子命令的工作原理类似于转译器。它接受 C 代码,并将其转换为等效的 Zig 代码。
我认为可以将其解释translate-c为一个生成 Zig 绑定到 C 代码的工具,类似于rust-bindgen1工具,该工具生成 Rust FFI 绑定到 C 代码。但这并不是对 的准确解释translate-c。该工具背后的想法是将 C 代码真正转换为 Zig 代码。
现在,从表面上看,@cImport()vstranslate-c似乎是两种完全不同的策略。但实际上,它们实际上是完全相同的策略。因为在底层,@cImport()内置函数只是 的快捷方式translate-c。这两种工具都使用相同的“C 到 Zig”转换功能。因此,当您使用 时@cImport(),实际上是在要求zig编译器将 C 头文件转换为 Zig 代码,然后将此 Zig 代码导入到您当前的 Zig 模块中。
目前,Zig 项目中有一个已接受的提案,即迁移@cImport()到 Zig 构建系统2。如果该提案得以实施,那么“使用@cImport()”策略将转变为“在 Zig 构建脚本中调用一个翻译 C 函数”。因此,将 C 代码转换为 Zig 代码的步骤将转移到 Zig 项目的构建脚本中,您只需将翻译后的 Zig 代码导入 Zig 模块即可开始从 Zig 调用 C 代码。
如果你仔细思考一下这个提议,你就会明白这其实只是一个小小的改变。我的意思是,逻辑是一样的,步骤也基本一样。唯一的区别是,其中一个步骤将被移到你的 Zig 项目的构建脚本中。
14.1.2将 Zig 代码与 C 库链接
无论您选择上一节中的哪一种策略,如果您想从 Zig 调用 C 代码,则必须将您的 Zig 代码与包含您要调用的 C 代码的 C 库链接起来。
换句话说,每次在 Zig 代码中使用 C 代码时,都会在构建过程中引入依赖项。对于任何有 C 和 C++ 使用经验的人来说,这应该不足为奇。因为在 C 语言中也一样。每次在 C 代码中使用 C 库时,也必须构建并将 C 代码与正在使用的 C 库链接起来。
当我们在 Zig 代码中使用 C 库时,zig编译器需要访问 Zig 代码中调用的 C 函数的定义。该库的 C 头文件提供了这些 C 函数的声明,但没有提供它们的定义。因此,为了访问这些定义,zig编译器需要构建 Zig 代码,并在构建过程中将其与 C 库链接。
正如我们在第 9 章中讨论的那样,将某些内容链接到库有不同的策略。这可能涉及先构建 C 库,然后将其与 Zig 代码链接。或者,如果此 C 库已在您的系统中构建并安装,则也可能仅涉及链接步骤。无论如何,如果您对此有任何疑问,请返回第 9 章。
14.2导入 C 头文件
在第 14.1.1 节中,我们描述了目前有两种不同的路径可以将 C 头文件导入 Zig 模块,translate-c或者@cImport()。本节将分别更详细地描述每种策略。
14.2.1策略 1:使用translate-c
当我们选择此策略时,首先需要使用该translate-c工具将要使用的 C 头文件转换为 Zig 代码。例如,假设我们想使用C 头文件fopen()中的 C 函数stdio.h。我们可以stdio.h通过以下 bash 命令翻译 C 头文件:
zig translate-c /usr/include/stdio.h \
-lc -I/usr/include \
-D_NO_CRT_STDIO_INLINE=1 > c.zig \
请注意,在此 bash 命令中,我们传递了必要的编译器标志(-D用于定义宏、-l链接库、-I添加“包含路径”)来编译和使用stdio.h头文件。另请注意,我们将翻译过程的结果保存在名为 的 Zig 模块中c.zig。
因此,运行此命令后,我们要做的就是导入此c.zig模块,然后开始调用您想要从中调用的 C 函数。下面的示例演示了这一点。记住我们在14.1.2 节中讨论的内容很重要。为了编译此示例,您必须通过向编译器libc传递标志来将此代码链接到。-lc``zig
const c = @import("c.zig");
pub fn main() !void {
const x: f32 = 1772.94122;
_ = c.printf("%.3f\n", x);
}
1772.941
14.2.2策略 2:使用@cImport()
要将 C 头文件导入到我们的 Zig 代码中,我们可以使用内置函数@cInclude()和@cImport()。在@cImport()函数内部,我们打开一个块(带有一对花括号)。如果需要,我们可以在这个块中包含多个@cDefine()调用,以便在包含这个特定的 C 头文件时定义 C 宏。但在大多数情况下,您可能只需要在这个块中使用一个调用,即对 的调用@cInclude()。
此@cInclude()函数相当于#includeC语言中的语句。您提供要包含的C头文件的名称作为此@cInclude()函数的输入,然后结合@cImport()它将执行必要的步骤将此C头文件包含到您的Zig代码中。
您应该将 的结果绑定@cImport()到一个常量对象,就像对 所做的那样@import()。您只需将结果分配给 Zig 代码中的一个常量对象,这样,在 C 头文件中定义的所有 C 函数、C 结构、C 宏等都可以通过这个常量对象访问。
请看下面的代码示例,我们导入了标准 I/OC 库 ( stdio.h),并调用了C 函数printf()3。请注意,我们在此示例中还使用了 C 函数powf()4,它来自 C 数学库 ( )。为了编译此示例,您必须将标志和传递给编译器math.h,将此 Zig 代码与 C 标准库和 C 数学库链接起来。-lc``-lm``zig
const c = @cImport({
@cDefine("_NO_CRT_STDIO_INLINE", "1");
@cInclude("stdio.h");
@cInclude("math.h");
});
pub fn main() !void {
const x: f32 = 15.2;
const y = c.powf(x, @as(f32, 2.6));
_ = c.printf("%.3f\n", y);
}
1182.478
14.3关于将 Zig 值传递给 C 函数
Zig 对象与其 C 语言等效对象之间存在一些内在差异。最明显的差异可能是 C 字符串和 Zig 字符串之间的差异,我已在1.8 节中描述过。Zig 字符串是包含任意字节数组和长度值的对象。而 C 字符串通常只是一个指向以空字符结尾的任意字节数组的指针。
由于这些内在的差异,在某些特定情况下,在将 Zig 对象转换为 C 兼容值之前,您不能直接将 Zig 对象作为输入传递给 C 函数。但是,在其他一些情况下,您可以将 Zig 对象和 Zig 文字值直接作为输入传递给 C 函数,并且一切都会正常工作,因为zig编译器会为您处理所有事情。
因此,我们这里描述了两种不同的场景。我们称之为“自动转换”和“需要转换”。“自动转换”场景是指zig编译器为您处理所有事情,并自动将您的 Zig 对象/值转换为 C 兼容值。相比之下,“需要转换”场景是指您(程序员)有责任将该 Zig 对象转换为 C 兼容值,然后再将其传递给 C 代码。
这里没有描述第三种情况,即在 Zig 代码中创建一个 C 对象、C 结构体或 C 兼容值,并将此 C 对象/值作为输入传递给 Zig 代码中的 C 函数。这种情况将在后面的14.4 节中描述。在本节中,我们将重点介绍将 Zig 对象/值传递给 C 代码的场景,而不是将 C 对象/值传递给 C 代码的场景。
14.3.1 “自动转换”场景
“自动转换”场景是指zig编译器自动将我们的 Zig 对象转换为与 C 兼容的值。这种特定场景主要发生在两种情况下:
- 带有字符串文字值;
- 与第 1.5 节中介绍的任何原始数据类型。
当我们考虑上面描述的第二个实例时,zig编译器会自动将任何原始数据类型转换为它们的 C 等效类型,因为编译器知道如何正确地将 a 转换i16为 a signed short,或者将 au8转换为 a unsigned char,等等。现在,当我们考虑字符串文字值时,它们也可以自动转换为 C 字符串,特别是因为zig编译器不会强制将特定的 Zig 数据类型强制转换为字符串文字,除非您将此字符串文字存储到 Zig 对象中,并明确注释此对象的数据类型。
因此,使用字符串文字值,zig编译器可以更自由地推断在每种情况下应使用哪种数据类型。您可以说字符串文字值根据其使用的上下文“继承其数据类型”。大多数情况下,这种数据类型将是我们通常与 Zig 字符串关联的类型([]const u8)。但根据情况,它可能是不同的类型。当zig编译器检测到您正在提供字符串文字值作为某个 C 函数的输入时,编译器会自动将此字符串文字解释为 C 字符串值。
举个例子,请看下面公开的代码。这里我们使用fopen()C 函数来简单地打开和关闭一个文件。如果您不知道这个fopen()函数在 C 语言中是如何工作的,它需要两个 C 字符串作为输入。但在下面的代码示例中,我们将一些用 Zig 代码编写的字符串文字直接作为输入传递给这个fopen()C 函数。
换句话说,我们没有进行任何从 Zig 字符串到 C 字符串的转换。我们只是将 Zig 字符串字面量直接作为输入传递给 C 函数。而且它运行良好!因为编译器会"foo.txt"根据当前上下文将字符串解释为 C 字符串。
const c = @cImport({
@cDefine("_NO_CRT_STDIO_INLINE", "1");
@cInclude("stdio.h");
});
pub fn main() !void {
const file = c.fopen("foo.txt", "rb");
if (file == null) {
@panic("Could not open file!");
}
if (c.fclose(file) != 0) {
return error.CouldNotCloseFileDescriptor;
}
}
让我们做一些实验,用不同的方式编写相同的代码,看看这会对程序产生什么影响。首先,我们将字符串存储"foo.txt"在一个 Zig 对象中,就像path下面的对象一样,然后将这个 Zig 对象作为输入传递给fopen()C 函数。
如果我们这样做,程序仍然可以编译并成功运行。请注意,在下面的示例中,我省略了大部分代码。这只是为了简洁起见,因为程序的其余部分仍然相同。此示例与上一个示例的唯一区别仅在于下面显示的这两行代码。
const path = "foo.txt";
const file = c.fopen(path, "rb");
// Remainder of the program
现在,如果为对象指定显式数据类型会发生什么path?好吧,如果我通过使用数据类型注释zig该对象来强制编译器将此对象解释path为 Zig 字符串对象,那么实际上会收到编译错误,如下所示。我们之所以会收到此编译错误,是因为现在我强制编译器将其解释为 Zig 字符串对象。path``[]const u8``zig``path
根据错误消息,fopen()C 函数应该接收类型为[*c]const u8(C 字符串) 的输入值,而不是类型为[]const u8(Zig 字符串) 的值。更详细地说,该类型[*c]const u8实际上是 C 字符串的 Zig 类型表示。该类型的部分标识一个 C 指针。因此,这个 Zig 类型本质上意味着:一个指向常量字节[*c]数组 ( ) 的 C 指针。[*c]``const u8
const path: []const u8 = "foo.txt";
const file = c.fopen(path, "rb");
// Remainder of the program
t.zig:2:7 error: expected type '[*c]const u8', found '[]const u8':
const file = c.fopen(path, "rb");
^~~~
因此,当我们专门讨论字符串文字值时,只要您不为这些字符串文字值提供明确的数据类型,zig编译器就应该能够根据需要自动将它们转换为 C 字符串。
但是,如果使用1.5 节中介绍的原始数据类型呢?我们以下面的代码为例。在这里,我们将一些浮点字面值作为 C 函数的输入powf()。请注意,此代码示例已成功编译并运行。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
const cmath = @cImport({
@cInclude("math.h");
});
pub fn main() !void {
const y = cmath.powf(15.68, 2.32);
try stdout.print("{d}\n", .{y});
}
593.2023
再次强调,由于zig编译器没有将特定的数据类型与字面值关联起来15.68,2.32乍一看,编译器可以在将这些值传递给 C 函数之前自动将其转换为相应的 C float(或)等效值。现在,即使我通过将这些字面值存储到 Zig 对象中并显式注释这些对象的类型,赋予它们显式的 Zig 数据类型,代码仍然可以编译并成功运行。double``powf()
const x: f32 = 15.68;
const y = cmath.powf(x, 2.32);
// The remainder of the program
593.2023
14.3.2 “需求转换”场景
“需要转换”的情况是指我们需要手动将 Zig 对象转换为 C 兼容值,然后再将其作为输入传递给 C 函数。将 Zig 字符串对象传递给 C 函数时,就会遇到这种情况。
我们已经在上一个fopen()示例中看到了这种特定情况,该示例如下所示。您可以看到,在这个示例中,我们[]const u8为path对象赋予了显式的 Zig 数据类型(),因此,我们强制zig编译器将此path对象视为 Zig 字符串对象。因此,我们现在需要在path将此对象传递给 之前手动将其转换为 C 字符串fopen()。
const path: []const u8 = "foo.txt";
const file = c.fopen(path, "rb");
// Remainder of the program
t.zig:10:26: error: expected type '[*c]const u8', found '[]const u8'
const file = c.fopen(path, "rb");
^~~~
将 Zig 字符串对象转换为 C 字符串有多种方法。解决此问题的一种方法是提供指向底层字节数组的指针,而不是直接提供 Zig 对象作为输入。您可以使用ptrZig 字符串对象的属性访问此指针。
path下面的代码示例演示了这一策略。请注意,通过属性传入指向底层数组的指针ptr,我们在使用 C 函数时不会出现编译错误fopen()。
const path: []const u8 = "foo.txt";
const file = c.fopen(path.ptr, "rb");
// Remainder of the program
此策略之所以有效,是因为指向属性中底层数组的指针在ptr语义上与指向字节数组的 C 指针(即 类型的 C 对象)相同*unsigned char。这就是为什么此选项也解决了将 Zig 字符串转换为 C 字符串的问题。
另一种选择是使用内置函数将 Zig 字符串对象显式转换为 C 指针@ptrCast()。使用此函数,我们可以将 类型的对象转换[]const u8为 类型的对象[*c]const u8。正如我在上一节中所述,[*c]类型的部分表示它是一个 C 指针。不推荐使用此策略。但它有助于演示 的用法@ptrCast()。
@as()您可能还记得2.5 节@ptrCast()的内容。回顾一下,内置函数用于将 Zig 值从类型“x”显式转换(或强制转换)为类型“y”的值。但在本例中,我们转换的是指针对象。每次 Zig 中的某些“类型强制转换操作”中涉及指针时,都会涉及该函数。@as()``@ptrCast()
在下面的示例中,我们使用此函数将path对象转换为指向字节数组的 C 指针。然后,我们将此 C 指针作为输入传递给fopen()函数。请注意,此代码示例成功编译,没有任何错误。
const path: []const u8 = "foo.txt";
const c_path: [*c]const u8 = @ptrCast(path);
const file = c.fopen(c_path, "rb");
// Remainder of the program
14.4在Zig中创建C对象
在 Zig 代码中创建 C 对象,或者换句话说,创建 C 结构体的实例实际上相当容易。首先,您需要导入 C 头文件(如我在14.2 节中所述),该文件定义了您要在 Zig 代码中实例化的 C 结构体。之后,您只需在 Zig 代码中创建一个新对象,并使用 C 结构体的数据类型对其进行注释即可。
例如,假设我们有一个名为 的 C 头文件user.h,并且该头文件声明了一个名为 的新结构体User。该 C 头文件如下所示:
#include <stdint.h>
typedef struct {
uint64_t id;
char* name;
} User;
这个UserC 结构体有两个不同的字段,或者说两个结构体成员,分别名为id和name。 字段id是一个无符号的 64 位整数值,而 字段name只是一个标准的 C 字符串。现在,假设我想在我的 Zig 代码中创建这个结构体的实例User。我可以通过将此user.h头文件导入到我的 Zig 代码中,并创建一个类型为 的新对象来实现User。这些步骤在下面的代码示例中重现。
undefined请注意,我在此示例中使用了关键字。这使我new_user无需为对象提供初始值即可创建对象。因此,与此new_user对象关联的底层内存未初始化,即,该内存当前填充的是“垃圾”值。因此,此表达式与 C 语言中的表达式具有相同的效果User new_user;,即“声明一个名为new_user类型的新对象User”。
new_user我们的责任是通过为 C 结构体的成员(或字段)赋值来正确地初始化与此对象关联的内存。在下面的例子中,我将整数 1 赋值给成员id。我还将字符串保存"pedropark99"到成员中name。请注意,在此示例中,我手动在为该字符串分配的数组末尾添加了一个空字符(零字节)。这个空字符在 C 语言中标志着数组的结束。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
const c = @cImport({
@cInclude("user.h");
});
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var new_user: c.User = undefined;
new_user.id = 1;
var user_name = try allocator.alloc(u8, 12);
defer allocator.free(user_name);
@memcpy(user_name[0..(user_name.len - 1)], "pedropark99");
user_name[user_name.len - 1] = 0;
new_user.name = user_name.ptr;
}
因此,在上面的例子中,我们手动初始化了 C 结构体的每个字段。我们可以说,在这种情况下,我们正在“手动实例化 C 结构体对象”。但是,当我们在 Zig 代码中使用 C 库时,很少需要像这样手动实例化 C 结构体。只是因为 C 库通常在其公共 API 中提供了一个“构造函数”。因此,我们通常依赖这些构造函数来正确地初始化 C 结构体及其字段。
例如,考虑一下 Harfbuzz C 库。这是一个文本整形 C 库,它围绕“缓冲区对象”工作,或者更具体地说,是 C 结构体的实例hb_buffer_t。因此,如果我们想使用这个 C 库,我们需要创建这个 C 结构体的实例。幸运的是,这个库提供了函数hb_buffer_create(),我们可以使用它来创建这样的对象。因此,创建此类对象所需的 Zig 代码可能如下所示:
const c = @cImport({
@cInclude("hb.h");
});
var buf: c.hb_buffer_t = c.hb_buffer_create();
// Do stuff with the "buffer object"
因此,我们不需要手动创建 C 结构体的实例hb_buffer_t,也不需要手动为该结构体中的每个字段赋值。因为构造函数hb_buffer_create()已经为我们完成了这项繁重的工作。
由于此buf对象以及new_user前面示例中的对象都是 C 结构体的实例,因此这些对象本身就是 C 兼容值。它们是在我们的 Zig 代码中定义的 C 对象。因此,您可以自由地将这些对象作为输入传递给任何期望接收此类 C 结构体作为输入的 C 函数。您无需使用任何特殊语法,也无需以任何特殊方式转换它们即可在 C 代码中使用它们。这就是我们在 Zig 代码中创建和使用 C 对象的方式。
14.5在 Zig 函数之间传递 C 结构
现在我们已经学习了如何在 Zig 代码中创建/声明 C 对象,接下来我们需要学习如何将这些 C 对象作为输入传递给 Zig 函数。正如我在第 14.4 节中所述,我们可以自由地将这些 C 对象作为输入传递给从 Zig 代码调用的 C 代码。但是,如何将这些 C 对象传递给 Zig 函数呢?
本质上,这种特定情况需要在 Zig 函数声明中进行一个小的调整。您需要做的就是确保_通过引用_将 C 对象传递给函数,而不是_通过值_传递。为此,您必须将接收此 C 对象的函数参数的数据类型注释为“指向 C 结构的指针”,而不是将其注释为“C 结构的实例”。
让我们考虑一下14.4 节中使用的 C 头文件User中的C 结构体。现在,假设我们要创建一个 Zig 函数来设置此 C 结构体中字段的值,就像下面声明的函数一样。请注意,此函数中的参数被注释为指向对象的指针 ( ) 。user.hid``set_user_id()``user``*``c.User
因此,在将 C 对象传递给 Zig 函数时,只需添加*接收 C 对象的函数参数的数据类型即可。这将确保 C 对象_通过引用_传递给函数。
因为我们已经将函数参数转换为指针,所以每次在函数体中访问此输入指针指向的值时,无论出于何种原因(例如,读取、更新或删除此值),都必须使用我们第六章.*学到的语法取消引用该指针。请注意,函数正在使用此语法来更改输入指针指向的结构体字段的值。set_user_id()``id``User
const std = @import("std");
const stdout = std.io.getStdOut().writer();
const c = @cImport({
@cInclude("user.h");
});
fn set_user_id(id: u64, user: *c.User) void {
user.*.id = id;
}
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var new_user: c.User = undefined;
new_user.id = 1;
var user_name = try allocator.alloc(u8, 12);
defer allocator.free(user_name);
@memcpy(user_name[0..(user_name.len - 1)], "pedropark99");
user_name[user_name.len - 1] = 0;
new_user.name = user_name.ptr;
set_user_id(25, &new_user);
try stdout.print("New ID: {any}\n", .{new_user.id});
}
New ID: 25
15 项目 4 - 开发图像过滤器
在本章中,我们将创建一个新项目。该项目的目标是编写一个程序,对图像应用滤镜。更具体地说,是一个“灰度滤镜”,它可以将任何彩色图像转换为灰度图像。
我们将在本项目中使用图 15.1中显示的图像。换句话说,我们想使用用 Zig 编写的“图像过滤程序”将彩色图像转换为灰度图像。

图 15.1:智利裔美国演员佩德罗·帕斯卡 (Pedro Pascal) 的照片。来源:Google 图片。
我们不需要编写大量代码来构建这样的“图像滤镜程序”。但是,我们首先需要了解数字图像的工作原理。因此,本章首先会解释数字图像背后的理论以及现代计算机中颜色的表示方式。我们还会简要介绍 PNG(便携式网络图形)文件格式,这是示例图像中使用的格式。
在本章结束时,我们应该会得到一个完整的程序示例,该程序以图 15.1中显示的 PNG 图像作为输入,并将一张该输入图像的灰度版本的新图像写入当前工作目录。图 15.1 的灰度版本如图15.2 所示。 您可以在ZigExamples/image_filter 本书官方仓库的文件夹中找到这个小项目的完整源代码。

图 15.2:照片的灰度版本。
15.1我们如何看待事物?
在本节中,我想简要地向大家描述一下我们(人类)究竟是如何用眼睛看东西的。我的意思是,我们的眼睛是如何工作的?如果你对眼睛的工作原理有基本的了解,你就能更容易地理解数字图像是如何生成的。因为数字图像背后的技术,很大程度上是从人眼工作原理中汲取灵感而发展起来的。
你可以把人眼理解为一个光传感器,或者说一个光接收器。眼睛接收一定量的光作为输入,并解读这些“光量”中的颜色。如果没有任何光量进入眼睛,眼睛就无法从中提取颜色,结果就是我们什么也看不见,或者更准确地说,我们看到的是一片漆黑。
因此,一切都取决于光。我们实际看到的是光线反射后的颜色(蓝色、红色、橙色、绿色、紫色、黄色等等)。**光是所有颜色的源泉!**这正是艾萨克·牛顿在17世纪60年代著名的棱镜实验2中发现的。
我们的眼睛里有一种特殊的细胞,叫做“视锥细胞”。我们的眼睛有三种不同的类型,或者说,三种不同版本的“视锥细胞”。每种视锥细胞对特定光谱的光线非常敏感。更具体地说,是对定义红、绿、蓝三种颜色的光谱。总而言之,我们的眼睛有对这三种颜色(红、绿、蓝)高度敏感的特定类型的细胞。
这些细胞负责感知进入我们眼睛的光线中的颜色。因此,我们的眼睛感知到的颜色是这三种颜色(红、绿、蓝)的混合。通过获取一定量的这三种颜色,并将它们混合在一起,我们就能得到任何我们想要的可见颜色。因此,我们看到的每一种颜色都被感知为蓝、绿、红的特定混合,例如 30% 的红色,加上 20% 的绿色,再加上 50% 的蓝色。
当这些视锥细胞感知到(或探测到)照射到我们眼睛的光线中的颜色时,它们会产生电信号,并传送到大脑。大脑会解读这些电信号,并利用它们形成我们脑海中看到的图像。
根据我们在此讨论的内容,下面的要点描述了构成我们人类眼睛工作原理的这个非常简化版本的事件顺序:
- 光线照射到我们的眼睛。
- 视锥细胞可以感知光中的颜色。
- 视锥细胞产生电信号来描述所感知到的光的颜色。
- 电信号被发送到大脑。
- 大脑解释这些信号,并根据这些电信号识别的颜色形成图像。
15.2数字图像如何工作?
数字图像是我们用眼睛看到的图像的“数字表示”。换句话说,数字图像是我们通过光线看到和感知到的颜色的“数字表示”。在数字世界中,我们有两种类型的图像:矢量图像和光栅图像。本文不介绍矢量图像。因此,请记住,本文讨论的内容仅与光栅图像相关,与矢量图像无关。
光栅图像是一种以二维像素矩阵表示的数字图像。换句话说,每个光栅图像本质上都是一个由像素组成的矩形,每个像素都有特定的颜色。因此,光栅图像只是一个由像素组成的矩形,每个像素都以一种颜色显示在计算机屏幕(或任何其他设备,例如笔记本电脑、平板电脑、智能手机等)上。
图 15.3演示了这个想法。如果你拍摄任何光栅图像,并将其放大到最大,你会看到图像的实际像素。JPEG、TIFF 和 PNG 是常用的存储光栅图像的文件格式。
图 15.3:放大光栅图像以查看像素。来源:Google 图片。
图像像素越高,我们能包含的信息和细节就越多。图像看起来就越准确、清晰、美观。正因如此,相机通常会生成分辨率高达数百万像素的大型光栅图像,以便在最终图像中包含尽可能多的细节。例如,一张宽 1920 像素、高 1080 像素的数字图像,其包含的内容如下:1920×1080=2073600像素总数。您也可以说图像的“总面积”为 2073600 像素,尽管在计算机图形学中“面积”的概念实际上并不使用。
我们在现代世界中看到的大多数数字图像都使用 RGB 颜色模型。RGB 代表(红色、绿色和蓝色)。因此,这些光栅图像中每个像素的颜色通常表示为红色、绿色和蓝色的混合,就像我们的眼睛一样。也就是说,每个像素的颜色由一组三个不同的整数值标识。每个整数值标识每种颜色(红色、绿色和蓝色)的“数量”。例如,该集合(199, 78, 70)标识一种更接近红色的颜色。我们有 199 个红色、78 个绿色和 70 个蓝色。相反,该集合(129, 77, 250)描述的颜色更接近紫色。等等。
15.2.1图像从上到下显示
这并非一成不变的规则,但绝大多数数字图像都是从上到下、从左到右显示的。大多数电脑屏幕也遵循这种模式。因此,图像中的第一个像素位于图像的左上角。您可以在图 15.4中找到此逻辑的直观表示。
还要注意,在图 15.4中,由于光栅图像本质上是一个二维像素矩阵,因此图像被组织成像素的行和列。列由水平 x 轴定义,而行由垂直 y 轴定义。
图 15.4中显示的每个像素(即灰色矩形)内部都包含一个数字。这些数字是像素的索引。您可以注意到,第一个像素位于左上角,并且这些像素的索引“向两侧生长”,或者换句话说,它们沿着水平 x 轴方向生长。大多数光栅图像都是以像素行的形式组织的。因此,当显示这些数字图像时,屏幕会显示第一行像素,然后是第二行,然后是第三行,依此类推。

图 15.4:光栅图像的像素如何显示。
15.2.2用代码表示像素矩阵
好的,我们已经知道光栅图像表示为像素的二维矩阵。但是在 Zig 中我们没有二维矩阵的概念。实际上,大多数低级语言(Zig、C、Rust 等)都没有这样的概念。那么,我们如何在 Zig 或任何其他低级语言中表示这样的像素矩阵呢?在这种情况下,大多数程序员选择的策略是仅使用普通的一维数组来存储这个二维矩阵的值。换句话说,你只需创建一个普通的一维数组,并将两个维度的所有值存储到这个一维数组中。
举个例子,假设我们有一张尺寸为 4x3 的非常小的图像。由于光栅图像表示为二维像素矩阵,每个像素由 3 个“无符号 8 位”整数值表示,因此该图像总共有 12 个像素,分别表示为3×12=三十六整数值。因此,我们需要创建一个包含 36 个u8值的数组来存储这个小图像。
之所以u8使用无符号 8 位整数 ( ) 值(而不是任何其他整数类型)来表示每种颜色的量,是因为它们占用尽可能少的空间,或者说,占用尽可能少的位数。这有助于减小图像的二进制大小,即二维矩阵的大小。此外,即使它们只能表示相对较小范围(从 0 到 255)的“颜色量”,它们也能传达出相当高的色彩精度和细节。
回到我们最初的 4x3 图像示例,matrix下面显示的对象可以是存储表示此 4x3 图像的数据的 1D 数组的示例。
const matrix = [_]u8{
201, 10, 25, 185, 65, 70,
65, 120, 110, 65, 120, 117,
98, 95, 12, 213, 26, 88,
143, 112, 65, 97, 99, 205,
234, 105, 56, 43, 44, 216,
45, 59, 243, 211, 209, 54,
};
该数组的前三个整数值表示图像中第一个像素的颜色量。接下来的三个整数表示第二个像素的颜色量。依此类推。因此,存储光栅图像的数组大小通常是 3 的倍数。在本例中,数组的大小为 36。
我的意思是,数组的大小通常是3 的倍数,因为在特定情况下,它也可以是 4 的倍数。当光栅图像中也包含透明度时,就会发生这种情况。换句话说,有些类型的光栅图像使用不同的颜色模型,即 RGBA(红、绿、蓝和 Alpha)颜色模型。“Alpha”对应于像素的透明度。因此,RGBA 图像中的每个像素都由红、绿、蓝和 Alpha 值表示。
大多数光栅图像使用标准 RGB 模型,因此,在大多数情况下,您会看到数组大小是 3 的倍数。但有些图像(尤其是存储在 PNG 文件中的图像)可能使用 RGBA 模型,因此,由大小为 4 的倍数的数组表示。
在本例中,我们项目的示例图像(图 15.1)是存储在 PNG 文件中的光栅图像,并且该特定图像使用 RGBA 颜色模型。因此,图像中的每个像素都由 4 个不同的整数值表示,因此,为了将此图像存储在我们的 Zig 代码中,我们需要创建一个大小为 4 的倍数的数组。
15.3我们将要使用的 PNG 库
让我们从编写必要的 Zig 代码来读取 PNG 文件中的数据开始我们的项目。换句话说,我们要读取图 15.1中显示的 PNG 文件,并解析其数据以提取表示图像的二维像素矩阵。
正如我们在15.2.2 节中讨论过的,我们在此用作示例的图像是一个使用 RGBA 颜色模型的 PNG 文件,因此,图像的每个像素由 4 个整数值表示。您可以通过访问ZigExamples/image_filter 本书官方仓库3中的文件夹下载此图像。您还可以在此文件夹中找到我们正在开发的这个小项目的完整源代码。
有一些 C 库可以用来读取和解析 PNG 文件。其中最著名、最常用的是libpng,它是读取和写入 PNG 文件的“官方库”。虽然这个库在大多数操作系统上都可用,但它以复杂且难以使用而闻名。
这就是为什么我将在这个项目中使用一个更现代的替代方案,即libspng库。我选择使用这个 C 库,因为它比 更易于使用libpng,并且所有操作都具有非常出色的性能。您可以访问库4的官方网站了解更多信息。您还可以在那里找到一些文档,它们可能有助于您理解和遵循此处提供的代码示例。
首先,请记住将其构建并安装libspng到您的系统中。因为如果您不执行此步骤,编译器将无法在您的计算机中找到此库的文件和资源,并将它们与我们在此共同编写的 Zig 源代码链接起来。库文档5zig的构建部分提供了有关如何构建和安装该库的详细说明。
15.4读取PNG文件
为了从 PNG 文件中提取像素数据,我们需要读取并解码该文件。PNG 文件只是以“PNG 格式”写入的二进制文件。幸运的是,该libspng库提供了一个名为 的函数spng_decode_image(),可以为我们完成所有这些繁重的工作。
现在,由于libspng这是一个 C 库,库中的大部分文件和 I/O 操作都是通过FILEC 指针进行的。因此,使用fopen()C 函数打开 PNG 文件可能比使用openFile()我在第 13 章中介绍的方法更好。这就是为什么我stdio.h在这个项目中导入了 C 头文件,并使用fopen()C 函数打开文件。
如果你看一下下面的代码片段,你就会发现我们是:
- 使用 打开 PNG 文件
fopen()。 - 创建
libspng上下文spng_ctx_new()。 - 用于
spng_set_png_file()指定FILE读取我们将要使用的 PNG 文件的对象。
中的每个操作libspng都是通过“上下文对象”进行的。在下面的代码片段中,这个对象是ctx。此外,要对 PNG 文件执行操作,我们需要指定要引用的具体 PNG 文件。这就是 的工作spng_set_png_file()。我们使用此函数来指定读取我们要使用的 PNG 文件的文件描述符对象。
const c = @cImport({
@cDefine("_NO_CRT_STDIO_INLINE", "1");
@cInclude("stdio.h");
@cInclude("spng.h");
});
const path = "pedro_pascal.png";
const file_descriptor = c.fopen(path, "rb");
if (file_descriptor == null) {
@panic("Could not open file!");
}
const ctx = c.spng_ctx_new(0) orelse unreachable;
_ = c.spng_set_png_file(
ctx, @ptrCast(file_descriptor)
);
在继续之前,需要强调的是:由于我们已经使用 打开了文件fopen(),因此我们必须记住在程序结束时使用 关闭文件fclose()。换句话说,在对 PNG 文件执行完所有操作后,我们需要通过应用文件描述符对象pedro_pascal.png来关闭该文件。如果需要,我们也可以使用 关键字来完成这项任务。下面的代码片段演示了这一步骤:fclose()``defer
if (c.fclose(file_descriptor) != 0) {
return error.CouldNotCloseFileDescriptor;
}
15.4.1读取图像头部分
现在,上下文对象ctx已经知道了我们的 PNG 文件pedro_pascal.png,因为它可以访问该文件的文件描述符对象。我们要做的第一件事是读取 PNG 文件的“图像头部分”。这个“图像头部分”包含 PNG 文件的一些基本信息,例如,图像像素数据的位深度、文件使用的颜色模型、图像的尺寸(以像素数表示的高度和宽度)等等。
为了简化操作,我将把这个“读取图像头”操作封装成一个名为 的小巧函数get_image_header()。该函数只需调用 即可spng_get_ihdr()。该函数libspng负责读取图像头数据,并将其存储到名为 的 C 结构体中spng_ihdr。因此, 类型的对象spng_ihdr是一个 C 结构体,它包含 PNG 文件图像头部分的数据。
由于此 Zig 函数接收 C 对象(libspng上下文对象)作为输入,因此我将函数参数标记ctx为“指向上下文对象的指针”( ),遵循我们在第 14.5 节*c.spng_ctx中讨论的建议。
fn get_image_header(ctx: *c.spng_ctx) !c.spng_ihdr {
var image_header: c.spng_ihdr = undefined;
if (c.spng_get_ihdr(ctx, &image_header) != 0) {
return error.CouldNotGetImageHeader;
}
return image_header;
}
var image_header = try get_image_header(ctx);
还要注意,在这个函数中,我检查了spng_get_ihdr()函数调用是否返回了一个非零的整数值。libspng库中的大多数函数都会返回一个代码状态,而代码状态“零”表示“成功”。因此,任何非零的代码状态都表示运行时发生了错误spng_get_ihdr()。这就是为什么我会在函数返回的代码状态非零时返回一个错误值。
15.4.2为像素数据分配空间
在从 PNG 文件中读取像素数据之前,我们需要分配足够的空间来保存这些数据。但为了分配这样的空间,我们首先需要知道需要分配多少空间。显然,需要图像的尺寸来计算这个空间的大小。但还有其他因素也会影响这个数字,例如图像中使用的颜色模型、位深度等等。
无论如何,所有这些都意味着计算我们所需的空间大小并非易事。因此,libspng库提供了一个名为 的工具函数spng_decoded_image_size()来帮助我们计算这个大小。再次强调,我将把这个 C 函数的逻辑封装成一个简洁精巧的 Zig 函数,名为calc_output_size()。您可以在下面看到,该函数返回一个整数值作为结果,告知我们需要分配的空间大小。
fn calc_output_size(ctx: *c.spng_ctx) !u64 {
var output_size: u64 = 0;
const status = c.spng_decoded_image_size(
ctx, c.SPNG_FMT_RGBA8, &output_size
);
if (status != 0) {
return error.CouldNotCalcOutputSize;
}
return output_size;
}
你可能会好奇这个值SPNG_FMT_RGBA8的含义。这个值实际上是spng.hC 头文件中定义的一个枚举值。这个枚举值用于标识一种“PNG 格式”。更准确地说,它标识一个使用 RGBA 颜色模型和 8 位深度的 PNG 文件。因此,通过将此枚举值作为函数的输入spng_decoded_image_size(),我们告诉该函数,以遵循“8 位深度的 RGBA 颜色模型”格式的 PNG 文件为例,计算解码后像素数据的大小。
有了这个函数,我们可以将它与分配器对象结合使用,分配一个u8足够大的字节数组(值),用于存储图像解码后的像素数据。注意,我使用这个函数@memset()将整个数组初始化为零。
const output_size = try calc_output_size(ctx);
var buffer = try allocator.alloc(u8, output_size);
@memset(buffer[0..], 0);
15.4.3解码图像数据
现在我们有了存储图像解码像素数据所需的空间,我们可以开始使用spng_decode_image()C 函数实际解码并从图像中提取像素数据。
下面展示的 Zig函数read_data_to_buffer()总结了读取解码像素数据并将其存储到输入缓冲区的必要步骤。请注意,此函数封装了函数本身的逻辑spng_decode_image()。此外,我们再次使用SPNG_FMT_RGBA8枚举值来告知相应的函数,正在解码的 PNG 图像使用 RGBA 颜色模型和 8 位深度。
fn read_data_to_buffer(ctx: *c.spng_ctx, buffer: []u8) !void {
const status = c.spng_decode_image(
ctx,
buffer.ptr,
buffer.len,
c.SPNG_FMT_RGBA8,
0
);
if (status != 0) {
return error.CouldNotDecodeImage;
}
}
有了这个函数,我们可以将它应用于我们的上下文对象,也可以应用于我们在上一节中分配的缓冲区对象,以保存图像的解码像素数据:
try read_data_to_buffer(ctx, buffer[0..]);
15.4.4查看像素数据
现在我们已经将像素数据存储在“缓冲区对象”中,我们可以快速查看一下这些字节。在下面的示例中,我们查看的是解码像素数据中的前 12 个字节。
如果仔细观察这些值,你可能会注意到序列中每 4 个字节都是 255。巧合的是,这正是一个值所能表示的最大整数值u8。因此,如果 0 到 255(也就是一个值所能表示的整数值范围)u8可以表示为 0% 到 100% 的比例,那么这 255 个值在这个比例下本质上就是 100%。
如果你还记得15.2.2 节的内容,我在那一节中提到过,我们的pedro_pascal.pngPNG 文件使用 RGBA 颜色模型,它会为图像中的每个像素添加一个 Alpha(透明度)字节。因此,图像中的每个像素都由 4 个字节表示。由于我们在这里查看的是图像的前 12 个字节,这意味着我们查看的是第一个12/4=3图像中的像素。
因此,根据前 12 个字节(或 3 个像素)的情况,以及每 4 个字节对应 255 个值,我们可以说图像中的每个像素很可能都将 Alpha 值(或透明度)设置为 100%。这或许并非事实,但却是最有可能的。此外,如果我们查看图像本身(如果您还记得的话,它显示在图 15.1中),我们可以看到整个图像的透明度并没有发生变化,这进一步证实了这一理论。
try stdout.print("{any}\n", .{buffer[0..12]});
{
200, 194, 216, 255, 203, 197,
219, 255, 206, 200, 223, 255
}
从上面的结果中我们可以看到,图像中的第一个像素有 200 个红色像素、194 个绿色像素和 216 个蓝色像素。我如何知道这些颜色在序列中的出现顺序呢?如果你还没猜到,那是因为 RGB 这个缩写。首先是红色,然后是绿色,最后是蓝色。如果我们按照 0% 到 100%(0 到 255)的比例缩放这些整数值,我们会得到 78% 的红色、76% 的绿色和 85% 的蓝色。
15.5应用图像滤镜
现在我们有了图像中每个像素的数据,我们可以专注于对这些像素应用图像滤镜了。记住,我们的目标是对图像应用灰度滤镜。灰度滤镜是一种将彩色图像转换为灰度图像的滤镜。
将彩色图像转换为灰度图像有多种公式和策略。但所有这些不同的策略通常都涉及对每个像素的颜色进行一些数学运算。在本项目中,我们将使用最通用的公式,如下所示。该公式考虑了r作为像素的红色,克作为绿色,b蓝色,页′作为像素的线性亮度。
(15.1)页′=(0.2126×r)+(0.7152×克)+(0.0722×b)
公式15.1是计算像素线性亮度的公式。值得注意的是,此公式仅适用于像素使用 sRGB 颜色空间(这是 Web 的标准颜色空间)的图像。因此,理想情况下,Web 上的所有图像都应使用此颜色空间。幸运的是,我们这里的情况就是这样,即图像使用的是 sRGB 颜色空间,因此 pedro_pascal.png,我们可以使用公式 15.1 。您可以在维基百科的灰度页面( Wikipedia 2024 )上阅读有关此公式的更多信息。
下面展示的函数总结了将公式 15.1应用于图像像素的apply_image_filter()必要步骤。我们只需将此函数应用于包含像素数据的缓冲区对象,结果,存储在此缓冲区对象中的像素数据现在应该代表图像的灰度版本。
fn apply_image_filter(buffer:[]u8) !void {
const len = buffer.len;
const red_factor: f16 = 0.2126;
const green_factor: f16 = 0.7152;
const blue_factor: f16 = 0.0722;
var index: u64 = 0;
while (index < len) : (index += 4) {
const rf: f16 = @floatFromInt(buffer[index]);
const gf: f16 = @floatFromInt(buffer[index + 1]);
const bf: f16 = @floatFromInt(buffer[index + 2]);
const y_linear: f16 = (
(rf * red_factor) + (gf * green_factor)
+ (bf * blue_factor)
);
buffer[index] = @intFromFloat(y_linear);
buffer[index + 1] = @intFromFloat(y_linear);
buffer[index + 2] = @intFromFloat(y_linear);
}
}
try apply_image_filter(buffer[0..]);
15.6保存图像的灰度版本
由于我们现在已将图像的灰度版本存储在缓冲区对象中,因此我们需要将此缓冲区对象重新编码为“PNG 格式”,并将编码数据保存到文件系统中的新 PNG 文件中,以便我们可以访问并查看由我们的小程序生成的图像的灰度版本。
为此,libspng库再次提供了一个“将数据编码为 PNG”类型的函数,即spng_encode_image()函数。但是,为了使用 函数“将数据编码为 PNG” libspng,我们需要创建一个新的上下文对象。这个新的上下文对象必须使用一个“编码器上下文”,该上下文由枚举值 标识SPNG_CTX_ENCODER。
下面展示的函数save_png()总结了将图像的灰度版本保存到文件系统中新的 PNG 文件的所有必要步骤。默认情况下,此函数会将灰度图像保存到pedro_pascal_filter.pngCWD 中指定的文件中。
image_header请注意,在此代码示例中,我们使用了之前通过函数获取的图像头对象 ( ) get_image_header()。记住,这个图像头对象是一个 C 结构体 ( spng_ihdr),它包含 PNG 文件的基本信息,例如图像尺寸、使用的颜色模型等。
如果我们想在这个新的 PNG 文件中保存一个非常不同的图像,例如具有不同尺寸的图像,或者使用不同颜色模型、不同位深度等的图像,我们必须创建一个新的图像头(spng_ihdr)对象来描述这个新图像的属性。
但我们本质上保存的是与最初保存的图像相同的图像(图像尺寸、颜色模型等都保持不变)。两幅图像唯一的区别在于像素的颜色,现在变成了“灰度”。因此,我们可以安全地在这个新的 PNG 文件中使用完全相同的图像头数据。
fn save_png(image_header: *c.spng_ihdr, buffer: []u8) !void {
const path = "pedro_pascal_filter.png";
const file_descriptor = c.fopen(path.ptr, "wb");
if (file_descriptor == null) {
return error.CouldNotOpenFile;
}
const ctx = (
c.spng_ctx_new(c.SPNG_CTX_ENCODER)
orelse unreachable
);
defer c.spng_ctx_free(ctx);
_ = c.spng_set_png_file(ctx, @ptrCast(file_descriptor));
_ = c.spng_set_ihdr(ctx, image_header);
const encode_status = c.spng_encode_image(
ctx,
buffer.ptr,
buffer.len,
c.SPNG_FMT_PNG,
c.SPNG_ENCODE_FINALIZE
);
if (encode_status != 0) {
return error.CouldNotEncodeImage;
}
if (c.fclose(file_descriptor) != 0) {
return error.CouldNotCloseFileDescriptor;
}
}
try save_png(&image_header, buffer[0..]);
执行此save_png()函数后,我们的 CWD 中应该会有一个名为 的新 PNG 文件pedro_pascal_filter.png。打开这个 PNG 文件,我们将看到与图 15.2中相同的图像。
15.7构建我们的项目
现在我们已经编写了代码,让我们讨论一下如何构建/编译这个项目。为此,我将在项目的根目录中创建一个文件,并开始编写编译项目所需的代码,使用我们从第 9 章build.zig学到的知识。
我们首先为可执行文件创建构建目标,用于执行我们的 Zig 代码。假设我们所有的 Zig 代码都写入了一个名为 的 Zig 模块中image_filter.zig。exe下面构建脚本中公开的对象描述了我们可执行文件的构建目标。
由于我们在 Zig 代码中使用了libspng库中的一些 C 代码,因此我们需要将 Zig 代码(位于exe构建目标中)链接到 C 标准库和库libspng。我们通过调用构建目标中的linkLibC()和linkSystemLibrary()方法来实现这一点exe。
const std = @import("std");
pub fn build(b: *std.Build) void {
const target = b.standardTargetOptions(.{});
const optimize = b.standardOptimizeOption(.{});
const exe = b.addExecutable(.{
.name = "image_filter",
.root_source_file = b.path("src/image_filter.zig"),
.target = target,
.optimize = optimize,
});
exe.linkLibC();
// Link to libspng library:
exe.linkSystemLibrary("spng");
b.installArtifact(exe);
}
由于我们使用的是该方法,这意味着系统会搜索linkSystemLibrary()库文件并将其链接到构建目标。如果您尚未构建并安装该库到您的系统中,则此链接步骤可能无法正常工作。因为它无法在您的系统中找到库文件。libspng``exe``libspng
libspng所以,如果你想构建这个项目,只需记住在你的系统中安装即可。有了上面编写的构建脚本,我们最终可以通过zig build在终端中运行命令来构建我们的项目。
zig build
-
https://github.com/pedropark99/zig-book/tree/main/ZigExamples/image_filter ↩︎
-
https://library.si.edu/exhibition/color-in-a-new-light/science ↩︎
-
https://github.com/pedropark99/zig-book/tree/main/ZigExamples/image_filter ↩︎
16 Zig 中的线程和并行性介绍
在 Zig 中,线程可以通过ThreadZig 标准库中的结构体使用。该结构体代表一个内核线程,它遵循 POSIX 线程模式,这意味着它的工作方式类似于pthreadC 库中的线程,该线程通常在 GNU C 编译器 ( gcc) 的任何发行版中可用。如果您不熟悉线程,我先给您讲解一下它背后的理论,好吗?
16.1什么是线程?
线程本质上是一个独立的执行上下文。我们使用线程为程序引入并行性,在大多数情况下,这可以提高程序的运行速度,因为我们有多个任务同时并行执行。
程序通常默认是单线程的。这意味着每个程序通常运行在单个线程或单个执行上下文中。当只有一个线程运行时,就没有并行性。当没有并行性时,命令将按顺序执行,也就是说,一次只执行一个命令,一个接一个。通过在程序中创建多个线程,我们可以同时执行多个命令。
创建多线程的程序在现实世界中非常常见。因为许多不同类型的应用程序都非常适合并行执行。视频和照片编辑应用程序(例如 Adobe Photoshop 或 DaVinci Resolve)、游戏(例如《巫师 3》)以及 Web 浏览器(例如 Google Chrome、Firefox、Microsoft Edge 等)都是很好的例子。例如,在 Web 浏览器中,线程通常用于实现标签页。Web 浏览器中的标签页通常在 Web 浏览器的主进程中作为单独的线程运行。也就是说,您在 Web 浏览器中打开的每个新标签页通常在单独的执行线程中运行。
通过在单独的线程中运行每个标签页,我们允许浏览器中所有打开的标签页同时运行,并且彼此独立。例如,您可能当前在某个标签页中打开了 YouTube 或 Spotify,并且正在该标签页中收听播客,同时在另一个标签页中处理 Google 文档撰写论文。即使您没有查看 YouTube 标签页,您仍然可以收听播客,因为这个 YouTube 标签页与正在运行 Google 文档的另一个标签页并行运行。
如果没有线程,另一种选择是将每个标签页作为计算机上完全独立的进程运行。但这不是一个好选择,因为仅仅几个标签页就已经消耗了太多的计算机电量和资源。换句话说,与创建一个新的执行线程相比,创建一个全新的进程非常昂贵。此外,在使用浏览器时遇到延迟和开销的可能性也会很大。线程创建速度更快,而且它们消耗的计算机资源也少得多,尤其是因为它们与主进程共享一些资源。
因此,现代网络浏览器之所以能使用线程功能,是因为它允许你在 Google 文档上撰写文章的同时收听播客。如果没有线程功能,网络浏览器很可能只会显示一个标签页。
线程也非常适合处理任何涉及处理请求或订单的操作。因为处理请求需要时间,而且通常涉及大量的“等待时间”。换句话说,我们会花费大量时间处于空闲状态,等待某件事完成。例如,考虑一家餐厅。餐厅处理订单通常涉及以下步骤:
- 接收客户的订单。
- 将订单传递给厨房,然后等待食物烹制。
- 开始在厨房做饭。
- 当食物完全煮熟后,将食物交给客户。
如果你仔细思考以上几点,就会发现整个过程中有一个重要的等待时刻,那就是食物在厨房烹饪的时候。在准备食物的过程中,服务员和顾客都在等待食物准备好并送达。
如果我们编写一个程序来代表这家餐厅,更具体地说,一个单线程程序,那么这个程序的效率会非常低。因为程序会处于空闲状态,在“检查食物是否准备好”这一步骤上等待相当长的时间。请考虑下面展示的代码片段,它可能代表这样的程序。
这个程序的问题在于while循环。程序会花费大量时间等待while循环,除了检查食物是否准备好之外什么也不做。这太浪费时间了。与其等待某个事情发生,服务员可以直接把订单发送到厨房,然后继续处理其他顾客的订单,并继续向厨房发送订单,而不是什么也不做,等着食物准备好。
const order = Order.init("Pizza Margherita", n = 1);
const waiter = Waiter.init();
waiter.receive_order(order);
waiter.ask_kitchen_to_cook();
var food_not_ready = true;
while (food_not_ready) {
food_not_ready = waiter.is_food_ready();
}
const food = waiter.get_food_from_kitchen();
waiter.send_food_to_client(food);
这就是为什么线程非常适合这个程序。我们可以用线程把服务员从“等待”的职责中解放出来,让他们可以继续做其他事情,并接收更多订单。请看下一个示例,我将上面的程序重写成了一个不同的程序,使用线程来烹饪和配送订单。
您可以在这段程序中看到,当服务员收到顾客的新订单时,他会执行该send_order()函数。该函数唯一要做的就是创建一个新线程并将其分离。由于创建线程是一个非常快的操作,该send_order()函数几乎立即返回,因此服务员几乎不用花时间处理订单,而是继续尝试从顾客那里获取下一个订单。
在新创建的线程中,订单由厨师烹饪,食物准备好后,送到客户的餐桌上。
fn cook_and_deliver_order(order: *Order) void {
const chef = Chef.init();
const food = chef.cook(order.*);
chef.deliver_food(food);
}
fn send_order(order: Order) void {
const cook_thread = Thread.spawn(
.{}, cook_and_deliver_order, .{&order}
);
cook_thread.detach();
}
const waiter = Waiter.init();
while (true) {
const order = waiter.get_new_order();
if (order) {
send_order(order);
}
}
16.2线程与进程
_当我们运行一个程序时,该程序在操作系统中作为一个进程_执行。这是一种一对一的关系,您执行的每个程序或应用程序在操作系统中都是一个单独的进程。但是每个程序或每个进程都可以创建并包含多个线程。因此,进程和线程之间存在一对多的关系。
这也意味着我们创建的每个线程始终与计算机中的特定进程相关联。换句话说,线程始终是现有进程的子集(或子进程)。所有线程都共享与其创建源进程关联的部分资源。由于线程与进程共享资源,因此它们非常适合简化任务之间的通信。
例如,假设你正在开发一个庞大而复杂的应用程序,如果能将其拆分成两个部分,并使这两个独立的部分相互通信,开发起来就会简单得多。有些程序员选择将代码库的这两个部分有效地编写成两个完全独立的程序,然后使用 IPC(进程间通信)使这两个独立的程序/进程相互通信,并使它们协同工作。
然而,一些程序员发现 IPC 难以处理,因此,他们倾向于将代码库的一部分编写为“程序的主体部分”,或者作为在操作系统中以进程形式运行的代码部分,而将代码库的另一部分编写为在新线程中执行的任务。进程和线程可以通过控制流以及数据轻松地相互通信,因为它们共享并可以访问相同的标准文件描述符(stdout、stdin、stderr),以及堆和全局数据段上的相同内存空间。
更详细地说,您创建的每个线程都有一个专门为该线程保留的单独堆栈帧,这实际上意味着您在此线程内创建的每个本地对象都只对该线程有效,即其他线程无法访问此本地对象。除非您创建的这个对象位于堆上。换句话说,如果与此对象关联的内存位于堆上,那么其他线程就有可能访问此对象。
因此,存储在栈中的对象对于创建它们的线程来说是本地的。但存储在堆中的对象可能被其他线程访问。所有这些意味着,每个线程都有自己独立的栈帧,但同时,所有线程共享同一个堆、相同的标准文件描述符(这意味着它们共享相同的stdout、stdin、stderr)以及程序中的同一个全局数据段。
16.3创建线程
我们在 Zig 中创建新线程,首先将Thread结构体导入到当前的 Zig 模块中,然后调用spawn()该结构体的方法,该方法从当前进程创建(或“生成”)一个新的执行线程。此方法有三个参数,分别为:
- 一个
SpawnConfig对象,其中包含生成过程的配置。 - 在这个新线程中将要执行(或将要“调用”)的函数的名称。
- 传递给第二个参数中提供的函数的参数(或输入)列表。
通过这三个参数,你可以控制线程的创建方式,并指定将在此新线程中执行哪些工作(或“任务”)。线程只是一个独立的执行上下文,我们通常在代码中创建新线程,因为我们想在这个新的执行上下文中执行一些工作。我们通过提供函数名称作为方法的第二个参数来指定在此上下文中要执行的具体工作或步骤spawn()。
因此,当这个新线程创建时,您提供给该spawn()方法作为输入的函数将被调用,或者说,在这个新线程内执行。您可以通过在方法的第三个参数中提供参数列表(或输入列表)来控制调用此函数时传递给它的参数或输入spawn()。这些参数将按照提供给函数的顺序传递给函数spawn()。
此外,它SpawnConfig是一个结构体对象,只有两个可能的字段(或者说两个可能的成员),您可以设置它们来定制生成行为。这些字段是:
stack_size:您可以提供一个usize值来指定线程堆栈框架的大小(以字节为单位)。默认情况下,此值为:16×1024×1024。allocator:您可以提供一个分配器对象,用于为线程分配内存时使用。
要使用这两个字段(或“配置”)之一,您只需创建一个新的 类型的对象SpawnConfig,并将该对象作为spawn()方法的输入。但是,如果您不想使用其中一个配置,而只想使用默认值,则可以提供一个匿名结构体字面量 ( .{}) 来代替此SpawnConfig参数。
作为我们的第一个非常简单的示例,请考虑下面公开的代码。在同一个程序中,您可以根据需要创建多个执行线程。但是,在第一个示例中,我们只创建了一个执行线程,因为我们spawn()只调用了一次。
另外,请注意,在这个例子中,我们在新线程中执行该函数do_some_work()。由于该函数没有参数,因此不接收任何输入,因此我们在此实例中传递了一个空列表,或者更准确地说,.{}在 的第三个参数中传递了一个空的匿名结构体 ( ) spawn()。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
const Thread = std.Thread;
fn do_some_work() !void {
_ = try stdout.write("Starting the work.\n");
std.time.sleep(100 * std.time.ns_per_ms);
_ = try stdout.write("Finishing the work.\n");
}
pub fn main() !void {
const thread = try Thread.spawn(.{}, do_some_work, .{});
thread.join();
}
Starting the work.Finishing the work.
注意调用try该方法时使用的spawn()。这意味着该方法在某些情况下可能会返回错误。一种特殊情况是,当您尝试创建新线程时,如果已经创建了过多的线程(即超出了系统并发线程的配额)。
但是,如果新线程成功创建,该spawn()方法会返回一个处理程序对象(类型为 的对象Thread)。您可以使用这个处理程序对象有效地控制线程的各个方面。
当线程创建时,您提供的输入函数spawn()将被调用(即,被调用),以启动此新线程的执行。换句话说,每次调用 时spawn(),不仅会创建一个新线程,还会自动按下此线程的“启动工作按钮”。因此,此线程中正在执行的工作会在线程创建后立即开始。这类似于 C 语言库的工作方式pthread_create(),pthreads它也会在线程创建后立即开始执行。
16.4从线程返回
我们在上一节中了解到,线程一旦创建就开始执行。现在,我们将学习如何在 Zig 中“加入”或“分离”线程。“加入”和“分离”是控制线程如何返回主线程或程序中的主进程的操作。
我们使用线程处理程序对象中的方法join()和执行这些操作。您创建的每个线程都可以标记为可_连接 (joinable)或_可分离 (detached) (Linux 手册页 2024) 。您可以通过调用线程处理程序对象中的方法将线程转换为_分离_线程。但是,如果您调用该方法,则该线程将变为_可连接_线程。detach() detach()``join()
一个线程不能同时是_可连接 (joinable)和_可分离 (detached) 的。通常,这意味着你不能在同一个线程中同时调用join()和detach()。但一个线程必须是两者之一,这意味着你应该始终在线程上调用join()或。如果你不在线程上调用这两个方法中的任何一个,则会在程序中引入未定义的行为,这将在16.9.2 节detach()中描述。
现在,让我们描述一下这两种方法对您的线程的作用。
16.4.1加入线程
当你加入一个线程时,你实际上是在说:“嘿!你能等线程完成后再继续执行吗?” 例如,如果我们回到 Zig 中第一个也是最简单的线程示例,我们在main()程序的函数内部创建了一个单线程,并join()在最后调用了这个线程。代码示例的这一部分如下所示。
因为我们是在 的作用域内加入这个新线程的main(),所以main()函数的执行会暂时停止,等待线程执行完成。也就是说, 的执行会main()在 被调用的那一行暂时停止join(),只有在线程完成其任务后才会继续。
pub fn main() !void {
const thread = try Thread.spawn(.{}, do_some_work, .{});
thread.join();
}
因为我们已经将这个新线程加入到main()作用域内,所以我们可以保证这个新线程将在执行结束之前完成main()。因为它保证main()会等待线程完成其任务。
在上面的例子中,调用之后没有其他表达式join()。我们刚好到达了 的作用域的末尾main(),因此,我们的程序的执行在线程完成其任务后就结束了,因为没有其他事情要做了。但是,如果我们在 join 调用之后还有更多事情要做呢?
为了演示这种可能性,请考虑下面展示的示例。在这里,我们创建一个print_id()函数,它只接收一个 id 作为输入,并将其打印到stdout。在这个例子中,我们依次创建了两个新线程。然后,我们加入第一个线程,然后等待整整两秒,最后加入第二个线程。
此示例背后的理念是,最后一个join()调用仅在第一个线程完成其任务(即第一次join()调用)并经过两秒延迟后执行。如果您编译并运行此示例,您会注意到大多数消息都快速打印到stdout,即它们几乎立即出现在屏幕上。然而,最后一条消息(“加入线程 2”)大约需要 2 秒才能显示在屏幕上。
fn print_id(id: *const u8) !void {
try stdout.print("Thread ID: {d}\n", .{id.*});
}
pub fn main() !void {
const id1: u8 = 1;
const id2: u8 = 2;
const thread1 = try Thread.spawn(.{}, print_id, .{&id1});
const thread2 = try Thread.spawn(.{}, print_id, .{&id2});
_ = try stdout.write("Joining thread 1\n");
thread1.join();
std.time.sleep(2 * std.time.ns_per_s);
_ = try stdout.write("Joining thread 2\n");
thread2.join();
}
Thread ID: Joining thread 1
1
Thread ID: 2
Joining thread 2
这表明两个线程都非常快地完成了它们的工作(即打印 ID),在两秒的延迟结束之前。因此,最后一个join()调用几乎立即返回。因为当最后一个join()调用发生时,第二个线程已经完成了它的任务。
现在,如果你编译并运行此示例,你还会注意到,在某些情况下,消息会相互缠绕。换句话说,你可能会看到消息“加入线程 1”插入到消息“线程 1”的中间,反之亦然。发生这种情况的原因是:
main()线程基本上和程序的主进程(即函数)同时执行。- 线程
stdout与程序的主进程共享相同的消息,这意味着线程产生的消息被发送到与主进程产生的消息完全相同的地方。
这两点在之前的16.1 节中都有描述。因此,由于消息的生成和发送时间stdout大致相同,它们可能会相互缠绕。总之,当你调用join()一个线程时,当前进程会等待该线程完成后才能继续执行;并且,当该线程完成其任务后,与该线程关联的资源会自动释放,当前进程将继续执行。
16.4.2分离线程
当您分离一个线程时,与该线程关联的资源将自动释放回系统,而无需另一个线程加入该终止的线程。
换句话说,当你调用detach()一个线程时,就像你的孩子长大成人,也就是说,他们不再依赖你。分离线程会释放自身,并且当该线程完成其任务时,它不会将结果报告给你。因此,当你不需要使用线程的返回值,或者你不关心线程何时完成其工作(即线程自行解决所有问题)时,通常将线程标记为_分离线程。_
以下面的代码示例为例。我们创建一个新线程,然后将其分离,最后在程序结束前打印一条消息。我们使用了print_id()前面示例中用过的相同函数。
fn print_id(id: *const u8) !void {
try stdout.print("Thread ID: {d}\n", .{id.*});
}
pub fn main() !void {
const id1: u8 = 1;
const thread1 = try Thread.spawn(.{}, print_id, .{&id1});
thread1.detach();
_ = try stdout.write("Finish main\n");
}
Finish main
现在,如果你仔细观察这段代码示例的输出,你会发现只有 main 函数中的最后一条消息被打印到了控制台。原本应该打印的消息print_id()并没有出现在控制台中。为什么?这是因为程序的主进程在线程能够发出任何指令之前就先完成了。
这完全没问题,因为线程已经分离,所以它可以自行释放,而无需等待主进程。如果你让主进程在结束前休眠(或“等待”)几纳秒,你很可能会看到打印的消息print_id(),因为你在主进程结束前为线程提供了足够的时间来完成。
16.5线程池
线程池是一种非常流行的编程模式,尤其适用于服务器和守护进程。线程池只是一组线程,或者说是一个线程“池”。许多程序员喜欢使用这种模式,因为它可以更轻松地管理和使用程序中的多个线程,而无需在需要时手动创建线程。
此外,使用线程池也可能提升程序的性能,尤其是在程序需要不断创建线程执行短期任务的情况下。在这种情况下,线程池可能会提升性能,因为您不必一直不断地创建和销毁线程,从而避免了这种持续创建和销毁线程所带来的大量开销。
线程池的核心思想是预先创建一组线程,并随时准备执行任务。在程序启动时创建一组线程,并在程序运行时保持这些线程处于活动状态。每个线程要么正在执行任务,要么等待分配任务。每当程序中出现新任务时,该任务就会被添加到“任务队列”中。当某个线程可用并准备好执行新任务时,该线程就会从“任务队列”中获取下一个任务,并直接执行该任务。
Zig 标准库提供了基于结构体的线程池实现。您可以通过将对象作为输入提供给此结构体的方法,std.Thread.Pool来创建对象的新实例。对象 是一个包含线程池配置的结构体对象。此结构体对象中最重要的设置是成员和。顾名思义,成员应该接收一个分配器对象,而成员指定要在此池中创建和维护的线程数。Pool``Pool.Options``init()``Pool.Options``n_jobs``allocator``allocator``n_jobs
考虑下面展示的示例,它演示了如何创建一个新的线程池对象。在这里,我们创建一个Pool.Options包含通用分配器对象的对象,并且其n_jobs成员设置为 4,这意味着线程池将创建并使用 4 个线程。
另请注意,pool对象初始设置为undefined。这允许我们初始声明线程池对象,但无法正确实例化对象的底层内存。您必须undefined像这样使用 初始声明线程池对象,因为init()的方法Pool需要初始指针才能正确实例化对象。
因此,只需记住使用 创建线程池对象undefined,然后在该对象上调用 方法即可。使用完毕后,init()也不要忘记调用线程池对象的 方法来释放分配给线程池的资源。否则,程序将出现内存泄漏。deinit()
const std = @import("std");
const Pool = std.Thread.Pool;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
const opt = Pool.Options{
.n_jobs = 4,
.allocator = allocator,
};
var pool: Pool = undefined;
try pool.init(opt);
defer pool.deinit();
}
现在我们知道了如何创建Pool对象,接下来我们必须了解如何分配任务给线程池对象中的线程执行。要分配一个任务给线程执行,我们需要调用spawn()线程池对象中的方法。
此方法的工作原理与对象中的方法spawn()相同。该方法的参数与前一个方法几乎相同,更确切地说,在这种情况下我们无需提供对象。但是,线程池对象中的此方法不会创建新线程,而是仅在内部“任务队列”中注册一个待执行的新任务,池中任何可用的线程都会获取此任务并直接执行。spawn()``Thread``SpawnConfig``spawn()
在下面的示例中,我们print_id()再次使用了之前的函数。但您可能会注意到,print_id()这次的函数略有不同,因为我们在调用时使用了catch而不是。目前,该结构体仅支持不会将错误作为任务返回的函数。因此,在将任务分配给线程池中的线程时,必须使用不会返回错误的函数。这就是我们在这里使用 的原因,这样函数就不会返回错误。try``print()``Pool``catch``print_id()
fn print_id(id: *const u8) void {
_ = stdout.print("Thread ID: {d}\n", .{id.*})
catch void;
}
const id1: u8 = 1;
const id2: u8 = 2;
try pool.spawn(print_id, .{&id1});
try pool.spawn(print_id, .{&id2});
这种限制可能不应该存在,事实上,Zig 团队已经在考虑解决这个问题,并且正在一个未解决的问题1中进行跟踪。因此,如果您确实需要提供一个可能返回错误的函数作为线程池中线程要执行的任务,那么您要么只能这样做:
- 实现自己的没有此限制的线程池。
- 等待 Zig 团队真正解决这个问题。
16.6互斥锁
互斥锁是每个线程库的经典组件。本质上,互斥锁是一个_互斥标志_,它的作用类似于一种“锁”,或者说是代码特定部分的守门人。互斥锁与线程同步相关,更具体地说,它们可以防止程序中出现一些典型的竞争条件,从而避免通常难以跟踪和理解的重大错误和未定义行为。
互斥锁的核心思想是帮助我们控制特定代码段的执行,并防止两个或多个线程同时执行这一段代码。许多程序员喜欢将互斥锁比作浴室的门(通常带有锁)。当一个线程锁定自己的互斥锁对象时,就好像浴室的门被锁上了一样。因此,其他想要同时使用同一浴室的人(在本例中为其他线程)必须耐心等待,直到当前使用者(或线程)打开门并离开浴室。
一些程序员也喜欢用“每个人都有发言权”的比喻来解释互斥锁。这是Computerphile 项目2中的多线程代码视频中使用的比喻。想象一下,如果你在一个谈话圈中。圈子里有一位主持人,他决定谁有权在特定时刻发言。主持人给即将发言的人一张绿卡(或某种授权卡),因此,其他所有人都必须保持安静,听这位持有绿卡的人说话。当这个人讲完后,他们会把绿卡交还给主持人,然后主持人决定谁接下来发言,并将绿卡交给该人。循环往复。
在这个对话圈中,互斥锁就像一个调解员。它授权一个线程执行特定的代码段,同时阻止其他线程执行同一代码段。如果其他线程想要执行同一代码段,它们必须等待授权线程先执行完毕。当授权线程执行完这段代码后,互斥锁会授权下一个线程执行这段代码,而其余线程则保持阻塞状态。因此,互斥锁就像一个调解员,执行着“每个线程都轮流执行这段代码”的控制。
互斥锁专门用于防止数据争用问题。当两个或多个线程同时尝试读取或写入同一个共享对象时,就会发生数据争用问题。因此,当您有一个所有线程共享的对象,并且您想避免两个或多个线程同时访问同一个对象时,可以使用互斥锁来锁定访问该特定对象的代码部分。当一个线程尝试运行被互斥锁锁定的代码时,该线程会停止执行,并耐心等待代码库的这部分解锁后再继续执行。
请注意,互斥锁通常用于锁定代码库中访问/修改所有线程共享数据的区域,例如存储在全局数据段或程序堆空间中的对象。因此,互斥锁通常不用于访问/修改线程本地对象的代码库区域。
16.6.1临界区
临界区是一个通常与互斥锁和线程同步相关的概念。本质上,临界区是程序中线程访问/修改共享资源(例如对象、文件描述符等所有线程都可以访问的资源)的部分。换句话说,临界区是程序中可能发生竞争条件的部分,因此,程序中可能引入未定义的行为。
当我们在程序中使用互斥锁时,临界区定义了代码库中需要锁定的区域。因此,我们通常在临界区开头锁定互斥锁对象,然后在临界区结尾解锁。以下两点来自 GeekFromGeeks 的“临界区”文章,它们很好地概括了临界区在线程同步问题中的作用(Geeks for Geeks 2024)。
- 临界区必须以原子操作的形式执行,这意味着一旦一个线程或进程进入临界区,所有其他线程或进程都必须等待,直到正在执行的线程或进程退出临界区。同步机制的目的是确保每次只有一个线程或进程可以执行临界区。
- 临界区的概念是计算机系统同步的核心,因为它需要确保多个线程或进程能够并发执行且互不干扰。各种同步机制(例如信号量、互斥量、监视器和条件变量)都用于实现临界区,并确保以互斥的方式访问共享资源。
16.6.2原子操作
在阅读有关线程、竞争条件和互斥锁的文章时,你也会经常看到“原子操作”这个词。总而言之,如果操作过程中无法发生上下文切换,则该操作被归类为“原子操作”。换句话说,该操作始终从头到尾执行,而不会在其执行阶段被其他进程或操作打断。
如今,原子操作并不多。但为什么原子操作在这里如此重要呢?因为数据竞争(一种竞争条件)不可能发生在原子操作上。所以,如果代码中的某一行执行了原子操作,那么这一行就永远不会遭遇数据竞争问题。因此,程序员有时会使用原子操作来保护自己免受代码中数据竞争问题的影响。
如果某个操作被编译成一条汇编指令,那么该操作可能是原子的,因为它本身就是一条汇编指令。但这并不能保证。对于较旧的 CPU 架构(例如x86),通常确实如此。但如今,现代 CPU 架构中的大多数汇编指令都被分解为多个微任务,这本质上使得该操作非原子,即使它由一条汇编指令组成。
Zig 标准库在std.atomic模块中提供了一些原子功能。在此模块中,您将找到一个名为的公共通用函数Value()。使用此函数,我们创建一个“原子对象”,它是一个包含一些本机原子操作的值,最值得注意的是load()和fetchAdd()操作。如果您有使用 C++ 多线程的经验,您可能已经认出了这种模式。所以,是的,Zig 中的这个通用“原子对象”本质上与 C++ 标准库中的模板结构相同std::atomic。需要强调的是,Zig 中的这些原子操作仅支持原始数据类型(即1.5 节中介绍的类型)。
16.6.3数据竞争和竞争条件
要理解互斥锁的用途,我们需要更好地理解它们试图解决的问题,这个问题可以概括为数据竞争问题。数据竞争问题是一种竞争条件,当一个线程正在访问特定的内存位置(即特定的共享对象),而另一个线程同时尝试将新数据写入/保存到同一内存位置(即同一个共享对象)时,就会发生这种情况。
我们可以简单地将竞争条件定义为程序中任何基于“谁先到达”问题的错误。数据竞争问题就是一种竞争条件,因为它发生在两方或多方尝试同时读取和写入同一内存位置时,因此,此操作的最终结果完全取决于谁先到达该内存位置。因此,存在数据竞争问题的程序每次执行都可能产生不同的结果。
因此,竞争条件会导致行为不明确和不可预测,因为每次不同的人先于其他人到达目标位置时,程序都会产生不同的答案。而且,我们无法轻松预测或控制谁会先到达这个目标位置。换句话说,每次程序运行时,都可能得到不同的答案,因为不同的人、不同的函数或不同的代码部分先于其他人完成了任务。
举个例子,请考虑下面展示的代码片段。在这个例子中,我们创建了一个全局计数器变量,并且还创建了一个increment()函数,该函数的作用是在 for 循环中递增这个全局计数器变量。
由于 for 循环迭代了 10 万次,并且我们在此代码示例中创建了两个单独的线程,您期望在最终打印的消息中看到什么数字stdout?答案应该是 20 万。对吗?嗯,理论上,这个程序应该在最后打印 20 万,但实际上,每次执行这个程序时,我都会得到不同的答案。
在下面展示的例子中,你可以看到这次的最终结果是 117254,而不是预期的 200000。第二次执行这个程序时,我得到的结果是 108592。所以这个程序的最终结果是变化的,但它永远不会达到我们想要的 200000。
// Global counter variable
var counter: usize = 0;
// Function to increment the counter
fn increment() void {
for (0..100000) |_| {
counter += 1;
}
}
pub fn main() !void {
const thr1 = try Thread.spawn(.{}, increment, .{});
const thr2 = try Thread.spawn(.{}, increment, .{});
thr1.join();
thr2.join();
try stdout.print("Couter value: {d}\n", .{counter});
}
Couter value: 117254
为什么会发生这种情况?答案是:因为该程序存在数据争用问题。当且仅当第一个线程在第二个线程开始执行之前完成其任务时,该程序才会打印正确的数字 200000。但这不太可能发生。因为创建线程的过程太快,因此两个线程几乎同时开始执行。如果您修改此代码,在第一次和第二次调用 之间添加几纳秒的休眠时间spawn(),则可以增加程序产生“正确结果”的几率。
数据争用问题的发生是因为两个线程几乎同时读写同一内存位置。在这个例子中,每个线程在 for 循环的每次迭代中实际上执行三个基本操作,分别是:
- 读取的当前值
count。 - 将此值增加 1。
- 将结果写回
count。
理想情况下,线程 B 应该count仅在线程 A 将递增的值写回对象后才读取 的值。因此,在理想情况下(如表 16.1count所示),线程应该彼此同步工作。但实际情况是,这些线程并不同步,因此存在数据争用问题,如表 16.2所示。
请注意,在数据争用场景中(表 16.2),线程 B 执行的读取操作发生在线程 A 的写入操作之前,这最终导致程序结束时出现错误的结果。因为当线程 B 读取变量的值时count,线程 A 仍在处理 中的初始值count,并且尚未将新的递增值写回count。因此,线程 B 最终读取的是相同的初始值(或“旧”),count而不是线程 A 本来要写入的更新后的递增值。
表 16.1:两个线程增加相同整数值的理想场景
| 线程 1 | 线程 2 | 整数值 |
|---|---|---|
| 读取值 | 0 | |
| 增量 | 1 | |
| 写入值 | 1 | |
| 读取值 | 1 | |
| 增量 | 2 | |
| 写入值 | 2 |
表 16.2:两个线程增加相同整数值时的数据争用场景
| 线程 1 | 线程 2 | 整数值 |
|---|---|---|
| 读取值 | 0 | |
| 读取值 | 0 | |
| 增量 | 1 | |
| 增量 | 1 | |
| 写入值 | 1 | |
| 写入值 | 1 |
如果你仔细思考这些以表格形式呈现的图表,就会发现它们与我们在16.6.2 节中讨论的原子操作相关。记住,原子操作是指 CPU 从头到尾执行的操作,不会被其他线程或进程打断。因此,表 16.1中展示的场景不会受到数据竞争的影响,因为线程 A 执行的操作不会被线程 B 的操作在中间打断。
如果我们再思考一下16.6.1 节中关于临界区的讨论,我们就能确定程序中代表临界区的部分,也就是容易受到数据竞争条件影响的部分。在这个例子中,程序的临界区就是我们递增counter变量的那一行(counter += 1)。因此,理想情况下,我们应该使用互斥锁,并在这一行之前加锁,然后在这一行之后解锁。
16.6.4在Zig中使用互斥锁
现在我们知道了互斥锁试图解决的问题,我们可以学习如何在 Zig 中使用它们。Zig 中的互斥锁可以通过std.Thread.MutexZig 标准库中的结构体获取。如果我们采用上一个示例中的相同代码,并使用互斥锁对其进行改进,以解决数据竞争问题,我们将得到下面的代码示例。
注意,这次我们必须修改increment()函数,使其接收指向对象的指针Mutex作为输入。为了确保程序安全,避免数据争用问题,我们需要做的就是lock()在临界区开头调用该方法,然后unlock()在临界区结尾调用该方法。注意,该程序的输出现在是正确的数字 200000。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
const Thread = std.Thread;
const Mutex = std.Thread.Mutex;
var counter: usize = 0;
fn increment(mutex: *Mutex) void {
for (0..100000) |_| {
mutex.lock();
counter += 1;
mutex.unlock();
}
}
pub fn main() !void {
var mutex: Mutex = .{};
const thr1 = try Thread.spawn(.{}, increment, .{&mutex});
const thr2 = try Thread.spawn(.{}, increment, .{&mutex});
thr1.join();
thr2.join();
try stdout.print("Couter value: {d}\n", .{counter});
}
Couter value: 200000
16.7读/写锁
互斥锁通常用于两个或多个线程同时运行同一段代码并不总是安全的情况下。相比之下,读写锁通常用于混合场景,即代码库中有些部分可以安全地并行运行,而其他部分则不安全。
例如,假设您有多个线程使用文件系统中的同一个共享文件来存储某些配置或统计信息。如果两个或多个线程同时尝试从同一个文件读取数据,则不会发生任何异常。因此,这部分代码库完全可以安全地并行执行,多个线程可以同时读取同一个文件。
但是,如果两个或多个线程同时尝试将数据写入同一个文件,就会引发一些竞争条件问题。因此,代码库的这部分内容并行执行并不安全。更具体地说,一个线程可能会在另一个线程写入数据的中间写入数据。两个或多个线程同时写入同一位置可能会导致数据损坏。这种特定情况通常被称为“撕裂写入”。
因此,从这个例子中我们可以得出这样的结论:有些类型的操作会导致竞争条件,但也有一些类型的操作不会导致竞争条件问题。你也可以说,有些类型的操作容易受到竞争条件问题的影响,而有些类型的操作则不会。
读/写锁是一种承认特定场景存在的锁,您可以使用这种类型的锁来控制代码库的哪些部分可以安全地并行运行,哪些部分则不能。
16.7.1排他锁与共享锁
因此,读/写锁与互斥锁略有不同。互斥锁始终是_排他锁_,这意味着始终只允许一个线程执行。使用排他锁时,其他线程始终被“排除”,即始终被阻止执行。但在读/写锁中,其他线程可能被授权同时运行,具体取决于它们获取的锁类型。
读/写锁有两种类型:独占锁和共享锁。独占锁的工作原理与互斥锁完全相同,而共享锁则不会阻止其他线程同时运行。在pthreadsC 语言库中,读/写锁可以通过 C 结构体获得pthread_rwlock_t。使用此 C 结构体,您可以创建:
- “写锁”,对应于排他锁。
- “读锁”,对应共享锁。
与 Zig 相比,术语可能略有不同。但含义是一样的。因此,只需记住这个关系:写锁是独占锁,而读锁是共享锁。
当一个线程尝试获取读锁(即共享锁)时,当且仅当另一个线程当前未持有写锁(即独占锁),并且队列中没有其他线程正在等待获取写锁时,该线程才会获得共享锁。换句话说,队列中的线程之前曾尝试获取写锁,但由于另一个正在运行且已持有写锁的线程,该线程被阻塞。因此,该线程在等待获取写锁的队列中,并且当前正在等待另一个持有写锁的线程完成执行。
当一个线程尝试获取读锁,但未能获取到该读锁时(原因可能是已经有线程在运行并获取了写锁,或者队列中已经有线程等待获取写锁),该线程的执行将立即被阻塞,即暂停。该线程将无限期地尝试获取读锁,只有在成功获取读锁后,其执行才会解除阻塞(或恢复暂停)。
如果你深入思考读锁和写锁之间的动态关系,你可能会注意到读锁本质上是一种安全机制。更具体地说,它是一种允许特定线程仅在安全的情况下与其他线程一起运行的方法。换句话说,如果当前有一个线程正在运行并持有写锁,那么尝试获取读锁的线程现在运行很可能是不安全的。因此,读锁可以保护该线程免于陷入危险,并耐心等待“写锁”线程完成其任务后再继续运行。
另一方面,如果当前只有“读锁”(即“共享锁”)线程在运行(即当前不存在任何“写锁”线程),那么获取读锁的线程与其他线程并行运行是完全安全的。因此,读锁恰好允许该线程与其他线程一起运行。
因此,通过结合使用读锁(共享锁)和写锁(排他锁),我们可以控制多线程代码的哪些区域或部分可以安全地进行并行,哪些部分不能安全地进行并行。
16.7.2在 Zig 中使用读/写锁
Zig 标准库通过std.Thread.RwLock模块支持读/写锁。如果您希望某个线程获取共享锁(即读锁),则应该lockShared()从RwLock对象调用该方法。但是,如果您希望该线程获取独占锁(即写锁),则应该lock()从RwLock对象调用该方法。
与互斥锁一样,到达“临界区”末尾后,我们也需要解锁通过读/写锁对象获取的共享锁或排他锁。如果获取的是排他锁,则可以通过调用unlock()读/写锁对象中的方法来解锁。相反,如果获取的是共享锁,则调用unlockShared()来解锁共享锁。
举一个简单的例子,下面的代码片段创建了三个独立的线程,负责读取counter对象中的当前值,并且还创建了另一个线程,负责将新数据写入counter对象(更具体地说是增加它)。
var counter: u32 = 0;
fn reader(lock: *RwLock) !void {
while (true) {
lock.lockShared();
const v: u32 = counter;
try stdout.print("{d}", .{v});
lock.unlockShared();
std.time.sleep(2 * std.time.ns_per_s);
}
}
fn writer(lock: *RwLock) void {
while (true) {
lock.lock();
counter += 1;
lock.unlock();
std.time.sleep(2 * std.time.ns_per_s);
}
}
pub fn main() !void {
var lock: RwLock = .{};
const thr1 = try Thread.spawn(.{}, reader, .{&lock});
const thr2 = try Thread.spawn(.{}, reader, .{&lock});
const thr3 = try Thread.spawn(.{}, reader, .{&lock});
const wthread = try Thread.spawn(.{}, writer, .{&lock});
thr1.join();
thr2.join();
thr3.join();
wthread.join();
}
16.8放弃线程
该Thread结构体支持通过yield()方法进行让步。让步意味着线程的执行将暂时停止,并移至由操作系统调度程序管理的优先级队列的末尾。
也就是说,当你放弃一个线程时,你实际上是在对操作系统说:“嘿!你能暂时停止执行这个线程,稍后再回来继续吗?”。你也可以将这个放弃操作理解为:“你能降低这个线程的优先级,让你专注于其他任务吗?”。所以,这个放弃操作也是一种停止特定线程的方法,这样你就可以继续工作并优先执行其他线程。
需要强调的是,如今,yield 线程操作并不常见。换句话说,很少有程序员在生产环境中使用 yield 操作,原因很简单:这个操作很难实现,而且也存在更好的替代方案。大多数程序员更喜欢使用 yield 操作join()。事实上,大多数情况下,当你在代码示例中看到有人使用这个“yield”操作时,他们通常是为了调试应用程序中的竞争条件。也就是说,yield 操作现在主要用作调试工具。
无论如何,如果您想产生一个线程,只需yield()从中调用该方法,如下所示:
thread.yield();
16.9线程中的常见问题
16.9.1死锁
当两个或多个线程永远阻塞,等待对方释放资源时,就会发生死锁。这种情况通常发生在涉及多个锁,并且获取锁的顺序管理不善的情况下。
下面的代码示例演示了一种死锁情况。本例中,我们有两个不同的线程执行两个不同的函数(work1()和work2())。此外,我们还使用了两个独立的互斥锁。编译并运行此代码示例,你会发现程序会无限期地运行,不会结束。
当我们查看执行该work1()函数的第一个线程时,我们会注意到该函数mut1首先获取了锁。因为这是在该线程(程序中创建的第一个线程)内执行的第一个操作。之后,该函数会休眠 1 秒,以模拟某种类型的工作,然后尝试获取mut2锁。
另一方面,当我们查看执行该work2()函数的第二个线程时,我们可以看到该函数mut2首先获取了锁。因为当该线程创建并尝试获取mut2锁时,第一个线程仍在“休眠 1 秒”那行代码处休眠。获取锁后mut2,该work2()函数也会休眠 1 秒,以模拟某种类型的工作,然后该函数才会尝试获取mut1锁。
这就造成了死锁,因为在两个线程中执行完“休眠 1 秒”之后,线程 1 尝试获取mut2锁,但该锁当前正被线程 2 使用。然而,此时线程 2 也在尝试获取锁mut1,而该锁当前正被线程 1 使用。因此,两个线程最终都永远地等待着,等待对方释放它们想要获取的锁。
var mut1: Mutex = .{}; var mut2: Mutex = .{};
fn work1() !void {
mut1.lock();
std.time.sleep(1 * std.time.ns_per_s);
mut2.lock();
_ = try stdout.write("Doing some work 1\n");
mut2.unlock(); mut1.unlock();
}
fn work2() !void {
mut2.lock();
std.time.sleep(1 * std.time.ns_per_s);
mut1.lock();
_ = try stdout.write("Doing some work 1\n");
mut1.unlock(); mut2.unlock();
}
pub fn main() !void {
const thr1 = try Thread.spawn(.{}, work1, .{});
const thr2 = try Thread.spawn(.{}, work2, .{});
thr1.join();
thr2.join();
}
16.9.2不打电话join()或detach()
如果线程没有调用join()或detach(),那么这个线程就会变成“僵尸线程”,因为它没有明确的“返回点”。你也可以将其理解为:“没有人负责管理这个线程”。如果我们没有确定一个线程是_可连接 (joinable)还是_可分离 (detached) 的,那么没有人负责处理这个线程的返回值,同样,也没有人负责清除(或释放)与该线程相关的资源。
您肯定不希望遇到这种情况,所以请记住始终在您创建的线程上使用join()或detach()。如果您不使用这些方法之一,我们将失去对线程的控制,并且其资源永远不会被释放(即,您在系统中泄漏了资源)。
16.9.3取消或终止特定线程
当我们思考pthreadsC 语言库时,有一种异步终止或取消线程的方法,即SIGTERM通过函数向线程发送信号pthread_kill()。但像这样取消线程是不好的,非常危险。因此,Zig 的线程实现没有类似的函数,或者说,没有类似的异步取消或终止线程的方法。
因此,如果您想在 Zig 中取消正在执行的线程,那么一个不错的策略是将控制流与 结合使用join()。更具体地说,您可以围绕一个 while 循环设计线程,该循环不断检查线程是否应该继续运行。如果需要取消线程,我们可以中断 while 循环,并通过调用 将线程与主线程连接起来join()。
下面的代码示例在一定程度上演示了这种策略。在这里,我们使用控制流来中断while循环,并比最初计划的更早退出线程。此示例还演示了如何在Zig中将原子对象与我们在16.6.2节Value()中提到的泛型函数一起使用。
const std = @import("std");
const Thread = std.Thread;
const stdout = std.io.getStdOut().writer();
var running = std.atomic.Value(bool).init(true);
var counter: u64 = 0;
fn do_more_work() void {
std.time.sleep(2 * std.time.ns_per_s);
}
fn work() !void {
while (running.load(.monotonic)) {
for (0..10000) |_| { counter += 1; }
if (counter < 15000) {
_ = try stdout.write(
"Time to cancel the thread.\n"
);
running.store(false, .monotonic);
} else {
_ = try stdout.write("Time to do more work.\n");
do_more_work();
running.store(false, .monotonic);
}
}
}
pub fn main() !void {
const thread = try Thread.spawn(.{}, work, .{});
thread.join();
}
Time to cancel the thread.
17 向量和 SIMD 简介
在本章中,我想讨论 Zig 中的向量,它们与 SIMD 操作相关(即,它们与std::vectorC++ 中的类没有关系)。
17.1什么是SIMD?
SIMD(单指令/多数据)是一组广泛应用于视频/音频编辑程序以及图形应用程序的操作。SIMD 并非一项新技术,但在普通台式计算机上大规模使用 SIMD 才刚刚开始。过去,SIMD 仅用于“超级计算机”。
如今,大多数现代 CPU(包括 AMD、Intel 等品牌的 CPU)(无论是台式机还是笔记本电脑)都支持 SIMD 操作。因此,如果您的电脑中安装了非常老旧的 CPU,则可能不支持 SIMD 操作。
人们为什么开始在软件中使用 SIMD?答案是为了提高性能。但是,SIMD 究竟是如何实现更佳性能的呢?本质上,SIMD 操作是一种在程序中进行并行计算的策略,从而提高计算速度。
SIMD 背后的基本思想是用一条指令同时对多个数据进行操作。执行普通标量运算时,例如四条加法指令,每个加法指令都是单独执行的,一个接一个。但使用 SIMD 时,这四条加法指令会被转换为一条指令,因此,这四条加法指令可以同时并行执行。
目前,zig编译器允许您对向量对象应用以下一组运算符。当您对向量对象应用这些运算符之一时,将使用 SIMD 进行计算,因此,默认情况下,这些运算符将逐元素并行应用。
- 算术(
+,,,,,,,,等)。-/``*``@divFloor()``@sqrt()``@ceil()``@log() - 位运算符(
>>,,,,,<<等)。&``|``~ - 比较运算符(
<,,,等)>。==
17.2向量
SIMD 操作通常通过_SIMD 内部函数 (intrinsic)_执行,这只是执行 SIMD 操作的函数的别称。这些 SIMD 内部函数(或“SIMD 函数”)始终作用于一种特殊类型的对象,这种对象被称为“向量”。因此,要使用 SIMD,您必须创建一个“向量对象”。
向量对象通常是一个固定大小的 128 位(16 字节)块。因此,您在实际中发现的大多数向量本质上都是数组,包含 2 个 8 字节的值,或者 4 个 4 字节的值,或者 8 个 2 字节的值,等等。但是,不同的 CPU 型号可能具有不同的 SIMD 扩展(或“实现”),它们可能提供更多类型、更大尺寸(256 位或 512 位)的向量对象,以便在单个向量对象中容纳更多数据。
您可以使用@Vector()内置函数在 Zig 中创建一个新的向量对象。在此函数中,您可以指定向量长度(向量中元素的数量)以及向量元素的数据类型。这些向量对象仅支持原始数据类型。在下面的示例中,我创建了两个向量对象(v1和v2),每个对象包含 4 个元素u32。
另请注意,在下面的示例中,第三个向量对象(v3)是由前两个向量对象(v1plus v2)的和创建的。因此,对向量对象的数学运算默认按元素进行,因为相同的运算(在本例中为加法)被转换为单个指令,并在向量的所有元素上并行复制。
const v1 = @Vector(4, u32){4, 12, 37, 9};
const v2 = @Vector(4, u32){10, 22, 5, 12};
const v3 = v1 + v2;
try stdout.print("{any}\n", .{v3});
{ 14, 34, 42, 21 }
这就是 SIMD 提升程序性能的方式。我们无需使用 for 循环遍历v1和的元素v2,然后一次一个元素地将它们相加,而是可以享受 SIMD 的优势,它可以同时并行执行所有 4 个加法运算。
因此,该@Vector结构本质上是 SIMD 矢量对象的 Zig 表示。当且仅当您当前的 CPU 型号支持 SIMD 操作时,这些矢量对象中的元素才会并行操作。如果您的 CPU 型号不支持 SIMD,那么该@Vector结构可能会产生与“for 循环解决方案”类似的性能。
17.2.1将数组转换为向量
将普通数组转换为矢量对象有多种方法。您可以使用隐式转换(即将数组直接赋值给矢量对象),也可以使用切片从普通数组创建矢量对象。
在下面的例子中,我们隐式地将数组转换a1为长度为 4 的向量对象(v1)。我们首先明确注释向量对象的数据类型,然后将数组对象分配给这个向量对象。
还要注意,在下面的例子中,第二个向量对象(v2)也是通过获取数组对象()的切片a1,然后将指向该切片的指针(.*)存储到该向量对象中来创建的。
const a1 = [4]u32{4, 12, 37, 9};
const v1: @Vector(4, u32) = a1;
const v2: @Vector(2, u32) = a1[1..3].*;
_ = v1; _ = v2;
值得强调的是,只有编译时大小已知的数组和切片才能转换为向量。向量通常是一种仅在编译时大小已知的情况下才能工作的结构。因此,如果您有一个运行时大小已知的数组,那么在将其转换为向量之前,您需要先将其复制到一个编译时大小已知的数组中。
17.2.2函数@splat()
您可以使用@splat()内置函数创建一个向量对象,该对象的所有元素都填充相同的值。此函数旨在提供一种快速简便的方法,将标量值(即单个值,例如单个字符或单个整数等)直接转换为向量对象。
因此,我们可以用@splat()它将单个值(例如整数)转换16为长度为 1 的向量对象。但我们也可以使用此函数将同一个整数转换16为长度为 10 的向量对象,即填充 10 个16值。下面的示例演示了这个想法。
const v1: @Vector(10, u32) = @splat(16);
try stdout.print("{any}\n", .{v1});
{ 16, 16, 16, 16, 16, 16, 16, 16, 16, 16 }
17.2.3小心过大的向量
正如我在17.2 节中所述,每个向量对象通常都是 128、256 或 512 位的小块。这意味着向量对象通常很小,而当你试图反其道而行之时,通过创建一个非常大的向量对象(即,大小接近220),通常会导致编译器崩溃和出现严重错误。
例如,如果您尝试编译下面的程序,则可能会在构建过程中遇到段错误或 LLVM 错误。请注意不要创建过大的向量对象。
const v1: @Vector(1000000, u32) = @splat(16);
_ = v1;
Segmentation fault (core dumped)
References
Chen, Jenny, and Ruohao Guo. 2022. “Stack and Heap Memory.” Introduction to Data Structures and Algorithms with C++. https://courses.engr.illinois.edu/cs225/fa2022/resources/stack-heap/.
Geeks for Geeks. 2024a. “Critical Section.” Geeks for Geeks. https://www.geeksforgeeks.org/g-fact-70/.
———. 2024b. “Generics in c++.” Geeks for Geeks. https://www.geeksforgeeks.org/generics-in-c/.
Kim, Juhee, Jinbum Park, Sihyeon Roh, Jaeyoung Chung, Youngjoo Lee, Taesoo Kim, and Byoungyoung Lee. 2024. “TikTag: Breaking ARM’s Memory Tagging Extension with Speculative Execution.” https://arxiv.org/abs/2406.08719.
Linux man-pages. 2024. “Pthread_create(3) — Linux Manual Page.” https://man7.org/linux/man-pages/man3/pthread_create.3.html.
Meehan, Eric. 2021. “Creating a Web Server from Scratch in c.” Youtube. https://www.youtube.com/watch?v=gk6NL1pZi1M&ab_channel=EricOMeehan.
Microsoft. 2021. “Bitwise AND Operator: &.” Microsoft Learn. https://learn.microsoft.com/en-us/cpp/cpp/bitwise-and-operator-amp?view=msvc-170.
Seguin, Karl. 2024. “Generics.” https://www.openmymind.net/learning_zig/generics/.
Sobeston. 2024. “Zig Guide.” https://zig.guide/.
Weerasiri, Nipun Chamikara. 2023. “A Simple Web Server Written in c.” Medium. https://medium.com/@nipunweerasiri/a-simple-web-server-written-in-c-cf7445002e6.
Wikipedia. 2024a. “File Descriptor.” Wikipedia. https://en.wikipedia.org/wiki/File_descriptor.
———. 2024b. “Grayscale.” Wikipedia. https://en.wikipedia.org/wiki/Grayscale.
———. 2024c. “Hash Tables.” Wikipedia. https://en.wikipedia.org/wiki/Hash_table.
———. 2024d. “Port (Computer Networking).” Wikipedia. https://en.wikipedia.org/wiki/Port_(computer_networking).
Yu, Jeffrey. 2023. “How i Built a Simple HTTP Server from Scratch Using c.” DEV Community. https://dev.to/jeffreythecoder/how-i-built-a-simple-http-server-from-scratch-using-c-739.
Zig Software Foundation. 2024a. “In-Depth Overview.” Zig Software Foundation. https://ziglang.org/learn/overview/.
———. 2024b. “Language Reference.” Zig Software Foundation. https://ziglang.org/documentation/master/.