13 文件系统和输入/输出IO
在本章中,我们将讨论如何使用 Zig 标准库中可执行文件系统操作的跨平台结构体和函数。这些函数和结构体大部分来自该std.fs模块。
我们还将讨论 Zig 中的输入/输出(也称为 IO)操作。大多数此类操作都是使用std.io模块中的结构体和函数完成的,该模块定义了系统_标准通道_stdout(和stdin)的文件描述符,以及创建和使用 I/O 流的函数。
13.1输入/输出基础
如果你有高级语言的使用经验,你肯定曾经使用过这种语言的输入输出功能。换句话说,你肯定遇到过需要向用户发送输出,或者接收用户输入的情况。
例如,在 Python 中,我们可以使用内置函数接收用户的输入input()。但我们也可以使用内置函数向用户打印(或“显示”)一些输出print()。所以,如果你之前用 Python 编程过,你肯定用过这些函数。
但是你知道这些函数与你的操作系统 (OS) 之间是如何关联的吗?它们究竟是如何与操作系统的资源交互来接收或发送输入/输出的。本质上,这些来自高级语言的输入/输出函数只是对操作系统_标准输出_和_标准输入通道的抽象。_
这意味着我们通过操作系统接收输入或发送输出。操作系统在用户和程序之间架起了桥梁。程序无法直接访问用户。操作系统充当程序和用户之间交换的每条消息的中介。
操作系统的标准输出和标准输入通道通常分别称为操作系统_的_和_通道_。在某些情况下,它们也被称为stdout标准_输出设备_和_标准输入设备_。顾名思义,_标准输出_是输出流经的通道,而_标准输入_是输入流经的通道。stdin
此外,操作系统通常还会创建一个专门用于交换错误消息的通道,称为_标准错误_通道(或称为stderr通道)。错误和警告消息通常会发送到这个通道。这些消息通常会以类似红色或橙色的颜色显示在终端中。
通常,每个操作系统(例如 Windows、macOS、Linux 等)都会为计算机中运行的每个程序(或进程)创建一组专用且独立的_标准输出_、标准错误_和_标准输入stdin通道。这意味着您编写的每个程序都有一个专用的、stderr和 ,stdout它们与当前正在运行的其他程序和进程的 、stdin和stderr相互独立。stdout
这是操作系统的行为,而非你所使用的编程语言。因为正如我之前所说,编程语言(尤其是高级编程语言)中的输入和输出只是对当前操作系统的简单抽象stdin。stderr也就是说stdout,无论你使用哪种编程语言,操作系统都是程序中每个输入/输出操作的中介。
13.1.1写入器和读取器模式
在 Zig 中,有一个围绕输入/输出 (IO) 的模式。我(本书作者)不知道这种模式是否有正式名称。但在本书中,我将其称为“写入器和读取器模式”。本质上,Zig 中的每个 IO 操作都是通过 或GenericReader对象GenericWriter1进行的。
这两种数据类型来自std.ioZig 标准库的模块。顾名思义,aGenericReader是一个提供从“某物”(或“某处”)读取数据的工具的对象,而 a 则GenericWriter提供将数据写入此“某物”的工具。此“某物”可能是不同的东西:例如文件系统中的文件;或者,可能是系统2中的网络套接字;或者,可能是连续的数据流,例如系统中的标准输入设备,它可能不断从用户那里接收新数据;或者,再举一个例子,游戏中的实时聊天不断接收并显示来自游戏玩家的新消息。
因此,如果您想从某个地方读取数据,就需要使用GenericReader对象。但是,如果您需要将数据写入这个“东西”,那么就需要使用GenericWriter对象。这两个对象通常都是通过文件描述符对象创建的。更具体地说,是通过该文件描述符对象的writer()和reader()方法创建的。如果您不熟悉这种类型的对象,请跳到下一节。
每个GenericWriter对象都有类似的方法print(),允许你将格式化的字符串(例如,这个格式化的字符串类似于fPython 中的字符串,或者类似于printf()C 函数)写入/发送到你正在使用的“对象”(文件、套接字、流等)。它还有一个writeAll()方法,允许你将字符串或字节数组写入“对象”。
同样,每个GenericReader对象都有类似 的方法readAll(),它允许你从“对象”(文件、套接字、流等)读取数据,直到填满一个特定的数组(即“缓冲区”)对象。换句话说,如果你向 提供了一个包含 300 个u8值的数组对象readAll(),那么该方法会尝试从“对象”读取 300 个字节的数据,并将它们存储到你提供的数组对象中。
我们还有其他方法,例如readAtLeast()方法,它允许你指定要从“某个对象”中读取的具体字节数。更详细地说,如果你给出数字n作为此方法的输入,它将尝试至少读取n来自“某物”的数据字节数。“某物”可能少于n可供您读取的数据字节数,因此,不能保证您将获得精确的n字节作为结果。
另一个有用的方法是readUntilDelimiterOrEof()。在此方法中,您可以指定一个“分隔符”。其理念是,此函数将尝试从“某些内容”中读取尽可能多的字节数据,直到到达流的末尾,或者遇到您指定的“分隔符”。
如果您不确定“某物”究竟会有多少字节,您可能会发现该readAllAlloc()方法很有用。本质上,您为该方法提供了一个分配器对象,以便它可以根据需要分配更多空间。因此,该方法将尝试读取“某物”的所有字节,并且,如果在“读取过程”的某个时刻空间不足,它将使用分配器对象分配更多空间以继续读取字节。最终,该方法返回一个包含所有读取字节的数组对象的切片。
这只是对这些类型对象中存在的方法的简要描述。但我建议您阅读官方文档,包括3和4 。我还认为阅读 Zig 标准库中定义这些对象中存在的方法(即5和6 )的模块源代码是个好主意。GenericWriterGenericReaderReader.zigWriter.zig
13.1.2介绍文件描述符
“文件描述符”对象是任何操作系统 (OS) 中每个 IO 操作背后的核心组件。该对象是操作系统中特定输入/输出 (IO) 资源的标识符(维基百科 2024 )。它描述并标识了该特定资源。IO 资源可能是:
- 文件系统中现有的文件。
- 现有的网络套接字。
- 其他类型的溪流通道。
- 终端7中的管道(或简称“管道”)。
从上面列出的要点中,我们知道虽然存在“文件”一词,但“文件描述符”可能描述的不仅仅是一个文件。“文件描述符”的概念来自可移植操作系统接口 (POSIX) API,这是一组标准,用于指导世界各地的操作系统如何实现,以保持它们之间的兼容性。
文件描述符不仅标识用于接收或发送数据的输入/输出资源,还描述该资源的位置以及当前使用的 IO 模式。例如,该 IO 资源可能仅使用“读取”模式,这意味着该资源仅对“读取操作”开放,而“写入操作”则不被授权。这些 IO 模式本质上就是你mode从fopen()C 函数以及open()Python 内置函数传入参数的模式。
在 C 语言中,“文件描述符”是一个FILE指针,但在 Zig 中,文件描述符是一个File对象。此数据类型 ( File) 在 Zig 标准库的模块中进行了描述std.fs。我们通常不会File在 Zig 代码中直接创建对象。相反,我们通常在打开 IO 资源时得到这样的对象作为结果。换句话说,我们通常会要求操作系统为我们打开一个特定的 IO 资源,如果操作系统成功打开了这个 IO 资源,它通常会将这个特定 IO 资源的文件描述符返回给我们。
因此,通常使用 Zig 标准库中的函数和方法来获取一个File对象,这些函数和方法请求操作系统打开某些 IO 资源,例如openFile()在文件系统中打开文件的方法。我们在7.4.1 节net.Stream中创建的对象也是一种文件描述符对象。
13.1.3标准_输出_
您已经在本书中了解了如何访问并使用stdoutZig 中的 来向用户发送一些输出。为此,我们使用了模块getStdOut()中的函数std.io。此函数返回一个文件描述符,该描述符描述了当前操作系统的通道。通过这个文件描述符对象,我们可以从程序的stdout读取或写入数据。stdout
虽然我们可以读取记录到通道中的内容stdout,但通常我们只会向该通道写入(或“打印”)内容。原因与我们在第 7.4.3 节中讨论的内容非常相似,当时我们讨论了在我们的小型 HTTP Server 项目中,“读取”和“写入”连接对象的含义。
当我们向通道写入数据时,我们实际上是将数据发送到该通道的另一端。相反,当我们从该通道读取数据时,我们实际上是在读取通过该通道发送的数据。由于 是stdout一个将输出发送给用户的通道,因此这里的关键动词是发送。我们想要将某些内容发送给某人,因此,我们想要将某些内容写入某个通道。
这就是为什么当我们使用 时getStdOut(),大多数情况下,我们还会使用文件描述符writer()中的方法stdout,来访问一个写入器对象,以便将内容写入此stdout通道。更具体地说,此writer()方法返回一个GenericWriter对象。该对象的主要方法之一GenericWriter就是print()我们之前用来将格式化字符串写入(或“打印”)通道的方法stdout。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
try stdout.writeAll(
"This message was written into stdout.\n"
);
}
This message was written into stdout.
此GenericWriter对象与您通常从文件描述符对象中获取的任何其他通用写入器对象类似。因此,您在将文件写入文件系统时使用的通用写入器对象中的方法,在这里也可以从 的文件描述符对象中使用,stdout反之亦然。
13.1.4标准_输入_
您可以使用模块中的函数访问 Zig 中的_标准输入_(即) 。与其兄弟()一样,此函数也返回一个描述操作系统通道的文件描述符对象。stdin``getStdIn()``std.io``getStdOut()``stdin
因为我们需要接收用户的输入,所以这里的关键动词是receive,因此,我们通常希望从通道读取stdin数据,而不是将数据写入通道。因此,我们通常使用reader()返回的文件描述符对象的 方法getStdIn()来访问一个GenericReader可以用来从 读取数据的对象stdin。
在下面的示例中,我们创建了一个可容纳 20 个字符的小缓冲区。然后,我们尝试使用stdin方法从 读取数据readUntilDelimiterOrEof(),并将数据保存到buffer对象中。另请注意,我们一直从 读取数据,stdin直到遇到换行符 ( '\n')。
如果你执行这个程序,你会注意到它会停止执行,并开始无限期地等待用户的输入。换句话说,你需要在终端中输入你的名字,然后按 Enter 键将你的名字发送到stdin。将你的名字发送到 之后stdin,程序会读取此输入,并继续执行,将给定的名字打印到stdout。在下面的例子中,我在终端中输入了我的名字(Pedro),然后按了 Enter 键。
const std = @import("std");
const stdout = std.io.getStdOut().writer();
const stdin = std.io.getStdIn().reader();
pub fn main() !void {
try stdout.writeAll("Type your name\n");
var buffer: [20]u8 = undefined;
@memset(buffer[0..], 0);
_ = try stdin.readUntilDelimiterOrEof(buffer[0..], '\n');
try stdout.print("Your name is: {s}\n", .{buffer});
}
Type your name
Your name is: Pedro
13.1.5标准_误差_
标准_错误_(又名)的工作原理与和stderr完全相同。您只需从模块中调用该函数,即可将文件描述符发送到。理想情况下,您应该只将错误或警告消息写入,因为这是此通道的用途。stdout``stdin``getStdErr()``std.io``stderr``stderr
13.2缓冲 IO
正如我们在13.1 节中所述,输入/输出 (IO) 操作直接由操作系统执行。操作系统负责管理您要用于 IO 操作的 IO 资源。因此,IO 操作很大程度上依赖于系统调用(即直接调用操作系统)。
需要明确的是,系统调用本身并没有什么特别的问题。我们在任何用低级编程语言编写的严肃代码库中都会经常使用它们。然而,系统调用的速度总是比许多不同类型的操作慢几个数量级。
偶尔使用系统调用完全没问题。但是,如果频繁使用这些系统调用,大多数情况下应用程序的性能损失都会很明显。因此,一个好的经验法则是,只在需要时使用系统调用,并且只在不频繁的情况下使用,以将执行的系统调用次数降至最低。
13.2.1理解缓冲 IO 的工作原理
缓冲 IO 是一种实现更高性能的策略。它用于减少 IO 操作的系统调用数量,从而实现更高的性能。在图 13.1和图 13.2中,您可以找到两张不同的图表,它们展示了在无缓冲 IO 环境和有缓冲 IO 环境中执行的读取操作之间的差异。
为了更好地理解这些图表,假设我们的文件系统中有一个包含著名的 Lorem ipsum 文本8 的文本文件。我们还假设图 13.1和图 13.2中的图表展示了我们从该文本文件中读取 Lorem ipsum 文本的读取操作。查看这些图表时,您首先会注意到,在无缓冲环境中,读取操作会导致许多系统调用。更准确地说,在图13.1 中,我们从文本文件读取的每个字节都会产生一个系统调用。另一方面,在图 13.2中,我们在最开始只有一个系统调用。
当我们使用缓冲 IO 系统时,在执行第一次读取操作时,操作系统不会直接向程序发送一个字节,而是先将文件中的一大块字节发送到一个缓冲区对象(即数组)。这块字节会被缓存/存储在这个缓冲区对象中。
因此,从现在开始,对于您执行的每个新的读取操作,都无需进行新的系统调用来向操作系统请求文件中的下一个字节,而是将该读取操作重定向到缓冲区对象,该缓冲区对象已缓存了下一个字节并准备就绪。
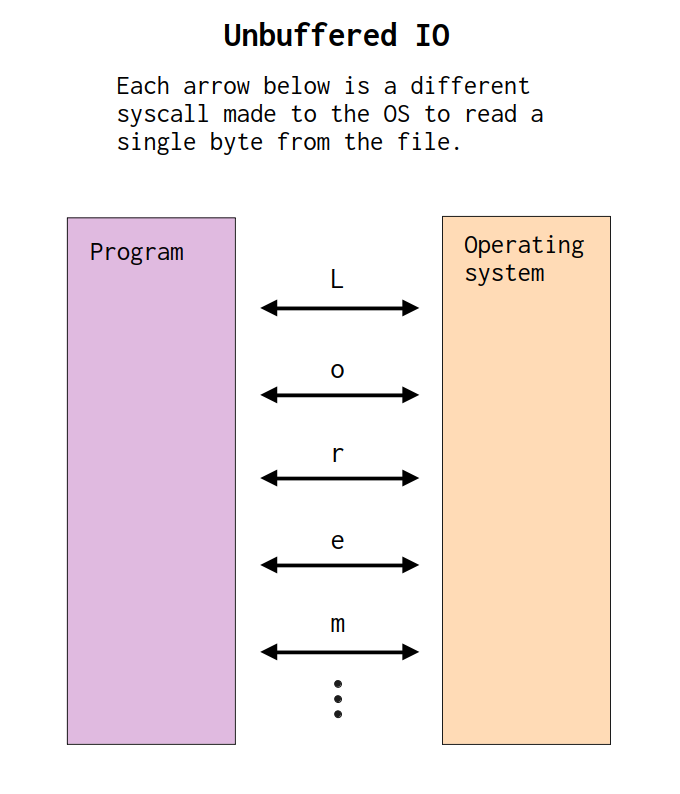
图 13.1:无缓冲 IO
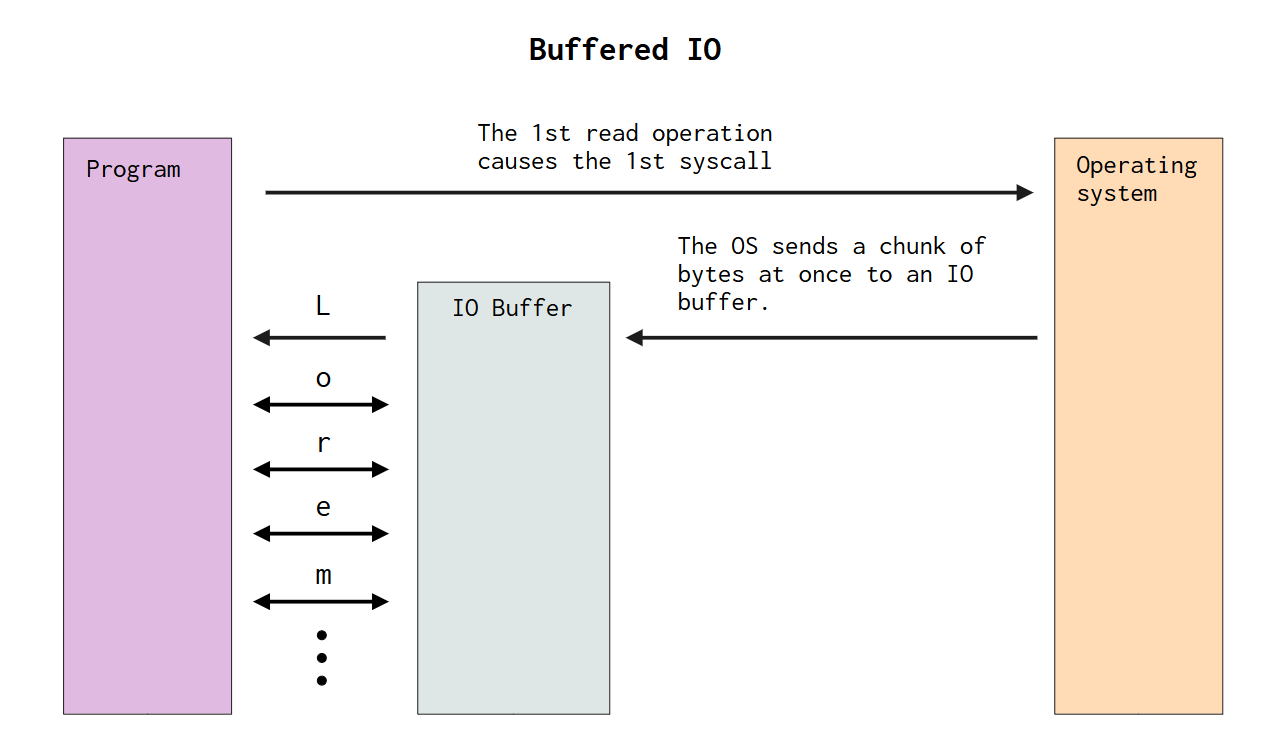
图 13.2:缓冲 IO
这是缓冲 IO 系统背后的基本逻辑。缓冲区对象的大小取决于多种因素。但它通常等于一整页内存(4096 字节)的大小。如果我们遵循这个逻辑,那么操作系统会读取文件的前 4096 个字节并将其缓存到缓冲区对象中。只要你的程序没有从缓冲区中消耗掉所有这 4096 个字节,就不会创建新的系统调用。
但是,一旦缓冲区中所有 4096 个字节都被用完,就意味着缓冲区中没有剩余字节了。在这种情况下,系统会发出一个新的系统调用,请求操作系统发送文件中接下来的 4096 个字节,这些字节再次被缓存到缓冲区对象中,然后循环再次开始。
13.2.2不同语言的缓冲 IO
在 C 语言中,通过FILE指针进行的 IO 操作默认是缓冲的,因此,至少在 C 语言中,你无需担心这个问题。但相比之下,Rust 和 Zig 中的 IO 操作不会缓冲,具体取决于你使用的标准库函数。
例如,在 Rust 中,缓冲 IO 是通过BufReader和BufWriter结构体实现的,而在 Zig 中,它通过BufferedReader和结构体实现。因此,你通过我在13.1.1 节中介绍的和对象BufferedWriter执行的任何 IO 操作都不会被缓冲,这意味着这些对象可能会根据具体情况创建大量系统调用。GenericWriter``GenericReader
13.2.3在Zig中使用缓冲IO
在 Zig 中使用缓冲 IO 实际上非常简单。您只需将GenericWriter对象传递给bufferedWriter()函数,或者将GenericReader对象传递给bufferedReader()函数即可。这些函数来自std.io模块,它们将为您构造BufferedWriter或对象。BufferedReader
创建这个新的BufferedWriter或BufferedReader对象后,您可以调用这个新对象的writer()或reader()方法来访问新的(和缓冲的)通用读取器或通用写入器。
让我们再次描述一下这个过程。每当你有一个文件描述符对象时,你首先通过调用该文件描述符对象的writer()或方法从中获取通用写入器或通用读取器对象。然后,你将这个通用写入器或通用读取器提供给或函数,该函数会创建一个新的或对象。接着,你调用这个缓冲写入器或缓冲读取器对象的或方法,这将使你能够访问缓冲的通用写入器或通用读取器对象。reader()``bufferedWriter()``bufferedReader()``BufferedWriter``BufferedReader``writer()``reader()
以这个程序为例。该程序演示了图 13.2中展示的过程。我们只是打开一个包含 Lorem ipsum 文本的文本文件,然后在 处创建一个缓冲 IO 读取器对象bufreader,并使用该bufreader对象将此文件的内容读入缓冲区对象,然后,我们将此缓冲区的内容打印到 处,以此结束程序stdout。
var file = try std.fs.cwd().openFile(
"ZigExamples/file-io/lorem.txt", .{}
);
defer file.close();
var buffered = std.io.bufferedReader(file.reader());
var bufreader = buffered.reader();
var buffer: [1000]u8 = undefined;
@memset(buffer[0..], 0);
_ = try bufreader.readUntilDelimiterOrEof(
buffer[0..], '\n'
);
try stdout.print("{s}\n", .{buffer});
Lorem ipsum dolor sit amet, consectetur
adipiscing elit. Sed tincidunt erat sed nulla ornare, nec
aliquet ex laoreet. Ut nec rhoncus nunc. Integer magna metus,
ultrices eleifend porttitor ut, finibus ut tortor. Maecenas
sapien justo, finibus tincidunt dictum ac, semper et lectus.
Vivamus molestie egestas orci ac viverra. Pellentesque nec
arcu facilisis, euismod eros eu, sodales nisl. Ut egestas
sagittis arcu, in accumsan sapien rhoncus sit amet. Aenean
neque lectus, imperdiet ac lobortis a, ullamcorper sed massa.
Nullam porttitor porttitor erat nec dapibus. Ut vel dui nec
nulla vulputate molestie eget non nunc. Ut commodo luctus ipsum,
in finibus libero feugiat eget. Etiam vel ante at urna tincidunt
posuere sit amet ut felis. Maecenas finibus suscipit tristique.
Donec viverra non sapien id suscipit.
尽管它是一个带缓冲的 IO 读取器,但该bufreader对象与其他对象类似GenericReader,并且具有完全相同的方法。因此,尽管这两种类型的对象执行截然不同的 IO 操作,但它们具有相同的接口,因此您(程序员)可以互换使用它们,而无需在源代码中进行任何更改。因此,带缓冲的 IO 读取器或带缓冲的 IO 写入器对象与其通用和非缓冲的兄弟(即我在13.1.1 节中介绍的通用读取器和通用写入器对象)具有相同的方法。
提示
一般来说,你应该始终使用缓冲 IO 读取器或缓冲 IO 写入器对象在 Zig 中执行 IO 操作。因为它们能为你的 IO 操作提供更好的性能。
13.3文件系统基础
既然我们已经讨论了 Zig 中输入/输出操作的基础知识,我们需要讨论文件系统的基础知识,这是任何操作系统的另一个核心部分。此外,文件系统与输入/输出相关,因为我们在计算机中存储和创建的文件被视为 IO 资源,正如我们在第 13.1.2 节中所述。
13.3.1当前工作目录(CWD)的概念
工作目录是您当前计算机上的根文件夹。换句话说,它是您的程序当前正在查看的文件夹。因此,每当您执行程序时,该程序始终会使用计算机上的特定文件夹。程序始终会在此文件夹中初始查找您需要的文件,并且程序也会在此文件夹中初始保存您要求它保存的所有文件。
工作目录由您在终端中调用程序的文件夹决定。换句话说,如果您在操作系统的终端中,并从该终端执行一个二进制文件(即程序),则终端指向的文件夹就是正在执行的程序的当前工作目录。
图 13.3中展示了我从终端执行程序的示例。我们正在执行zig编译器通过编译名为 的 Zig 模块输出的程序hello.zig。在这种情况下,CWD 指的是zig-book文件夹。换句话说,在hello.zig程序执行时,它会查看该zig-book文件夹,并且我们在该程序内部执行的任何文件操作都将以该zig-book文件夹为“起点”,或者说“中心点”。
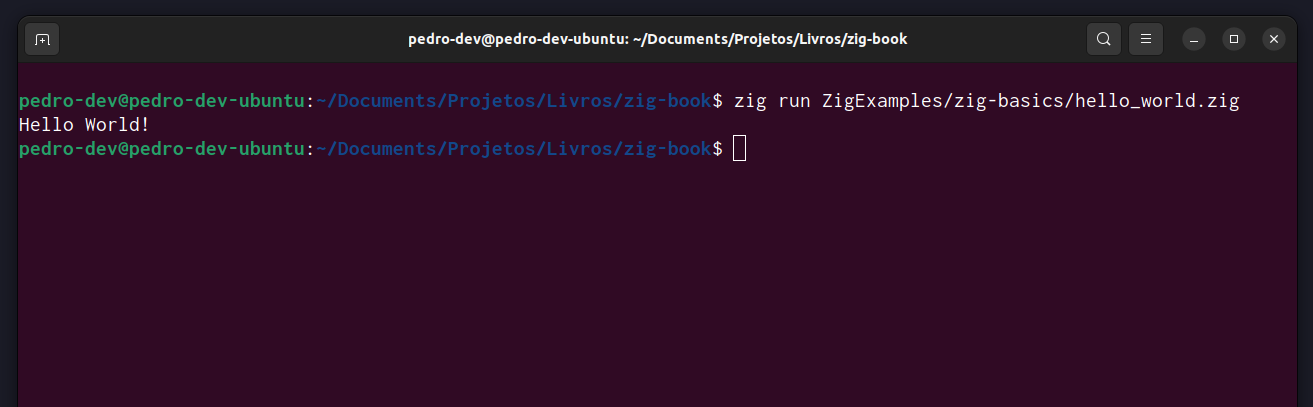
图 13.3:从终端执行程序
即使我们根植于计算机的某个特定文件夹(在图 13.3中为文件zig-book夹),这并不意味着我们不能访问或写入计算机其他位置的资源。当前工作目录 (CWD) 机制只是定义了程序在查找所需文件时首先在何处查找。这并不妨碍您访问位于计算机其他位置的文件。但是,要访问当前工作目录以外的文件夹中的任何文件,您必须提供该文件或文件夹的路径。
13.3.2路径的概念
路径本质上是一个位置。它指向文件系统中的一个位置。我们使用路径来描述文件和文件夹在计算机中的位置。路径的一个重要特点是它们始终以字符串形式写入,即始终以文本值的形式提供。
您可以为任何操作系统中的任何程序提供两种类型的路径:相对路径或绝对路径。绝对路径是从文件系统根目录开始,一直到您要引用的文件名或特定文件夹的路径。这种路径称为绝对路径,因为它指向计算机上唯一的绝对位置。也就是说,您的计算机上没有其他现有位置与此路径相对应。它是一个唯一标识符。
在 Windows 中,绝对路径是以硬盘标识符开头的路径(例如 C:/Users/pedro)。另一方面,Linux 和 macOS 中的绝对路径是以正斜杠字符开头的路径(例如 )。请注意,路径由“段”组成。每个段通过斜杠字符(或)/usr/local/bin相互连接。在 Windows 上,通常使用反斜杠()连接路径段。而在 Linux 和 macOS 上,正斜杠()是用于连接路径段的字符。\``/``\``/
相对路径是从 CWD 开始的路径。换句话说,相对路径是“相对于 CWD”的。图 13.3hello.zig中用于访问文件的路径就是一个相对路径的示例。该路径如下所示。该路径从 CWD(在图 13.3的上下文中是文件夹)开始,然后进入文件夹,再进入文件。zig-book``ZigExamples``zig-basics``hello.zig
ZigExamples/zig-basics/hello_world.zig
13.3.3路径通配符
提供路径(尤其是相对路径)时,您可以选择使用_通配符_。路径中有两种常用的_通配符_,即“一个句点”(.)和“两个句点”(..)。换句话说,这两个特定字符在路径中使用时具有特殊含义,并且可以在任何操作系统(Mac、Windows、Linux 等)上使用。也就是说,它们是“跨平台的”。
“一个句点”表示当前目录的别名。这意味着相对路径"./Course/Data/covid.csv"和"Course/Data/covid.csv"是等效的。另一方面,“两个句点”指的是上一个目录。例如, 路径"Course/.."相当于 路径".",即当前工作目录。
因此,路径"Course/.."指的是文件夹之前的文件夹Course。再举一个例子,路径指的是文件夹之前的文件夹内的"src/writexml/../xml.cpp"文件,在本例中,文件夹就是文件夹。因此,此路径等同于。xml.cpp``writexml``src``"src/xml.cpp"
13.4 CWD 处理程序
在 Zig 中,文件系统操作通常通过目录处理程序对象进行。Zig 中的目录处理程序是一个 类型的对象Dir,该对象描述计算机文件系统中的特定文件夹。通常Dir通过调用std.fs.cwd()函数来创建对象。此函数返回一个Dir指向(或描述)当前工作目录 (CWD) 的对象。
通过此Dir对象,您可以创建新文件、修改文件或读取 CWD 中的现有文件。换句话说,Dir对象是 Zig 中执行多种文件系统操作的主要入口点。在下面的示例中,我们将创建此Dir对象并将其存储在该cwd对象中。虽然我们在此代码示例中没有使用此对象,但在接下来的示例中我们将大量使用它。
const cwd = std.fs.cwd();
_ = cwd;
13.5文件操作
13.5.1创建文件
我们使用createFile()该Dir对象中的方法创建新文件。只需提供要创建的文件名,此函数就会执行创建该文件所需的步骤。您还可以为此函数提供一个相对路径,它将按照此路径(相对于 CWD)创建文件。
此函数可能会返回错误,因此,您应该使用try、或第十章catch中介绍的任何其他方法来处理可能的错误。但如果一切顺利,此方法将返回一个文件描述符对象(即一个对象),您可以通过该对象使用我之前介绍的 IO 操作向文件添加内容。createFile()``File
以下面的代码示例为例。在本例中,我们创建了一个名为 的新文本文件foo.txt。如果函数createFile()执行成功,名为 的对象file将包含一个文件描述符对象,我们可以使用该对象向文件写入(或添加)新内容,就像本例中一样,使用缓冲写入器对象向文件写入一行新文本。
现在,简要说明一下,当我们在 C 语言中创建文件描述符对象时,通过使用像 这样的 C 函数fopen(),我们必须始终在程序结束时关闭该文件,或者,一旦我们完成对文件执行的所有操作后立即关闭该文件。在 Zig 中,这没有什么不同。因此,每次我们创建一个新文件时,该文件都会保持“打开”状态,等待执行某些操作。一旦我们完成操作,我们总是必须关闭此文件,以释放与其关联的资源。在 Zig 中,我们通过close()从文件描述符对象调用方法来执行此操作。
const cwd = std.fs.cwd();
const file = try cwd.createFile("foo.txt", .{});
// Don't forget to close the file at the end.
defer file.close();
// Do things with the file ...
var fw = file.writer();
_ = try fw.writeAll(
"Writing this line to the file\n"
);
因此,在这个例子中,我们不仅在文件系统中创建了一个文件,还使用 返回的文件描述符对象向该文件写入了一些数据createFile()。如果您尝试创建的文件已存在于文件系统中,则此createFile()调用将覆盖该文件的内容,或者换句话说,它将擦除现有文件的所有内容。
如果您不希望发生这种情况,即您不想覆盖现有文件的内容,但无论如何都想将数据写入该文件(即,您想将数据附加到该文件),则应该使用对象openFile()中的方法Dir。
另一个重要的方面是createFile(),此方法会创建一个默认不开放读取操作的文件。这意味着您无法读取此文件。您不被允许这样做。例如,您可能想在程序执行开始时向此文件中写入一些内容。然后,在程序的某个时刻,您可能需要读取您在此文件中写入的内容。如果您尝试从此文件中读取数据,则可能会出现NotOpenForReading错误。
但是如何克服这个障碍呢?如何创建一个可以读取的文件呢?你只需要read在 的第二个参数中将标志设置为 true即可createFile()。当将此标志设置为 true 时,该文件将以“读取权限”创建,因此,如下所示的程序将生效:
const cwd = std.fs.cwd();
const file = try cwd.createFile(
"foo.txt",
.{ .read = true }
);
defer file.close();
var fw = file.writer();
_ = try fw.writeAll("We are going to read this line\n");
var buffer: [300]u8 = undefined;
@memset(buffer[0..], 0);
try file.seekTo(0);
var fr = file.reader();
_ = try fr.readAll(buffer[0..]);
try stdout.print("{s}\n", .{buffer});
We are going to read this line
如果您不熟悉位置指示器,您可能无法识别该方法。如果是这样,请不要担心,我们将在13.6 节seekTo()中进一步讨论此方法。但本质上,此方法是将位置指示器移回文件开头,以便我们可以从头开始读取文件内容。
13.5.2打开文件并向其中附加数据
打开文件很简单。只需使用openFile()方法而不是createFile()。在第一个参数中,openFile()提供要打开的文件的路径。然后,在第二个参数中,提供标志(或选项),用于指示如何打开文件。
您可以通过访问9 的openFile()文档来查看完整的选项列表。但您最肯定会使用的主要标志是标志。此标志指定文件打开时将使用的 IO 模式。有三种 IO 模式,或者说,您可以为该标志提供三个值,它们是:OpenFlagsmode
read_only,仅允许对文件进行读取操作。所有写入操作均被阻止。write_only,仅允许对文件进行写入操作。所有读取操作均被阻止。read_write,允许对文件进行写入和读取操作。
这些模式类似于您提供给Python 内置函数10或C 函数11的参数mode的模式。在下面的代码示例中,我们使用某种模式打开文本文件,并在文件末尾附加一行新文本。我们利用这段时间来确保将文本附加到文件末尾。同样,第 13.6 节将更深入地介绍此类方法。open()mode``fopen()foo.txt``write_only``seekFromEnd()``seekFromEnd()
const cwd = std.fs.cwd();
const file = try cwd.openFile(
"foo.txt", .{ .mode = .write_only }
);
defer file.close();
try file.seekFromEnd(0);
var fw = file.writer();
_ = try fw.writeAll("Some random text to write\n");
13.5.3删除文件
有时,我们只需要删除/移除已有的文件。为此,我们使用该deleteFile()方法。您只需提供要删除的文件的路径,该方法就会尝试删除位于此路径的文件。
const cwd = std.fs.cwd();
try cwd.deleteFile("foo.txt");
13.5.4复制文件
要复制现有文件,我们使用该copyFile()方法。该方法中的第一个参数是要复制的文件的路径。第二个参数是一个Dir对象,即目录处理程序,更具体地说,是一个Dir指向计算机中要将文件复制到的文件夹的对象。第三个参数是文件的新路径,或者换句话说,是文件的新位置。第四个参数是复制操作中要使用的选项(或标志)。
您提供给此方法作为输入的对象Dir将用于将文件复制到新位置。您可以Dir在调用此copyFile()方法之前创建此对象。也许您计划将文件复制到计算机中完全不同的位置,因此可能需要为该位置创建一个目录处理程序。但是,如果您要将文件复制到 CWD 的子文件夹,那么您只需将 CWD 处理程序传递给此参数即可。
const cwd = std.fs.cwd();
try cwd.copyFile(
"foo.txt",
cwd,
"ZigExamples/file-io/foo.txt",
.{}
);
13.5.5阅读文档!
对象上还有一些其他有用的文件操作方法Dir,例如方法,但我建议您阅读类型12writeFile()的文档以探索其他可用的方法,因为我已经谈论了太多关于它们的内容。Dir
13.6位置指示器
位置指示器类似于一种游标,或者说是一种索引。这个“索引”标识了文件描述符对象当前正在查看的文件(或数据流)中的当前位置。创建文件描述符时,位置指示器从文件的开头(或数据流的开头)开始。当你读取或写入该文件描述符对象所描述的文件(或套接字、数据流等)时,最终会移动位置指示器。
换句话说,任何 IO 操作都有一个共同的副作用,那就是移动位置指示器。例如,假设我们有一个总共 300 字节的文件。如果你从文件中读取 100 字节,那么位置指示器就会向前移动 100 字节。如果你尝试向同一个文件中写入 50 字节,那么这 50 字节将从位置指示器指示的当前位置写入。由于位置指示器位于文件开头向前 100 字节的位置,因此这 50 字节将被写入文件中间。
这就是为什么我们在13.5.1 节seekTo()中给出的最后一个代码示例中使用了该方法。我们使用该方法将位置指示器移回文件开头,这样可以确保我们从文件开头写入想要写入的文本,而不是从文件中间写入。因为在写入操作之前,我们执行了读取操作,这意味着位置指示器在这次读取操作中被移动了。
可以使用文件描述符对象中的“seek”方法来更改(或修改)其位置指示器,这些方法是:seekTo()、seekFromEnd()和。这些方法具有与13seekBy() C 函数相同的效果,或者说相同的职责。fseek()
考虑到offset指的是您提供给这些“查找”方法的索引,下面的要点总结了每种方法的效果。简要说明一下,对于seekFromEnd()和seekBy(),offset提供的 可以是正索引,也可以是负索引。
seekTo()``offset将把位置指示器移动到距文件开头字节的位置。seekFromEnd()``offset将把位置指示器移动到距文件末尾字节的位置。seekBy()将把位置指示器移动到offset文件中距离当前位置 字节的位置。
13.7目录操作
13.7.1迭代目录中的文件
与文件系统相关的最经典任务之一是能够迭代目录中的现有文件。要迭代目录中的文件,我们需要创建一个迭代器对象。
您可以使用对象的或 方法iterate()生成这样的迭代器对象。这两个方法都返回一个迭代器对象作为输出,您可以使用方法来推进它。这两个方法的区别在于,返回一个非递归迭代器,而返回一个非递归迭代器。这意味着 返回的迭代器不仅会迭代当前目录中可用的文件,还会迭代当前目录中任何子目录中的文件。walk()``Dir``next()``iterate()``walk()``walk()
在下面的示例中,我们显示了存储在目录 内的文件的名称ZigExamples/file-io。请注意,我们必须通过 函数打开此目录。另请注意,我们在 的第二个参数中openDir()提供了 标志。此标志很重要,因为如果没有此标志,我们将无法遍历此目录中的文件。iterate``openDir()
const cwd = std.fs.cwd();
const dir = try cwd.openDir(
"ZigExamples/file-io/",
.{ .iterate = true }
);
var it = dir.iterate();
while (try it.next()) |entry| {
try stdout.print(
"File name: {s}\n",
.{entry.name}
);
}
File name: create_file_and_write_toit.zig
File name: create_file.zig
File name: lorem.txt
File name: iterate.zig
File name: delete_file.zig
File name: append_to_file.zig
File name: user_input.zig
File name: foo.txt
File name: create_file_and_read.zig
File name: buff_io.zig
File name: copy_file.zig
13.7.2创建新目录
在创建目录时,有两个比较重要的方法: 和makeDir()。makePath()这两个方法的区别在于makeDir()每次调用只能在当前目录中创建一个目录,而makePath()可以在同一次调用中递归创建子目录。
这就是此方法名为“make path”的原因。它将根据需要创建尽可能多的子目录,以创建您输入的路径。因此,如果您将路径"sub1/sub2/sub3"作为此方法的输入,它将在同一函数调用中创建三个不同的子目录,分别sub1为 、sub2和sub3。相反,如果您将这样的路径作为 的输入makeDir(),则可能会出现错误,因为此方法只能创建一个子目录。
const cwd = std.fs.cwd();
try cwd.makeDir("src");
try cwd.makePath("src/decoders/jpg/");
13.7.3删除目录
要删除目录,只需将要删除的目录路径作为对象输入到deleteDir()方法中Dir即可。在下面的示例中,我们将删除上src一个示例中刚刚创建的目录。
const cwd = std.fs.cwd();
try cwd.deleteDir("src");
13.8结论
在本章中,我描述了如何在 Zig 中执行最常见的文件系统和 IO 操作。但您可能会觉得本章缺少一些其他不太常见的操作,例如:如何重命名文件,如何打开目录,如何创建符号链接,或者如何使用它来测试计算机中是否存在特定路径。但对于所有这些不太常见的任务,我建议您阅读类型14access()的文档,因为您可以在那里找到对这些情况的很好的描述。Dir
-
以前,这些对象被称为
Reader和Writer对象。↩︎ -
我们在第 7.4.1 节中创建的套接字对象是网络套接字的示例。↩︎
-
https://ziglang.org/documentation/master/std/#std.io.GenericWriter。↩︎
-
https://ziglang.org/documentation/master/std/#std.io.GenericReader。↩︎
-
https://github.com/ziglang/zig/blob/master/lib/std/io/Reader.zig。↩︎
-
https://github.com/ziglang/zig/blob/master/lib/std/io/Writer.zig。↩︎
-
管道是一种进程间通信(或称进程间 IO)的机制。你也可以将管道理解为“一组通过系统标准输入/输出设备链接在一起的进程”。例如,在 Linux 中,通过在终端内使用“管道”字符 (
|)连接两个或多个终端命令来创建管道。↩︎ -
https://ziglang.org/documentation/master/std/#std.fs.File.OpenFlags ↩︎
-
https://docs.python.org/3/tutorial/inputoutput.html#reading-and-writing-files ↩︎
-
https://www.tutorialspoint.com/c_standard_library/c_function_fopen.htm ↩︎