11 数据结构
在本章中,我想介绍 Zig 标准库中最常见的数据结构,尤其ArrayList是 和HashMap。这些是通用数据结构,可用于存储和控制应用程序生成的任何类型的数据。
11.1动态数组
在高级语言中,数组通常是动态的。它们的大小在必要时可以轻松增长,您无需为此担心。相比之下,低级语言中的数组通常默认是静态的。C、C++、Rust 以及 Zig 都是如此。静态数组在1.6 节中介绍过,但在本节中,我们将讨论 Zig 中的动态数组。
动态数组就是在程序运行时可以增长的数组。大多数低级语言在其标准库中都实现了动态数组。C++ 有std::vector,Rust 有Vec,Zig 也有std.ArrayList。
该std.ArrayList结构体为您提供了一个连续且可增长的数组。它像任何其他动态数组一样工作,它会分配一块连续的内存,当这块内存空间不足时,ArrayList它会分配另一个连续且更大的内存块,将元素复制到这个新位置,并擦除(或释放)前一块内存。
11.1.1容量与长度
当我们谈论动态数组时,我们通常会提到两个相似的概念,它们对于动态数组的底层工作原理至关重要。这两个概念是_容量_和_长度_。在某些情况下,尤其是在 C++ 中,长度_也称为_大小。
虽然它们看起来很相似,但在动态数组的上下文中,这些概念代表着不同的东西。_容量_是指动态数组当前可以容纳的项目(或元素)的数量,而无需分配更多内存。
相反,长度_指的是数组中当前正在使用的元素数量,或者换句话说,你已为该数组中分配了值的元素数量。每个动态数组都围绕一块已分配的内存运行,这块内存代表一个总容量为n元素。然而,只有其中一部分n元素大部分时间都在使用。这部分n是数组的_长度。因此,每次向数组添加新值时,其_长度_都会加1。
这意味着动态数组通常需要额外的空间,或者说是当前为空但等待使用的额外空间。这个“额外空间”本质上是_容量_和_长度_之间的差值。_容量_表示数组在无需重新分配或扩展的情况下可以容纳的元素总数,而_长度_表示当前有多少容量用于保存/存储值。
图 11.1直观地展示了这个想法。注意,一开始,数组的容量大于数组的长度。因此,动态数组虽然有额外的空间,但目前是空的,可以接收要存储的值。
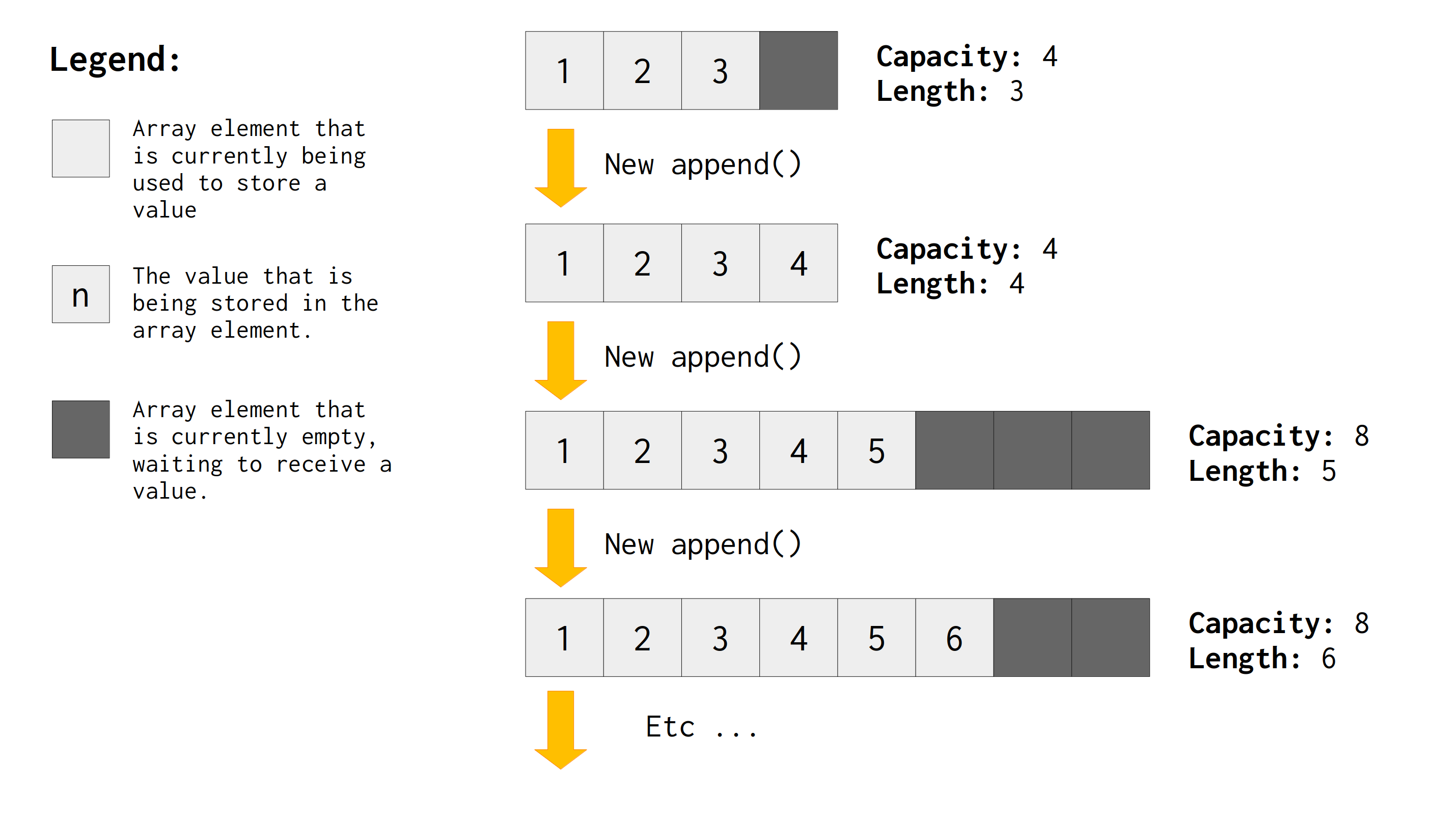
图 11.1:动态数组的容量和长度之间的差异
在图 11.1中我们还可以看到,当_长度_和_容量_相等时,意味着数组没有剩余空间。我们已经达到了容量上限,因此,如果我们想在这个数组中存储更多值,就需要扩展它。我们需要获得一个更大的空间,以容纳比当前更多的值。
动态数组的工作原理是,当长度_等于数组的_容量_时,扩展底层数组。它基本上会分配一个比前一个更大的新的连续内存块,然后将当前存储的所有值复制到这个新位置(即新的内存块),最后释放前一个内存块。在此过程结束时,新的底层数组具有更大的_容量,因此_长度_再次小于数组的_容量。_
这就是动态数组的循环。注意,在整个循环过程中,容量_始终等于或大于数组的_长度ArrayList。如果你有一个对象(假设你将其命名为),你可以通过访问该对象的属性buffer来检查数组的当前容量,同时该属性可以获取数组的当前_长度_。capacity``ArrayList``items.len
// Check capacity
buffer.capacity;
// Check length
buffer.items.len;
11.1.2创建ArrayList对象
要使用ArrayList,您必须为其提供一个分配器对象。请记住,Zig 没有默认的内存分配器。正如我在第 3.3 节中所述,所有内存分配都必须由您定义并可控制的分配器对象完成。在本例中,我将使用通用分配器,但您可以使用任何其他您喜欢的分配器。
初始化ArrayList对象时,必须提供数组元素的数据类型。换句话说,这定义了此数组(或容器)将存储的数据类型。因此,如果我指定了u8类型,那么我将创建一个动态u8值数组。但是,如果我提供一个自己定义的结构体,例如2.3 节User中的结构体,那么将创建一个动态值数组。在下面的示例中,我们使用表达式创建了一个动态值数组。User``ArrayList(u8)``u8
提供数组元素的数据类型后,您可以ArrayList使用init()或initCapacity()方法初始化对象。前一种方法仅接收分配器对象作为输入,而后一种方法同时接收分配器对象和容量数字作为输入。使用后一种方法,您不仅可以初始化结构体,还可以设置分配数组的起始容量。
使用此initCapacity()方法是初始化动态数组的首选方法。因为重新分配,或者换句话说,扩展数组容量的过程始终是一项高成本操作。您应该尽可能避免在数组中进行重新分配。如果您在开始时就知道数组需要占用多少空间,则应始终使用此方法initCapacity()来创建动态数组。
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var buffer = try std.ArrayList(u8)
.initCapacity(allocator, 100);
defer buffer.deinit();
在上面的例子中,buffer对象最初是一个包含 100 个元素的数组。如果此buffer对象在程序运行时需要创建更多空间来容纳更多元素,其ArrayList内部机制将自动执行必要的操作。另请注意,在当前作用域结束时,deinit()用于销毁对象的方法会释放为此对象中存储的动态数组分配的所有内存。buffer``buffer
11.1.3向数组添加新元素
现在我们已经创建了动态数组,可以开始使用它了。您可以使用append()方法向此数组附加(也称为“添加”)新值。此方法的工作方式append()与 Python 列表中的方法或C++emplace_back()中的方法相同std::vector。您向此方法提供一个值,该方法会将此值附加到数组中。
您还可以使用此appendSlice()方法一次附加多个值。您需要向此方法提供一个切片(切片已在1.6 节中描述),该方法会将此切片中存在的所有值添加到您的动态数组中。
try buffer.append('H');
try buffer.append('e');
try buffer.append('l');
try buffer.append('l');
try buffer.append('o');
try buffer.appendSlice(" World!");
11.1.4从数组中删除元素
你可以使用该pop()方法“弹出”或移除数组中的最后一个元素。值得注意的是,此方法不会改变数组的容量。它只是删除或擦除数组中存储的最后一个值。
此外,此方法还会返回被删除的值。也就是说,您可以使用此方法获取数组中的最后一个值,也可以将其从数组中删除。这是一种“获取并删除值”类型的方法。
const exclamation_mark = buffer.pop();
现在,如果您想从数组的特定位置删除特定元素,可以使用对象orderedRemove()中的方法ArrayList。使用此方法,您可以提供一个索引作为输入,然后该方法将删除数组中此索引处的值。每次执行操作时,您都可以有效地减少数组的_长度_orderedRemove()。
在下面的示例中,我们首先创建一个ArrayList对象,并用数字填充它。然后,我们orderedRemove()连续两次使用 删除数组中索引 3 处的值。
另外,请注意,我们将 的结果赋值orderedRemove()给了下划线字符。因此,我们丢弃了此方法的结果值。该orderedRemove()方法将以与 类似的方式返回被删除的值pop()。
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var buffer = try std.ArrayList(u8)
.initCapacity(allocator, 100);
defer buffer.deinit();
for (0..10) |i| {
const index: u8 = @intCast(i);
try buffer.append(index);
}
std.debug.print(
"{any}\n", .{buffer.items}
);
_ = buffer.orderedRemove(3);
_ = buffer.orderedRemove(3);
std.debug.print("{any}\n", .{buffer.items});
std.debug.print("{any}\n", .{buffer.items.len});
{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }
{ 0, 1, 2, 5, 6, 7, 8, 9 }
8
它的一个关键特性orderedRemove()是保留数组中值的顺序。因此,它会删除你要求移除的值,但同时确保数组中剩余值的顺序与之前保持一致。
现在,如果您不关心值的顺序,例如,您可能想将动态数组视为一组值,就像std::unordered_setC++ 中的结构体一样,swapRemove()那么您可以使用 方法。此方法的工作原理与 方法类似orderedRemove()。您为此方法指定一个索引,然后它会删除数组中位于此索引处的值。但此方法不会保留数组中剩余值的原始顺序。因此,swapRemove()通常比 更快orderedRemove()。
11.1.5在特定索引处插入元素
当您需要在数组中间插入值,而不是仅将它们附加到数组末尾时,您需要使用insert()和insertSlice()方法,而不是append()和appendSlice()方法。
这两个方法的工作原理与 C++ 类非常相似insert()。insert_range()你std::vector为这些方法提供一个索引,它们会将你提供的值插入到数组中该索引处。
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var buffer = try std.ArrayList(u8)
.initCapacity(allocator, 10);
defer buffer.deinit();
try buffer.appendSlice("My Pedro");
try buffer.insert(4, '3');
try buffer.insertSlice(2, " name");
for (buffer.items) |char| {
try stdout.print("{c}", .{char});
}
My name P3edro
11.1.6结论
如果您觉得缺少其他方法,我建议您阅读1结构的官方文档ArrayListAligned,其中描述了可通过对象使用的大多数方法。ArrayList
您会注意到此页面中还有许多其他方法我没有在这里描述,我建议您探索这些方法,并了解它们的工作原理。
11.2映射或哈希表
一些专业人士用不同的术语来理解这种数据结构,例如“map”、“hashmap”或“关联数组”。但最常用的术语是_哈希表 (hashtable)_。每种编程语言的标准库中通常都有哈希表的实现。Python 有dict(),C++ 有std::map和std::unordered_map,Rust 有HashMap,JavaScript 有Object()和Map(),等等。
11.2.1什么是哈希表?
哈希表是一种基于键值对的数据结构。你向该结构提供一个键和一个值,然后哈希表会将输入值存储在一个可以通过你提供的输入键识别的位置。它通过使用底层数组和哈希函数来实现这一点。这两个组件对于哈希表的工作原理至关重要。
哈希表的底层包含一个数组。这个数组用于存储值,其元素通常被称为_buckets_。因此,你提供给哈希表的值存储在 buckets 中,你可以通过索引访问每个 buckets。
当你为哈希表提供一个键时,它会将该键传递给哈希函数。哈希函数使用某种哈希算法将该键转换为索引。该索引实际上是一个数组索引,它是哈希表底层数组中的一个位置。这就是键在哈希表结构中标识特定位置(或地点)的方式。
因此,您需要向哈希表提供一个键,该键标识哈希表中的特定位置。然后,哈希表会获取您提供的输入值,并将该值存储在由该输入键标识的位置。您可以说,该键映射到哈希表中存储的值。您可以使用标识值存储位置的键来查找该值。图 11.2直观地展示了这个过程。

图 11.2:哈希表示意图。来源:维基百科,自由的百科全书。
上一段描述的操作通常称为_插入_操作,因为你正在将新值插入哈希表中。但是哈希表中还有其他类型的操作,例如_删除_和_查找_。删除操作是自描述的,它是指从哈希表中删除(或移除)一个值。而查找操作是指通过使用标识该值存储位置的键来查找存储在哈希表中的值。
有时,哈希表的底层数组不是直接存储值,而是指针数组,也就是说,数组的 buckets 存储指向值的指针,或者也可能是一个链表数组。这些情况在允许重复键的哈希表中很常见,或者换句话说,在能够有效处理哈希函数可能产生的“冲突”的哈希表中很常见。
重复键,或者我所说的“冲突”,是指两个不同的键指向哈希表底层数组中的同一位置(即同一索引)。这种情况的发生取决于哈希表中使用的哈希函数的特性。一些哈希表的实现会主动处理冲突,这意味着它们会以某种方式处理这种情况。例如,哈希表可能会将所有存储桶转换为链表。因为使用链表,您可以将多个值存储到一个存储桶中。
处理哈希表中的冲突有多种技术,本书不会详细介绍,因为这不是我们的主要讨论范围。不过,你可以在维基百科的哈希表页面(维基百科 2024)上找到一些最常见技术的详细描述。
11.2.2 Zig 中的哈希表
Zig 标准库提供了哈希表的不同实现。每种实现都有其优缺点,我们将在后面讨论,所有这些实现都可以通过该std.hash_map模块获得。
该HashMap结构体是一个通用的哈希表,它具有非常快的操作(查找、插入、删除),并且内存占用低,负载因子也很高。您可以创建一个上下文对象并将其提供给HashMap构造函数。此上下文对象允许您定制哈希表本身的行为,因为您可以通过此上下文对象提供哈希函数的实现供哈希表使用。
但现在我们先不用担心这个 context 对象,因为它是专门给“哈希表领域的专家”用的。既然我们很可能不是这个领域的专家,我们就用最简单的方法来创建哈希表。那就是使用AutoHashMap()函数。
此AutoHashMap()函数本质上是一个“使用默认设置创建哈希表对象”类型的函数。它会自动选择一个上下文对象,从而为您选择一个哈希函数实现。此函数接收两种数据类型作为输入:第一个输入是此哈希表将使用的键的数据类型,第二个输入是将存储在哈希表中的数据的数据类型,即要存储的值的数据类型。
在下面的示例中,我们u32在该函数的第一个参数和u16第二个参数中提供了数据类型。这意味着我们将使用u32值作为此哈希表中的键,而u16值是将要存储到此哈希表中的实际值。在此过程结束时,该hash_table对象包含一个HashMap使用默认设置和上下文的对象。
const std = @import("std");
const AutoHashMap = std.hash_map.AutoHashMap;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var hash_table = AutoHashMap(u32, u16).init(allocator);
defer hash_table.deinit();
try hash_table.put(54321, 89);
try hash_table.put(50050, 55);
try hash_table.put(57709, 41);
std.debug.print(
"N of values stored: {d}\n",
.{hash_table.count()}
);
std.debug.print(
"Value at key 50050: {d}\n",
.{hash_table.get(50050).?}
);
if (hash_table.remove(57709)) {
std.debug.print(
"Value at key 57709 successfully removed!\n",
.{}
);
}
std.debug.print(
"N of values stored: {d}\n",
.{hash_table.count()}
);
}
N of values stored: 3
Value at key 50050: 55
Value at key 57709 successfully removed!
N of values stored: 2
您可以使用该方法向哈希表中添加/放入新值put()。第一个参数是要使用的键,第二个参数是要存储在哈希表中的实际值。在下面的示例中,我们首先使用键 54321 添加值 89,然后使用键 50050 添加值 55,依此类推。
注意,我们之前使用了 方法count()来查看哈希表中当前存储了多少个值。之后,我们还使用get()方法来访问(或查看)键 500050 所标识位置处存储的值。该get()方法的输出是一个可选值。这就是为什么我们?在最后使用 方法来获取实际值。
还要注意,我们可以使用此方法从哈希表中移除(或删除)值remove()。你提供标识要删除的值的键,然后该方法将删除该值并返回一个true值作为输出。这个true值实际上告诉我们该方法已成功删除该值。
但是这个删除操作可能并不总是成功。例如,你可能为这个方法提供了错误的键。我的意思是,你可能(有意或无意地)提供了一个指向空存储桶(即存储桶中还没有值)的键。在这种情况下,该remove()方法会返回一个false值。
11.2.3遍历哈希表
遍历当前存储在哈希表中的键和值是非常常见的需求。在 Zig 中,您可以使用迭代器对象来实现这一点,该对象可以遍历哈希表对象的元素。
这个迭代器对象的工作方式与 C++ 和 Rust 等语言中的其他迭代器对象类似。它本质上是一个指向容器中某个值的指针对象,并且拥有一个next()可用于浏览(或迭代)容器中值的方法。
iterator()您可以使用哈希表对象的方法创建这样的迭代器对象。此方法返回一个迭代器对象,您可以将该next()方法与 while 循环结合使用,从而遍历哈希表的元素。该next()方法返回一个可选Entry值,因此,您必须解开此可选值的包装才能获取实际Entry值,从而可以访问键以及由该键标识的值。
有了这个值,你就可以通过使用该属性并取消引用其中的指针Entry来访问当前条目的键;而通过该属性访问由该键标识的值,该属性也是一个需要取消引用的指针。以下代码示例演示了这些元素的用法:key_ptr``value_ptr
const std = @import("std");
const AutoHashMap = std.hash_map.AutoHashMap;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var hash_table = AutoHashMap(u32, u16).init(allocator);
defer hash_table.deinit();
try hash_table.put(54321, 89);
try hash_table.put(50050, 55);
try hash_table.put(57709, 41);
var it = hash_table.iterator();
while (it.next()) |kv| {
// Access the current key
std.debug.print("Key: {d} | ", .{kv.key_ptr.*});
// Access the current value
std.debug.print("Value: {d}\n", .{kv.value_ptr.*});
}
}
Key: 54321 | Value: 89
Key: 50050 | Value: 55
Key: 57709 | Value: 41
如果你想要专门迭代哈希表的值或键,可以创建一个键迭代器或值迭代器对象。它们也是迭代器对象,并且拥有与next()迭代哈希表相同的方法。
键迭代器由哈希表对象的方法创建keyIterator(),而值迭代器则由该方法创建valueIterator()。您只需从next()方法中解包值,并直接引用它即可访问要迭代的键或值。以下代码示例演示了键迭代器的用法,但您可以将相同的逻辑复制到值迭代器中。
var kit = hash_table.keyIterator();
while (kit.next()) |key| {
std.debug.print("Key: {d}\n", .{key.*});
}
Key: 54321
Key: 50050
Key: 57709
11.2.4ArrayHashMap哈希表
如果您需要不断地遍历哈希表的元素,您可能需要ArrayHashMap针对您的具体情况使用结构体,而不是使用通常的通用HashMap结构体。
该ArrayHashMap结构体会创建一个迭代速度更快的哈希表。这就是为什么这种特定类型的哈希表可能对你很有价值。ArrayHashMap哈希表的其他一些属性包括:
- 插入顺序被保留,即,在遍历此哈希表时找到的值的顺序实际上是这些值插入哈希表的顺序。
- 键值对按顺序一个接一个地存储。
您可以使用一个辅助函数来创建ArrayHashMap对象,该函数会自动为您选择一个哈希函数实现。该函数的工作原理与我们在11.2.2 节AutoArrayHashMap()中介绍的函数非常相似。AutoHashMap()
你为这个函数提供了两种数据类型:一个是将用于哈希表的键的数据类型,另一个是将存储在哈希表中的值的数据类型。
对象ArrayHashMap本质上拥有与结构体完全相同的方法HashMap。因此,您可以使用该方法向哈希表中插入新值put(),也可以使用该方法从哈希表中查找(或获取)值get()。但是,该remove()方法在这种特定类型的哈希表中不可用。
要从哈希表中删除值,可以使用与对象ArrayList(即动态数组)中相同的方法。我在11.1.4 节中介绍了这些方法,即swapRemove()和orderedRemove()方法。这些方法在这里的含义相同,或者说,它们的作用与它们在对象中相同ArrayList。
这意味着,当swapRemove()你从哈希表中删除值时,你不会保留值插入到结构中的顺序。而orderedRemove()可以保留这些值的插入顺序。
但是,与我在11.1.4 节中描述的一样,这里的方法不是将索引作为swapRemove()或 的输入,而是像对象中的方法一样,将键作为输入。如果您想提供索引而不是键作为输入,则应该使用和方法。orderedRemove()ArrayHashMap``remove()``HashMap``swapRemoveAt()``orderedRemoveAt()
var hash_table = AutoArrayHashMap(u32, u16)
.init(allocator);
defer hash_table.deinit();
11.2.5StringHashMap哈希表
你会注意到,在上一节中我介绍的另外两种类型的哈希表中,它们的键都不接受切片数据类型。这意味着你不能在这些类型的哈希表中使用切片值来表示键。
最明显的后果是,你不能在这些哈希表中使用字符串作为键。但在哈希表中使用字符串作为键是非常常见的。
以这段非常简单的 Javascript 代码片段为例。我们创建一个名为 的简单哈希表对象people。然后,我们向此哈希表添加一个新条目,该条目由字符串 标识'Pedro'。在本例中,此字符串是键,而包含年龄、身高和城市等不同个人信息的对象是要存储在哈希表中的值。
var people = new Object();
people['Pedro'] = {
'age': 25,
'height': 1.67,
'city': 'Belo Horizonte'
};
这种使用字符串作为键的模式在各种情况下都很常见。因此,Zig 标准库为此提供了一种特定类型的哈希表,该哈希表是通过该StringHashMap()函数创建的。该函数创建一个使用字符串作为键的哈希表。该函数的唯一输入是将存储在此哈希表中的值的数据类型。
在下面的例子中,我创建了一个哈希表来存储不同人的年龄。哈希表中的每个键都由每个人的姓名表示,而哈希表中存储的值则是该键所标识的人的年龄。
这就是为什么我将u8数据类型(即年龄值所使用的数据类型)作为此StringHashMap()函数的输入。结果,它创建一个使用字符串值作为键并在其中存储值的哈希表。请注意,函数返回的对象的方法u8中提供了一个分配器对象。init()``StringHashMap()
const std = @import("std");
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var ages = std.StringHashMap(u8).init(allocator);
defer ages.deinit();
try ages.put("Pedro", 25);
try ages.put("Matheus", 21);
try ages.put("Abgail", 42);
var it = ages.iterator();
while (it.next()) |kv| {
std.debug.print("Key: {s} | ", .{kv.key_ptr.*});
std.debug.print("Age: {d}\n", .{kv.value_ptr.*});
}
}
Key: Pedro | Age: 25
Key: Abgail | Age: 42
Key: Matheus | Age: 21
11.2.6StringArrayHashMap哈希表
StringHashMapZig 标准库还提供了一种哈希表,它兼具了和的优缺点ArrayHashMap。也就是说,它既使用字符串作为键,又兼具 的优点ArrayHashMap。换句话说,你可以拥有一个哈希表,它可以快速迭代,保留插入顺序,并且使用字符串作为键。
你可以使用函数创建此类哈希表StringArrayHashMap()。该函数接受一个数据类型作为输入,该数据类型是将要存储在此哈希表中的值的数据类型,其样式与11.2.5 节中介绍的函数相同。
您可以使用我们在11.2.5 节put()中讨论过的相同方法向此哈希表中插入新值。您也可以使用相同的方法从哈希表中获取值。与其兄弟类似,要从这种特定类型的哈希表中删除值,我们也可以使用和方法,其效果与我在11.2.4 节中描述的相同。get()``ArrayHashMap``orderedRemove()``swapRemove()
如果我们采用第 11.2.5 节中展示的代码示例,我们可以用以下命令实现完全相同的结果StringArrayHashMap():
var ages = std.StringArrayHashMap(u8).init(allocator);
11.3链表
Zig 标准库提供了单链表和双链表的实现。链表是一种线性数据结构,看起来像一条链,或者一根绳子。这种数据结构的主要优点是插入和删除操作通常非常快。但是,缺点是,迭代这种数据结构通常不如迭代数组快。
链表的理念是构建一个由一系列通过指针相互连接的节点组成的结构。这意味着链表在内存中通常不是连续的,因为每个节点可能位于内存中的任何位置。它们不需要彼此靠近。
在图 11.3中,我们可以看到一个单链表的示意图。我们从第一个节点(通常称为“链表的头”)开始。然后,从这个第一个节点开始,沿着每个节点的指针指向的位置,找到结构中的其余节点。
每个节点包含两个内容:一个是存储在当前节点的值,另一个是指向链表下一个节点的指针。如果该指针为空,则表示我们已到达链表的末尾。
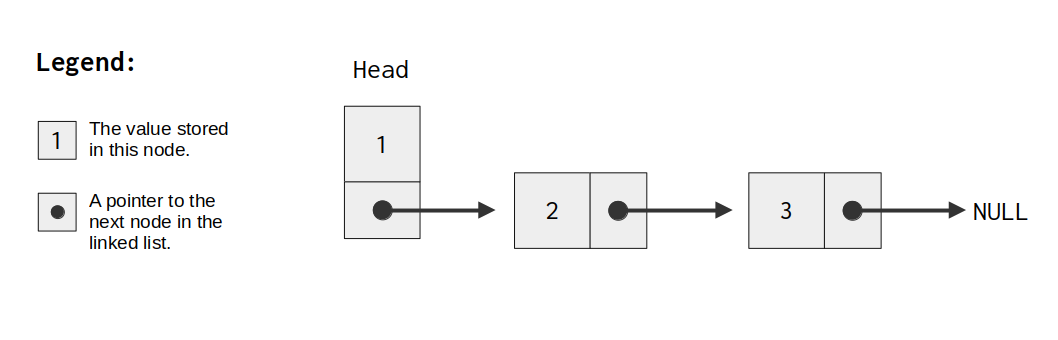
图 11.3:单链表的图表。
在图 11.4中,我们可以看到一个双向链表的示意图。现在唯一真正改变的是,链表中的每个节点都有一个指向前一个节点的指针和一个指向下一个节点的指针。因此,双向链表中的每个节点都有两个指针。它们通常被称为节点的prev(表示“上一个”)指针和(表示“下一个”)指针。next
在单链表的例子中,每个节点只有一个指针,并且这个指针始终指向序列中的下一个节点。这意味着单链表通常只有一个next指针。
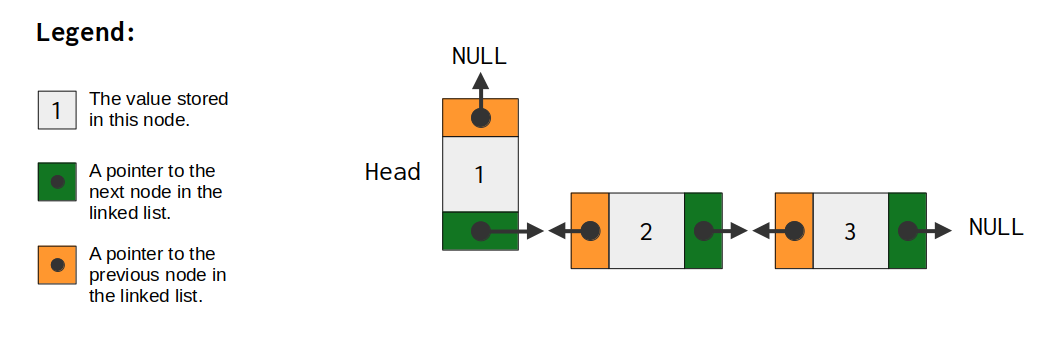
图 11.4:双向链表的图表。
在 Zig 中,链表可通过函数SinglyLinkedList()和使用,分别表示“单链表”和“双链表”。这些函数实际上是通用函数,我们将在12.2.1 节DoublyLinkedList()中详细讨论。
现在,只需理解,为了创建链表对象,我们首先要为这些函数提供一个数据类型。该数据类型定义了链表中每个节点将存储的数据类型。在下面的示例中,我们将创建一个单链表u32。因此,链表中的每个节点都将存储一个u32值。
SinglyLinkedList()和函数都DoublyLinkedList()返回一个类型,即一个结构体定义。因此,该对象Lu32实际上是一个结构体定义。它定义了“单链表”类型u32。
现在我们有了结构体的定义,我们需要实例化一个Lu32对象。在 Zig 中,我们通常使用init()方法实例化结构体对象。但在本例中,我们直接struct在表达式中使用空字面量来实例化结构体Lu32{}。
prepend()在这个例子中,我们首先创建多个节点对象,创建完成后,我们使用和方法插入并连接这些节点来构建链表insertAfter()。注意,prepend()方法是链表对象中的方法,而insertAfter()是节点对象中的方法。
本质上,该prepend()方法会在链表的开头插入一个节点。换句话说,你提供给此方法的节点将成为链表的新“头节点”。它将成为链表的第一个节点(参见图 11.3)。
另一方面,该insertAfter()方法主要用于将两个节点连接在一起。当你向此方法传入一个节点时,它会创建一个指向该输入节点的指针,并将该指针存储在next调用该方法的当前节点的属性中。
因为双向链表的每个节点都有 anext和 a属性(如图 11.4prev所示),所以从对象创建的节点对象同时具有 an (for ) 和 an (for ) 方法可用。DoublyLinkedList``insertBefore()``prev``insertAfter()``next
因此,如果我们使用了双向链表,我们可以用该insertBefore()方法将指向输入节点的指针存储在prev属性中。这会将输入节点设置为“上一个节点”,即当前节点之前的节点。相反,该insertAfter()方法将指向输入节点的指针存储在next当前节点的属性中,结果,输入节点成为当前节点的“下一个节点”。
由于我们在此示例中使用单链表,因此我们只能insertAfter()在从我们的类型创建的节点对象中使用该方法Lu32。
const std = @import("std");
const SinglyLinkedList = std.SinglyLinkedList;
const Lu32 = SinglyLinkedList(u32);
pub fn main() !void {
var list = Lu32{};
var one = Lu32.Node{ .data = 1 };
var two = Lu32.Node{ .data = 2 };
var three = Lu32.Node{ .data = 3 };
var four = Lu32.Node{ .data = 4 };
var five = Lu32.Node{ .data = 5 };
list.prepend(&two); // {2}
two.insertAfter(&five); // {2, 5}
list.prepend(&one); // {1, 2, 5}
two.insertAfter(&three); // {1, 2, 3, 5}
three.insertAfter(&four); // {1, 2, 3, 4, 5}
}
链表对象还提供了其他方法,具体取决于该对象是单链表还是双链表,这些方法可能对您非常有用。您可以在以下要点中找到这些方法的摘要:
remove()从链接列表中删除特定节点。- 如果是单链表,
len()则计算链表中有多少个节点。 - 如果是双向链表,检查
len属性以查看链表中有多少个节点。 - 如果是单链表,
popFirst()则从链表中删除第一个节点(即“头”)。 - 如果是双向链表,
pop()则popFirst()分别从链表中删除最后一个节点和第一个节点。 - 如果是双向链表,
append()则将新节点添加到链表的末尾(即的逆prepend())。
11.4多数组结构
Zig 引入了一种名为 的新数据结构。它是我们在第 11.1 节MultiArrayList()中介绍的动态数组的不同版本。此结构与我们从第 11.1 节中了解的的区别在于,它会为您作为输入提供的结构体的每个字段创建一个单独的动态数组。ArrayList()MultiArrayList()
请考虑以下代码示例。我们创建一个名为 的新自定义结构体Person。此结构体包含三个不同的数据成员,或者说三个不同的字段。因此,当我们将此Person数据类型作为 的输入时MultiArrayList(),这将创建一个名为 的“包含三个不同数组的结构体” PersonArray。换句话说,这PersonArray是一个包含三个内部动态数组的结构体。结构体定义中的每个字段对应一个数组Person。
const std = @import("std");
const Person = struct {
name: []const u8,
age: u8,
height: f32,
};
const PersonArray = std.MultiArrayList(Person);
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var people = PersonArray{};
defer people.deinit(allocator);
try people.append(allocator, .{
.name = "Auguste", .age = 15, .height = 1.54
});
try people.append(allocator, .{
.name = "Elena", .age = 26, .height = 1.65
});
try people.append(allocator, .{
.name = "Michael", .age = 64, .height = 1.87
});
}
换句话说,该MultiArrayList()函数不是创建一个“persons”数组,而是创建一个“数组结构体”。该结构体的每个数据成员都是一个不同的数组,用于存储特定字段的值,这些Person值来自被添加(或追加)到这个“数组结构体”的值。一个重要的细节是,每个存储在内部的独立数组PersonArray都是动态数组。这意味着这些数组可以根据需要自动增加容量,以容纳更多值。
下面的图 11.5展示了我们在上一个代码示例中创建的结构体的示意图。请注意,我们添加到对象的PersonArray三个值中,其数据成员的值分散在对象的三个不同的内部数组中。Person``PersonArray``PersonArray

图 11.5:结构图PersonArray。
您可以轻松地分别访问每个数组,并迭代每个数组的值。为此,您需要items()从PersonArray对象中调用该方法,并将要迭代的字段名称作为此方法的输入。.age例如,如果您要迭代数组,则需要items(.age)从PersonArray对象中调用,如下例所示:
for (people.items(.age)) |*age| {
try stdout.print("Age: {d}\n", .{age.*});
}
Age: 15
Age: 26
Age: 64
在上面的例子中,我们正在迭代数组的值,或者,迭代包含从添加到多数组结构的值的数据成员的值的对象.age的内部数组。PersonArray``age``Person
items()在此示例中,我们直接从对象调用该方法PersonArray。但是,大多数情况下,建议items()从“切片对象”调用此方法,该对象可以通过该slice()方法创建。这样做的原因是,items()使用切片对象可以提高多次调用的性能。
因此,如果您打算只访问“多数组结构体”中的一个内部数组,那么items()直接从多数组对象调用即可。但是,如果您需要访问“多数组结构体”中的多个内部数组,则可能需要items()多次调用,在这种情况下,最好items()通过切片对象调用。以下示例演示了此类对象的用法:
var slice = people.slice();
for (slice.items(.age)) |*age| {
age.* += 10;
}
for (slice.items(.name), slice.items(.age)) |*n,*a| {
try stdout.print(
"Name: {s}, Age: {d}\n", .{n.*, a.*}
);
}
Name: Auguste, Age: 25
Name: Elena, Age: 36
Name: Michael, Age: 74
11.5结论
还有许多其他数据结构我没有在这里介绍。但您可以在官方 Zig 标准库文档页面上查看它们。实际上,当您进入文档2的主页时,此页面中首先呈现给您的是 Zig 标准库中可用的类型和数据结构的列表。此列表中有一些非常具体的数据结构,例如BoundedArraystruct 3,但也有一些更通用的结构,例如PriorityQueuestruct 4。